这篇文章来自一个读者在面试过程中的一个问题,Hadoop在shuffle过程中使用了一个数据结构-环形缓冲区。
环形队列是在实际编程极为有用的数据结构,它是一个首尾相连的FIFO的数据结构,采用数组的线性空间,数据组织简单。能很快知道队列是否满为空。能以很快速度的来存取数据。 因为有简单高效的原因,甚至在硬件都实现了环形队列。
环形队列广泛用于网络数据收发,和不同程序间数据交换(比如内核与应用程序大量交换数据,从硬件接收大量数据)均使用了环形队列。
环形缓冲区数据结构
Map过程中环形缓冲区是指数据被map处理之后会先放入内存,内存中的这片区域就是环形缓冲区。
环形缓冲区是在MapTask.MapOutputBuffer中定义的,相关的属性如下:
// k/v accounting
// 存放meta数据的IntBuffer,都是int entry,占4byte
private IntBuffer kvmeta; // metadata overlay on backing store
int kvstart; // marks origin of spill metadata
int kvend; // marks end of spill metadata
int kvindex; // marks end of fully serialized records
// 分割meta和key value内容的标识
// meta数据和key value内容都存放在同一个环形缓冲区,所以需要分隔开
int equator; // marks origin of meta/serialization
int bufstart; // marks beginning of spill
int bufend; // marks beginning of collectable
int bufmark; // marks end of record
int bufindex; // marks end of collected
int bufvoid; // marks the point where we should stop
// reading at the end of the buffer
// 存放key value的byte数组,单位是byte,注意与kvmeta区分
byte[] kvbuffer; // main output buffer
private final byte[] b0 = new byte[0];
// key value在kvbuffer中的地址存放在偏移kvindex的距离
private static final int VALSTART = 0; // val offset in acct
private static final int KEYSTART = 1; // key offset in acct
// partition信息存在kvmeta中偏移kvindex的距离
private static final int PARTITION = 2; // partition offset in acct
private static final int VALLEN = 3; // length of value
// 一对key value的meta数据在kvmeta中占用的个数
private static final int NMETA = 4; // num meta ints
// 一对key value的meta数据在kvmeta中占用的byte数
private static final int METASIZE = NMETA * 4; // size in bytes环形缓冲区其实是一个数组,数组中存放着key、value的序列化数据和key、value的元数据信息,key/value的元数据存储的格式是int类型,每个key/value对应一个元数据,元数据由4个int组成,第一个int存放value的起始位置,第二个存放key的起始位置,第三个存放partition,最后一个存放value的长度。
key/value序列化的数据和元数据在环形缓冲区中的存储是由equator分隔的,key/value按照索引递增的方向存储,meta则按照索引递减的方向存储,将其数组抽象为一个环形结构之后,以equator为界,key/value顺时针存储,meta逆时针存储。
初始化
环形缓冲区的结构在MapOutputBuffer.init中创建。
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
...
//MAP_SORT_SPILL_PERCENT = mapreduce.map.sort.spill.percent
// map 端buffer所占的百分比
//sanity checks
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
//IO_SORT_MB = "mapreduce.task.io.sort.mb"
// map 端buffer大小
// mapreduce.task.io.sort.mb * mapreduce.map.sort.spill.percent 最好是16的整数倍
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100);
// 所有的spill index 在内存所占的大小的阈值
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT);
...
// 排序的实现类,可以自己实现。这里用的是改写的快排
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
// buffers and accounting
// 上面IO_SORT_MB的单位是MB,左移20位将单位转化为byte
int maxMemUsage = sortmb << 20;
// METASIZE是元数据的长度,元数据有4个int单元,分别为
// VALSTART、KEYSTART、PARTITION、VALLEN,而int为4个byte,
// 所以METASIZE长度为16。下面是计算buffer中最多有多少byte来存元数据
maxMemUsage -= maxMemUsage % METASIZE;
// 元数据数组 以byte为单位
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
// 将kvbuffer转化为int型的kvmeta 以int为单位,也就是4byte
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer();
// 设置buf和kvmeta的分界线
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
// kvmeta中存放元数据实体的最大个数
maxRec = kvmeta.capacity() / NMETA;
// buffer spill时的阈值(不单单是sortmb*spillper)
// 更加精确的是kvbuffer.length*spiller
softLimit = (int)(kvbuffer.length * spillper);
// 此变量较为重要,作为spill的动态衡量标准
bufferRemaining = softLimit;
...
// k/v serialization
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
// 将bb作为key序列化写入的output
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
// 将bb作为value序列化写入的output
valSerializer.open(bb);
...
// combiner
...
spillInProgress = false;
// 最后一次merge时,在有combiner的情况下,超过此阈值才执行combiner
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw new IOException("Spill thread failed to initialize",
sortSpillException);
}
}init是对环形缓冲区进行初始化构造,由mapreduce.task.io.sort.mb决定map中环形缓冲区的大小sortmb,默认是100M。
此缓冲区也用于存放meta,一个meta占用METASIZE(16byte),则其中用于存放数据的大小是maxMemUsage -= sortmb << 20 % METASIZE(由此可知最好设置sortmb转换为byte之后是16的整数倍),然后用maxMemUsage初始化kvbuffer字节数组和kvmeta整形数组,最后设置数组的一些标识信息。利用setEquator(0)设置kvbuffer和kvmeta的分界线,初始化的时候以0为分界线,kvindex为aligned - METASIZE + kvbuffer.length,其位置在环形数组中相当于按照逆时针方向减去METASIZE,由kvindex设置kvstart = kvend = kvindex,由equator设置bufstart = bufend = bufindex = equator,还得设置bufvoid = kvbuffer.length,bufvoid用于标识用于存放数据的最大位置。
为了提高效率,当buffer占用达到阈值之后,会进行spill,这个阈值是由bufferRemaining进行检查的,bufferRemaining由softLimit = (int)(kvbuffer.length spillper); bufferRemaining = softLimit;进行初始化赋值,这里需要注意的是softLimit并不是sortmbspillper,而是kvbuffer.length spillper,当sortmb << 20是16的整数倍时,才可以认为softLimit是sortmbspillper。
下面是setEquator的代码
// setEquator(0)的代码如下
private void setEquator(int pos) {
equator = pos;
// set index prior to first entry, aligned at meta boundary
// 第一个 entry的末尾位置,即元数据和kv数据的分界线 单位是byte
final int aligned = pos - (pos % METASIZE);
// Cast one of the operands to long to avoid integer overflow
// 元数据中存放数据的起始位置
kvindex = (int)
(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
LOG.info("(EQUATOR) " + pos + " kvi " + kvindex +
"(" + (kvindex * 4) + ")");
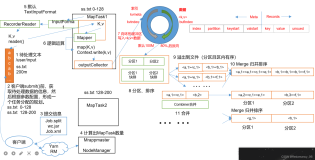
}buffer初始化之后的抽象数据结构如下图所示:
环形缓冲区数据结构图
环形缓冲区数据结构图
写入buffer
Map通过NewOutputCollector.write方法调用collector.collect向buffer中写入数据,数据写入之前已在NewOutputCollector.write中对要写入的数据进行逐条分区,下面看下collect
// MapOutputBuffer.collect
public synchronized void collect(K key, V value, final int partition
) throws IOException {
...
// 新数据collect时,先将剩余的空间减去元数据的长度,之后进行判断
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
// 首次spill时,spillInProgress是false
if (!spillInProgress) {
// 得到kvindex的byte位置
final int kvbidx = 4 * kvindex;
// 得到kvend的byte位置
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
// 将key value 及元数据信息写入缓冲区
try {
// serialize key bytes into buffer
int keystart = bufindex;
// 将key序列化写入kvbuffer中,并移动bufindex
keySerializer.serialize(key);
// key所占空间被bufvoid分隔,则移动key,
// 将其值放在连续的空间中便于sort时key的对比
if (bufindex < keystart) {
// wrapped the key; must make contiguous
bb.shiftBufferedKey();
keystart = 0;
}
// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
// It's possible for records to have zero length, i.e. the serializer
// will perform no writes. To ensure that the boundary conditions are
// checked and that the kvindex invariant is maintained, perform a
// zero-length write into the buffer. The logic monitoring this could be
// moved into collect, but this is cleaner and inexpensive. For now, it
// is acceptable.
bb.write(b0, 0, 0);
// the record must be marked after the preceding write, as the metadata
// for this record are not yet written
int valend = bb.markRecord();
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(
distanceTo(keystart, valend, bufvoid));
// write accounting info
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
// advance kvindex
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}每次写入数据时,执行bufferRemaining -= METASIZE之后,检查bufferRemaining,
如果大于0,直接将key/value序列化对和对应的meta写入buffer中,key/value是序列化之后写入的,key/value经过一些列的方法调用Serializer.serialize(key/value) -> WritableSerializer.serialize(key/value) -> BytesWritable.write(dataOut) -> DataOutputStream.write(bytes, 0, size) -> MapOutputBuffer.Buffer.write(b, off, len),最后由MapOutputBuffer.Buffer.write(b, off, len)将数据写入kvbuffer中,write方法如下:
public void write(byte b[], int off, int len)
throws IOException {
// must always verify the invariant that at least METASIZE bytes are
// available beyond kvindex, even when len == 0
bufferRemaining -= len;
if (bufferRemaining <= 0) {
// writing these bytes could exhaust available buffer space or fill
// the buffer to soft limit. check if spill or blocking are necessary
boolean blockwrite = false;
spillLock.lock();
try {
do {
checkSpillException();
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// ser distance to key index
final int distkvi = distanceTo(bufindex, kvbidx);
// ser distance to spill end index
final int distkve = distanceTo(bufindex, kvbend);
// if kvindex is closer than kvend, then a spill is neither in
// progress nor complete and reset since the lock was held. The
// write should block only if there is insufficient space to
// complete the current write, write the metadata for this record,
// and write the metadata for the next record. If kvend is closer,
// then the write should block if there is too little space for
// either the metadata or the current write. Note that collect
// ensures its metadata requirement with a zero-length write
blockwrite = distkvi <= distkve
? distkvi <= len + 2 * METASIZE
: distkve <= len || distanceTo(bufend, kvbidx) < 2 * METASIZE;
if (!spillInProgress) {
if (blockwrite) {
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
// need to use meta exclusively; zero-len rec & 100% spill
// pcnt would fail
resetSpill(); // resetSpill doesn't move bufindex, kvindex
bufferRemaining = Math.min(
distkvi - 2 * METASIZE,
softLimit - distanceTo(kvbidx, bufindex)) - len;
continue;
}
// we have records we can spill; only spill if blocked
if (kvindex != kvend) {
startSpill();
// Blocked on this write, waiting for the spill just
// initiated to finish. Instead of repositioning the marker
// and copying the partial record, we set the record start
// to be the new equator
setEquator(bufmark);
} else {
// We have no buffered records, and this record is too large
// to write into kvbuffer. We must spill it directly from
// collect
final int size = distanceTo(bufstart, bufindex) + len;
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
bufvoid = kvbuffer.length;
throw new MapBufferTooSmallException(size + " bytes");
}
}
}
if (blockwrite) {
// wait for spill
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException(
"Buffer interrupted while waiting for the writer", e);
}
}
} while (blockwrite);
} finally {
spillLock.unlock();
}
}
// here, we know that we have sufficient space to write
if (bufindex + len > bufvoid) {
final int gaplen = bufvoid - bufindex;
System.arraycopy(b, off, kvbuffer, bufindex, gaplen);
len -= gaplen;
off += gaplen;
bufindex = 0;
}
System.arraycopy(b, off, kvbuffer, bufindex, len);
bufindex += len;
}write方法将key/value写入kvbuffer中,如果bufindex+len超过了bufvoid,则将写入的内容分开存储,将一部分写入bufindex和bufvoid之间,然后重置bufindex,将剩余的部分写入,这里不区分key和value,写入key之后会在collect中判断bufindex < keystart,当bufindex小时,则key被分开存储,执行bb.shiftBufferedKey(),value则直接写入,不用判断是否被分开存储,key不能分开存储是因为要对key进行排序。
这里需要注意的是要写入的数据太长,并且kvinde==kvend,则抛出MapBufferTooSmallException异常,在collect中捕获,将此数据直接spill到磁盘spillSingleRecord,也就是当单条记录过长时,不写buffer,直接写入磁盘。
下面看下bb.shiftBufferedKey()代码
// BlockingBuffer.shiftBufferedKey
protected void shiftBufferedKey() throws IOException {
// spillLock unnecessary; both kvend and kvindex are current
int headbytelen = bufvoid - bufmark;
bufvoid = bufmark;
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
final int avail =
Math.min(distanceTo(0, kvbidx), distanceTo(0, kvbend));
if (bufindex + headbytelen < avail) {
System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex);
System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen);
bufindex += headbytelen;
bufferRemaining -= kvbuffer.length - bufvoid;
} else {
byte[] keytmp = new byte[bufindex];
System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex);
bufindex = 0;
out.write(kvbuffer, bufmark, headbytelen);
out.write(keytmp);
}
}shiftBufferedKey时,判断首部是否有足够的空间存放key,有没有足够的空间,则先将首部的部分key写入keytmp中,然后分两次写入,再次调用Buffer.write,如果有足够的空间,分两次copy,先将首部的部分key复制到headbytelen的位置,然后将末尾的部分key复制到首部,移动bufindex,重置bufferRemaining的值。
key/value写入之后,继续写入元数据信息并重置kvindex的值。
spill
一次写入buffer结束,当写入数据比较多,bufferRemaining小于等于0时,准备进行spill,首次spill,spillInProgress为false,此时查看bUsed = distanceTo(kvbidx, bufindex),此时bUsed >= softLimit 并且 (kvbend + METASIZE) % kvbuffer.length == equator - (equator % METASIZE),则进行spill,调用startSpill
private void startSpill() {
// 元数据的边界赋值
kvend = (kvindex + NMETA) % kvmeta.capacity();
// key/value的边界赋值
bufend = bufmark;
// 设置spill运行标识
spillInProgress = true;
...
// 利用重入锁,对spill线程进行唤醒
spillReady.signal();
}startSpill唤醒spill线程之后,进程spill操作,但此时map向buffer的写入操作并没有阻塞,需要重新边界equator和bufferRemaining的值,先来看下equator和bufferRemaining值的设定:
// 根据已经写入的kv得出每个record的平均长度
final int avgRec = (int) (mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
// 得到空余空间的大小
final int distkvi = distanceTo(bufindex, kvbidx);
// 得出新equator的位置
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;因为equator是kvbuffer和kvmeta的分界线,为了更多的空间存储kv,则最多拿出distkvi的一半来存储meta,并且利用avgRec估算distkvi能存放多少个record和meta对,根据record和meta对的个数估算meta所占空间的大小,从distkvi/2和meta所占空间的大小中取最小值,又因为distkvi中最少得存放一个meta,所占空间为METASIZE,在选取kvindex时需要求aligned,aligned最多为METASIZE-1,总和上述因素,最终选取equator为(bufindex + Math.max(2 METASIZE - 1, Math.min(distkvi / 2, distkvi / (METASIZE + avgRec) METASIZE)))。equator选取之后,设置bufmark = bufindex = newPos和kvindex,但此时并不设置bufstart、bufend和kvstart、kvend,因为这几个值要用来表示spill数据的边界。
spill之后,可用的空间减少了,则控制spill的bufferRemaining也应该重新设置,bufferRemaining取三个值的最小值减去2METASIZE,三个值分别是meta可用占用的空间distanceTo(bufend, newPos),kv可用空间distanceTo(newPos, serBound)和softLimit。这里为什么要减去2METASIZE,一个是spill之前kvend到kvindex的距离,另一个是当时的kvindex空间????此时,已有一个record要写入buffer,需要从bufferRemaining中减去当前record的元数据占用的空间,即减去METASIZE,另一个METASIZE是在计算equator时,没有包括kvindex到kvend(spill之前)的这段METASIZE,所以要减去这个METASIZE。
接下来解析下SpillThread线程,查看其run方法:
public void run() {
spillLock.lock();
spillThreadRunning = true;
try {
while (true) {
spillDone.signal();
// 判断是否在spill,false则挂起SpillThread线程,等待唤醒
while (!spillInProgress) {
spillReady.await();
}
try {
spillLock.unlock();
// 唤醒之后,进行排序和溢写到磁盘
sortAndSpill();
} catch (Throwable t) {
sortSpillException = t;
} finally {
spillLock.lock();
if (bufend < bufstart) {
bufvoid = kvbuffer.length;
}
kvstart = kvend;
bufstart = bufend;
spillInProgress = false;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
spillLock.unlock();
spillThreadRunning = false;
}
}
run中主要是sortAndSpill,
private void sortAndSpill() throws IOException, ClassNotFoundException,
InterruptedException {
//approximate the length of the output file to be the length of the
//buffer + header lengths for the partitions
final long size = distanceTo(bufstart, bufend, bufvoid) +
partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
try {
// create spill file
// 用来存储index文件
final SpillRecord spillRec = new SpillRecord(partitions);
// 创建写入磁盘的spill文件
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
// 打开文件流
out = rfs.create(filename);
// kvend/4 是截止到当前位置能存放多少个元数据实体
final int mstart = kvend / NMETA;
// kvstart 处能存放多少个元数据实体
// 元数据则在mstart和mend之间,(mstart - mend)则是元数据的个数
final int mend = 1 + // kvend is a valid record
(kvstart >= kvend
? kvstart
: kvmeta.capacity() + kvstart) / NMETA;
// 排序 只对元数据进行排序,只调整元数据在kvmeta中的顺序
// 排序规则是MapOutputBuffer.compare,
// 先对partition进行排序其次对key值排序
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
int spindex = mstart;
// 创建rec,用于存放该分区在数据文件中的信息
final IndexRecord rec = new IndexRecord();
final InMemValBytes value = new InMemValBytes();
for (int i = 0; i < partitions; ++i) {
// 临时文件是IFile格式的
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out);
writer = new Writer<K, V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
// 往磁盘写数据时先判断是否有combiner
if (combinerRunner == null) {
// spill directly
DataInputBuffer key = new DataInputBuffer();
// 写入相同partition的数据
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
final int kvoff = offsetFor(spindex % maxRec);
int keystart = kvmeta.get(kvoff + KEYSTART);
int valstart = kvmeta.get(kvoff + VALSTART);
key.reset(kvbuffer, keystart, valstart - keystart);
getVBytesForOffset(kvoff, value);
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec)
+ PARTITION) == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
writer.close();
// record offsets
// 记录当前partition i的信息写入索文件rec中
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
// spillRec中存放了spill中partition的信息,便于后续堆排序时,取出partition相关的数据进行排序
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
// 判断内存中的index文件是否超出阈值,超出则将index文件写入磁盘
// 当超出阈值时只是把当前index和之后的index写入磁盘
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
// 创建index文件
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
LOG.info("Finished spill " + numSpills);
++numSpills;
} finally {
if (out != null) out.close();
}
}sortAndSpill中,有mstart和mend得到一共有多少条record需要spill到磁盘,调用sorter.sort对meta进行排序,先对partition进行排序,然后按key排序,排序的结果只调整meta的顺序。
排序之后,判断是否有combiner,没有则直接将record写入磁盘,写入时是一个partition一个IndexRecord,如果有combiner,则将该partition的record写入kvIter,然后调用combinerRunner.combine执行combiner。
写入磁盘之后,将spillx.out对应的spillRec放入内存indexCacheList.add(spillRec),如果所占内存totalIndexCacheMemory超过了indexCacheMemoryLimit,则创建index文件,将此次及以后的spillRec写入index文件存入磁盘。
最后spill次数递增。sortAndSpill结束之后,回到run方法中,执行finally中的代码,对kvstart和bufstart赋值,kvstart = kvend,bufstart = bufend,设置spillInProgress的状态为false。
在spill的同时,map往buffer的写操作并没有停止,依然在调用collect,再次回到collect方法中,
// MapOutputBuffer.collect
public synchronized void collect(K key, V value, final int partition
) throws IOException {
...
// 新数据collect时,先将剩余的空间减去元数据的长度,之后进行判断
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
// 首次spill时,spillInProgress是false
if (!spillInProgress) {
// 得到kvindex的byte位置
final int kvbidx = 4 * kvindex;
// 得到kvend的byte位置
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
...
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
...
}有新的record需要写入buffer时,判断bufferRemaining -= METASIZE,此时的bufferRemaining是在开始spill时被重置过的(此时的bufferRemaining应该比初始的softLimit要小),当bufferRemaining小于等最后一个METASIZE是当前record进入collect之后bufferRemaining减去的那个METASIZE。
于0时,进入if,此时spillInProgress的状态为false,进入if (!spillInProgress),startSpill时对kvend和bufend进行了重置,则此时(kvbend + METASIZE) % kvbuffer.length != equator - (equator % METASIZE),调用resetSpill(),将kvstart、kvend和bufstart、bufend设置为上次startSpill时的位置。此时buffer已将一部分内容写入磁盘,有大量空余的空间,则对bufferRemaining进行重置,此次不spill。
bufferRemaining取值为Math.min(distanceTo(bufindex, kvbidx) - 2 * METASIZE, softLimit - bUsed) - METASIZE
private void resetSpill() {
final int e = equator;
bufstart = bufend = e;
final int aligned = e - (e % METASIZE);
// set start/end to point to first meta record
// Cast one of the operands to long to avoid integer overflow
kvstart = kvend = (int)
(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
LOG.info("(RESET) equator " + e + " kv " + kvstart + "(" +
(kvstart * 4) + ")" + " kvi " + kvindex + "(" + (kvindex * 4) + ")");
}当bufferRemaining再次小于等于0时,进行spill,这以后就都是套路了。环形缓冲区分析到此结束。
本文转载自公众号:大数据技术与架构
原文链接
阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区近万人Spark技术同学在线提问答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!
对开源大数据和感兴趣的同学可以加小编微信(下图二维码,备注“进群”)进入技术交流微信群。