热门
几款主流好用的markdown编辑器介绍
如何系统地自学python?
Redis基础命令集详解
数据库的介绍、分类、作用和特点
服务器硬件基础知识
golang和java对比
【网络连接】ping不通的常见原因+解决方案,如何在只能访问网关时诊断,并修复IP不通的问题
Java中文乱码浅析解决方案
chrome安装vue插件 vue-devtools
如何在Windows上使用Docker,搭建一款实用的个人IT工具箱It- Tools
Spring Boot 单元测试 0基础教程
2024-03-27 16:24:05.811 ERROR [nio-9603-exec-2] c.t.t.handler.GlobalExceptionHandler
Yarn安装与使用
【好书推荐1】基于React低代码平台开发:构建高效、灵活的应用新范式
Tomcat启动后快速闪退解决方法
PolarDB安装体验
Tomcat启动闪退问题解决方法
如何使用宝塔面板部署MySQL数据库,并结合内网穿透实现固定公网地址远程连接
Sql中如何添加数据
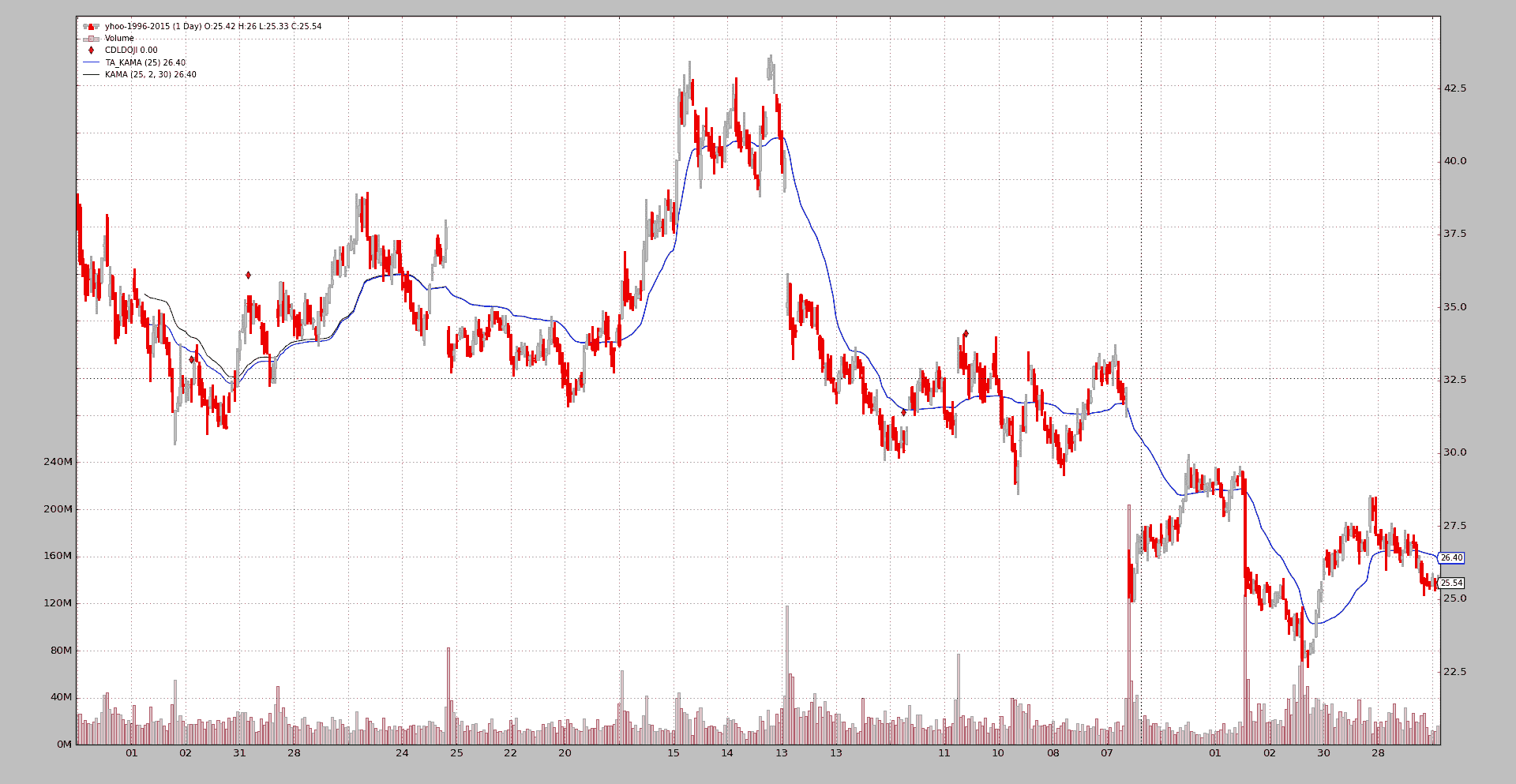
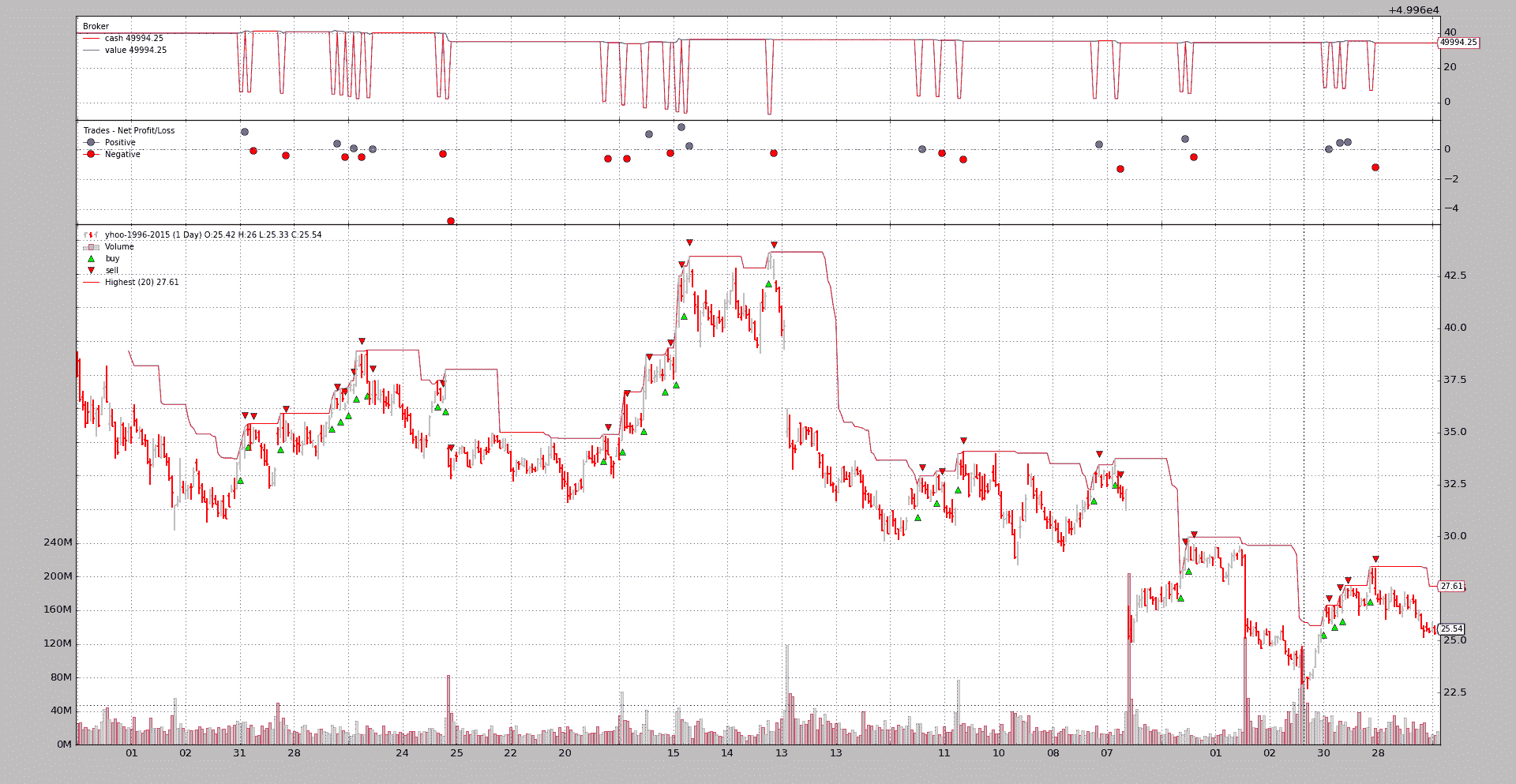
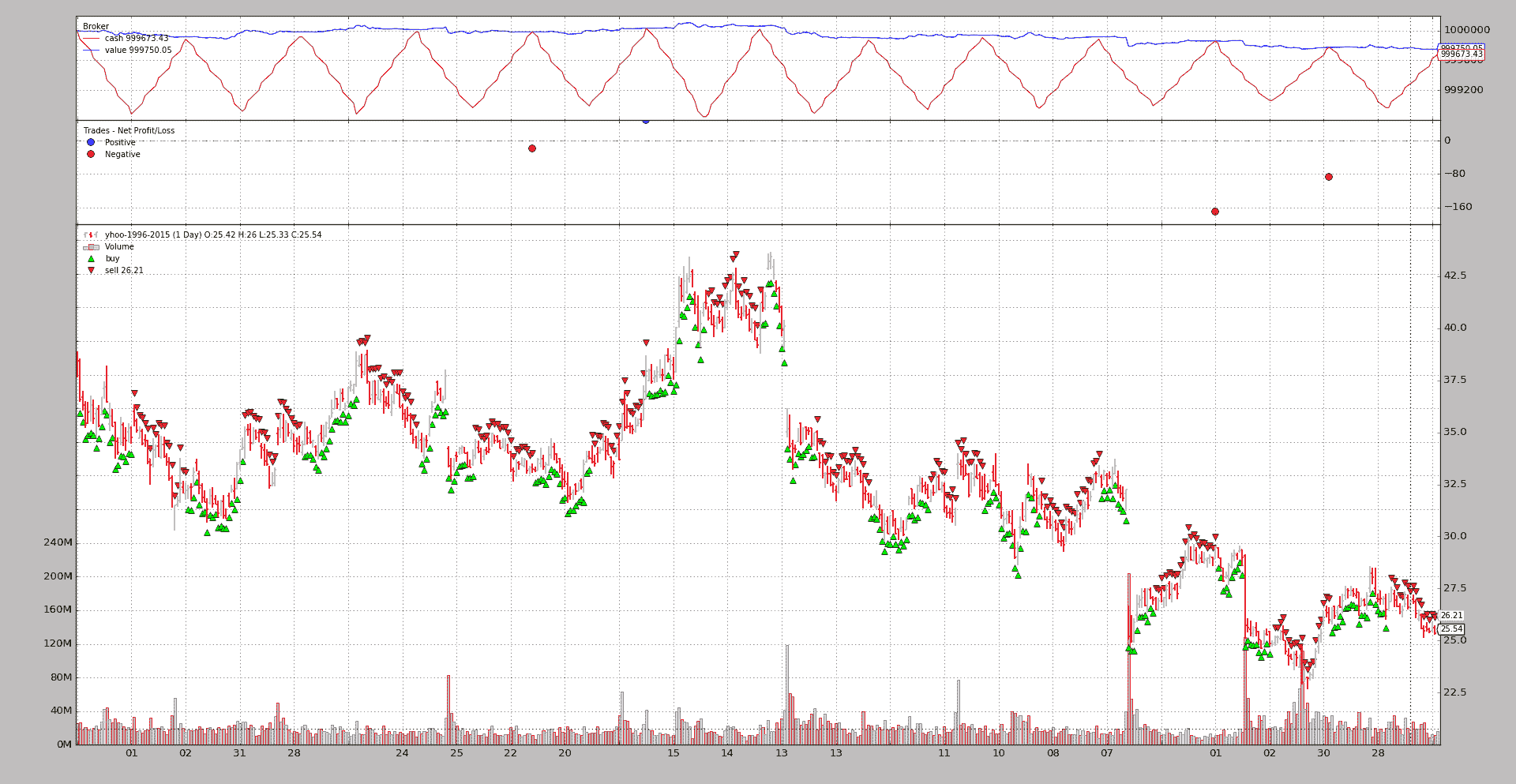
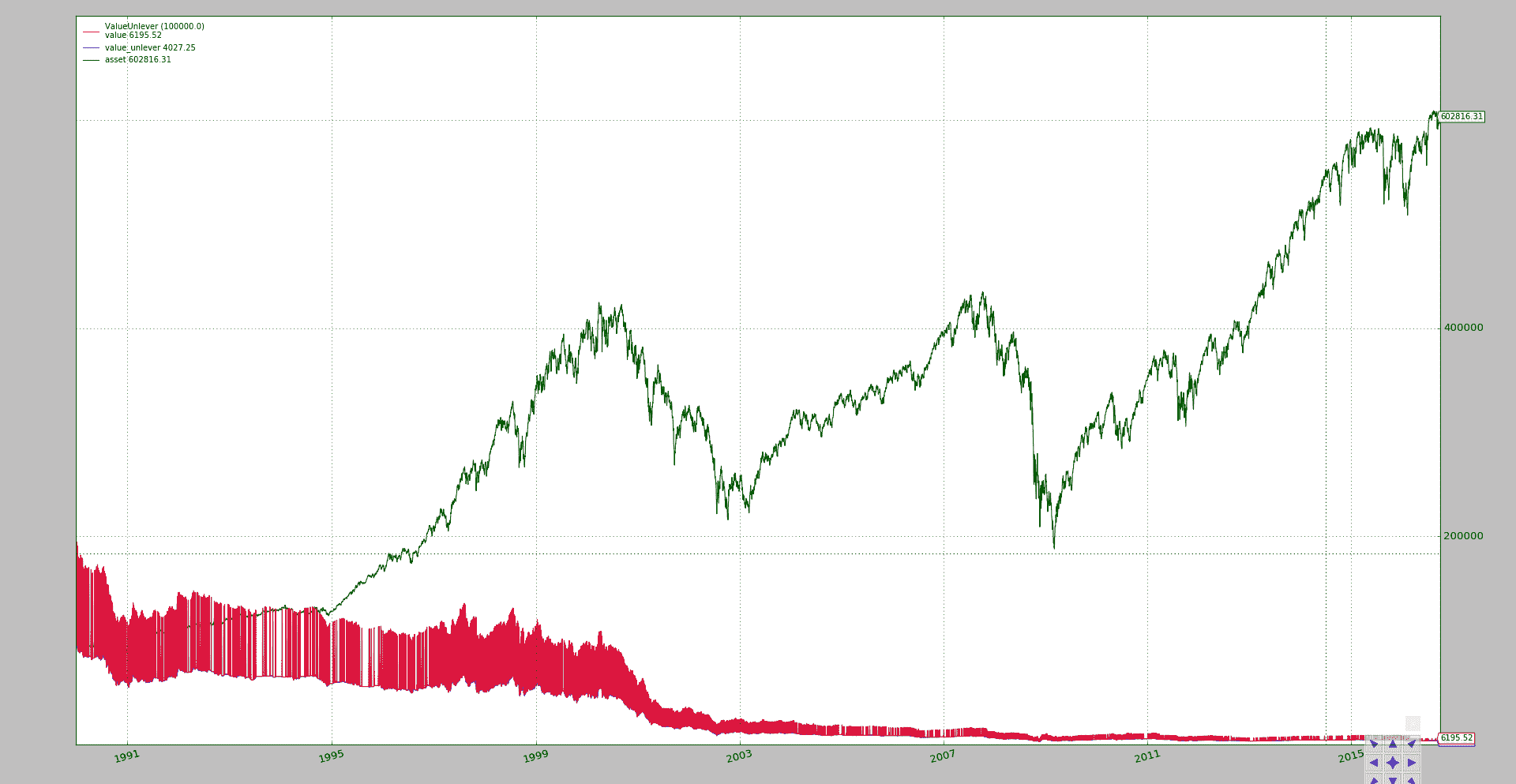
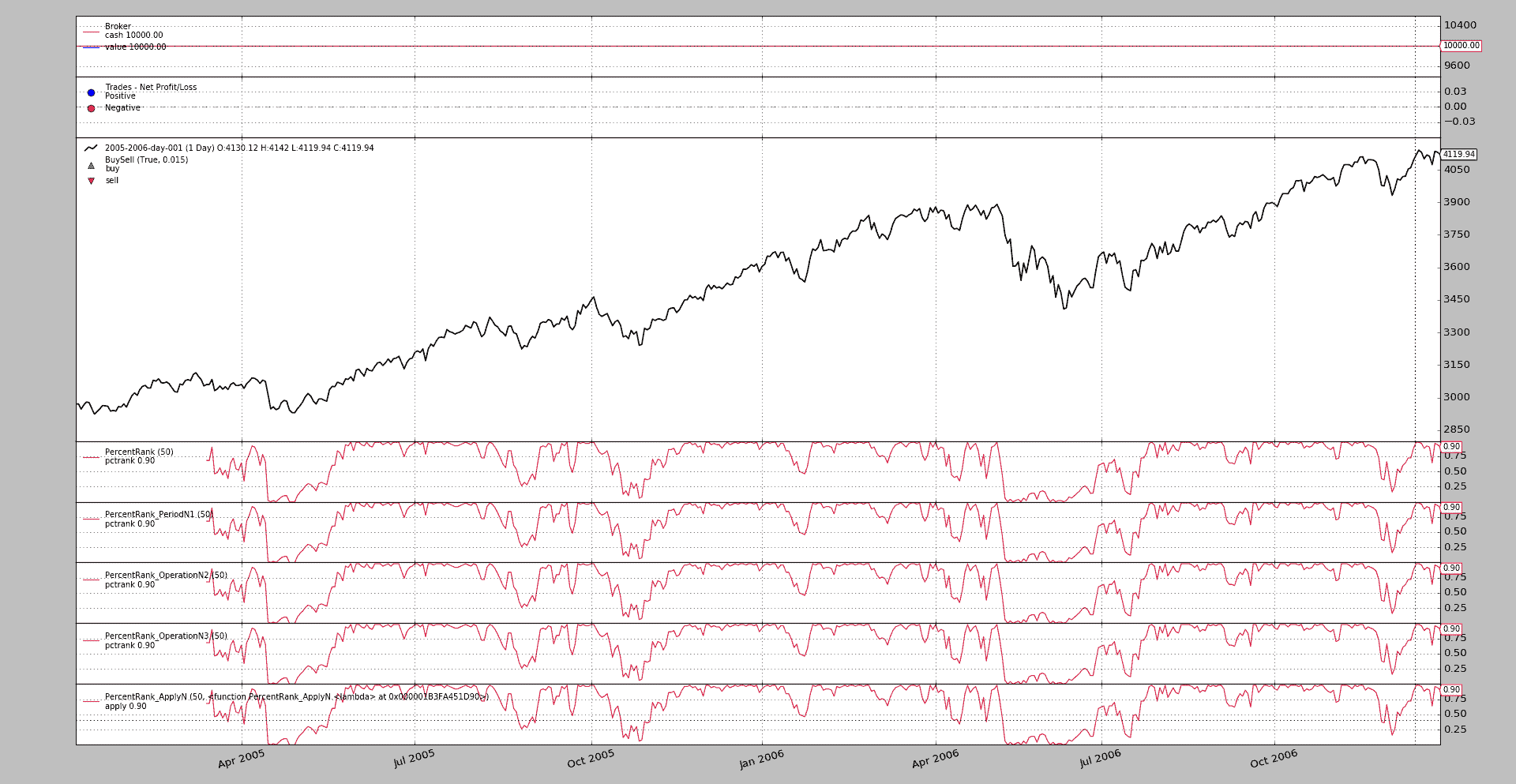
BackTrader 中文文档(二十二)(3)
Spring框架与Spring Boot的区别和联系
BackTrader 中文文档(二十二)(2)
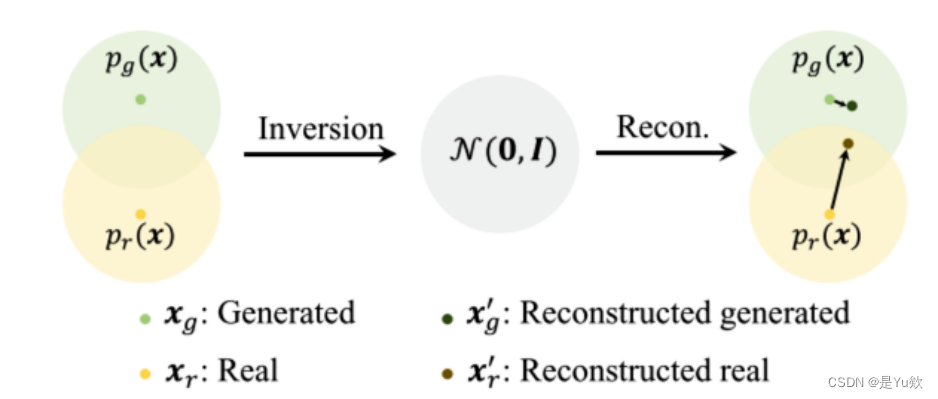
【视觉AIGC识别】误差特征、人脸伪造检测、其他类型假图检测
BackTrader 中文文档(二十二)(1)
04|零基础玩转面向对象编程:Java OOP
03|Java基础语法:讲解标识符、关键字、变量、数据类型、运算符、控制语句(条件分支、循环)
Ecmascript 和javascript的区别
Node.js新手必备:超实用命令行入门教程
BackTrader 中文文档(二十一)(4)
BackTrader 中文文档(二十一)(3)
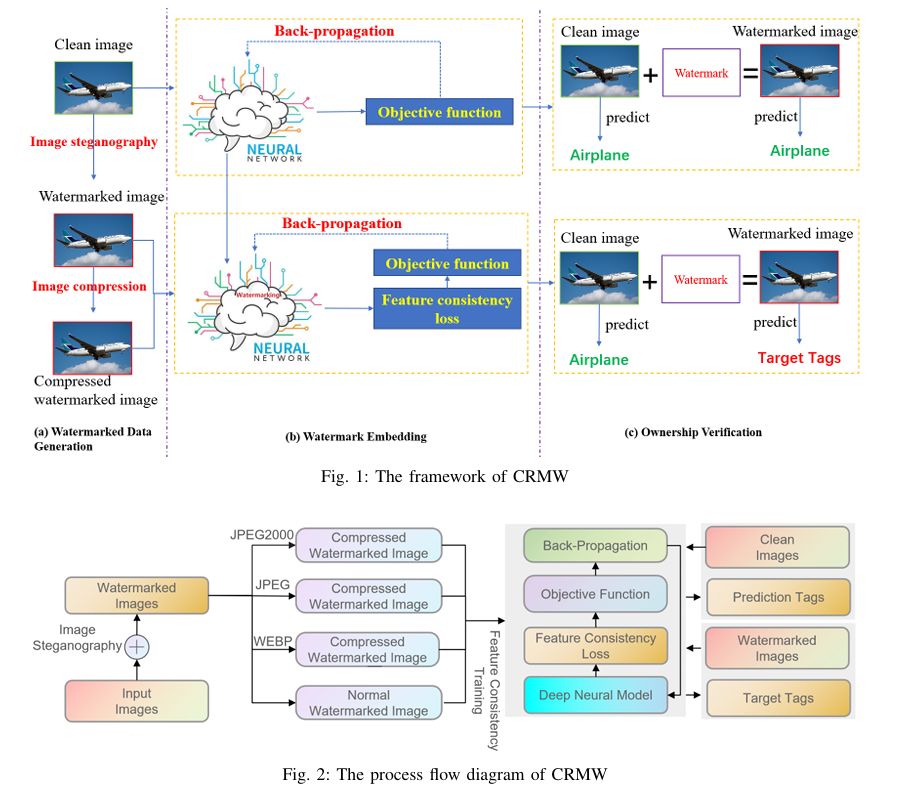
【图像版权】论文阅读:CRMW 图像隐写术+压缩算法
BackTrader 中文文档(二十一)(2)
BackTrader 中文文档(二十一)(1)
面向对象编程:类、对象、继承与多态
Java新手导航:一文掌握流程控制
一文速览深度伪造检测(Detection of Deepfakes):未来技术的守门人
BackTrader 中文文档(十九)(4)
探索Java世界的奇妙工具——运算符与表达式运算符
BackTrader 中文文档(十九)(3)
BackTrader 中文文档(十九)(2)
BackTrader 中文文档(十九)(1)
深入浅出Java基础语法:标识符、关键字、变量、数据类型、运算符与控制语句
Java一分钟之-Java IO流:文件读写基础
如何在Win系统从零开始搭建Z-blog网站,并将本地博客发布到公网可访问
轻松理解Java中的数据类型和变量
ERROR [ntContainer#0-1] o.s.a.r.l.SimpleMessageListenerContainer 1917: Failed to check/redeclare aut
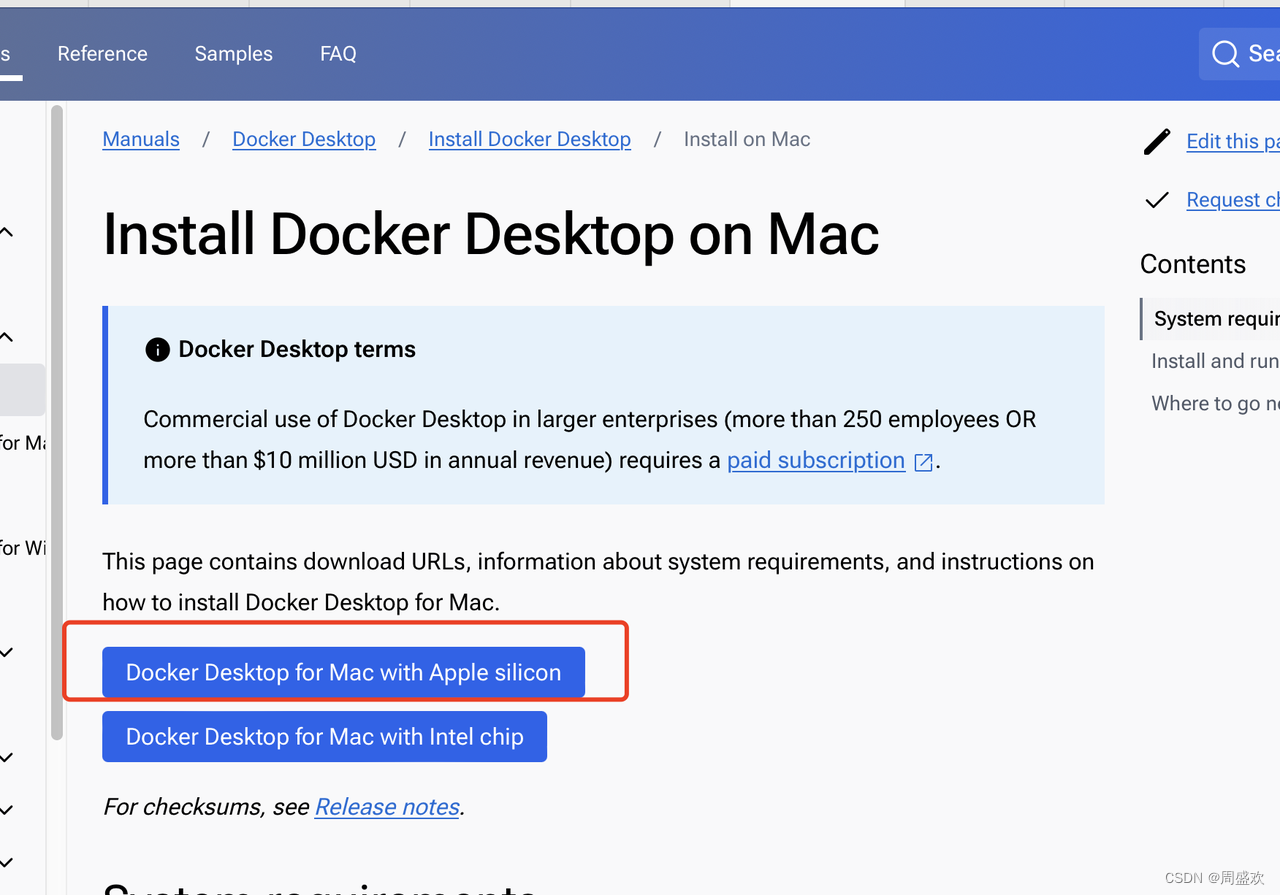
Mac上轻松几步搞定Docker与Redis安装:从下载安装到容器运行实测全程指南
BackTrader 中文文档(十八)(4)
Java一分钟之-Map接口与HashMap详解
BackTrader 中文文档(十八)(3)