2017运维/DevOps在线技术峰会上,阿里云应用运维专家夸父带来题为“同城容灾架构剖析”的演讲。本文主要从部署目标和要求开始谈起,接着着重对架构进行分析,然后又重点对任务分解进行说明,并对单双机房的部署进行了对比,最后分享了容灾演练方式。一起来了解下吧。
以下是精彩内容整理:
近几个月,运维事件频发。从“炉石数据被删”到“MongoDB遭黑客勒索”,从“Gitlab数据库被误删”到某家公司漏洞被组合攻击。这些事件,无一不在呐喊——做好运维工作的重要性。然而,从传统IT部署到云,人肉运维已经是过去式,云上运维该怎么开展?尤其是云2.0时代,运维已经向全局化、流程化和精细化模式转变。与此同时,人工智能的发展,“威胁论”也随之袭来——运维是不是快要无用武之地了?如何去做更智能的活,当下很多运维人在不断思考和探寻答案。
从历史来看,单机房出现网络级故障、电源级故障都时有发生,阿里云在北京、香港机房等都出现过故障,从业界来看,对于机房级别,类似于云上engine级别的容灾是非常有必要的,下面我们来具体了解下我们的业务系统是怎样做双机容灾的。
目标&要求
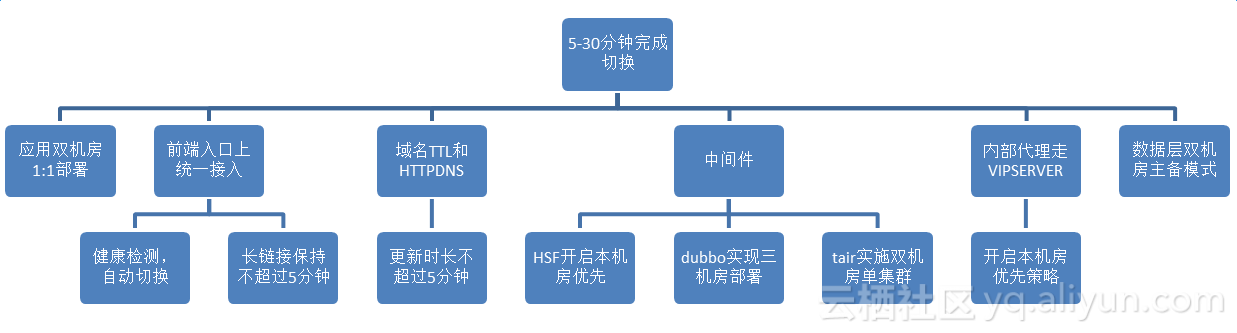
我们的目标就是在一个机房出现断网或断电的情况下,能够在5~30分钟完成从A机房切换到B机房。最初当A机房单独部署时,我们要把所有应用从A机房完全copy一份部署到B机房,从架构层面看,要将所有流量放到最前面机房级入口上,所以我们将所有前端的流量,包括open API流量、页面级的流量等全部切到统一接入,统一接入就是tengine proxy,并且我们在域名层TTL和HTTPDNS都做了设置,全网的更新时间不能超过5分钟;还有很多中间件的部分,包括HSF开启本机房优先、dubbo实现三机房部署和tair实施双机房单集群等20多个中间件;另外,内部代理走VIPSERVER,开启本机房优先策略;还有数据层双机房主备模式。
我们到底要做什么呢?
首先设立目标,5~30分钟完成切换,从应用层来说,我们要实现双机房部署,从流量层来说,我们需要从两边机房引入流量,这是一个双活的概念,不是一主一备。
架构设计
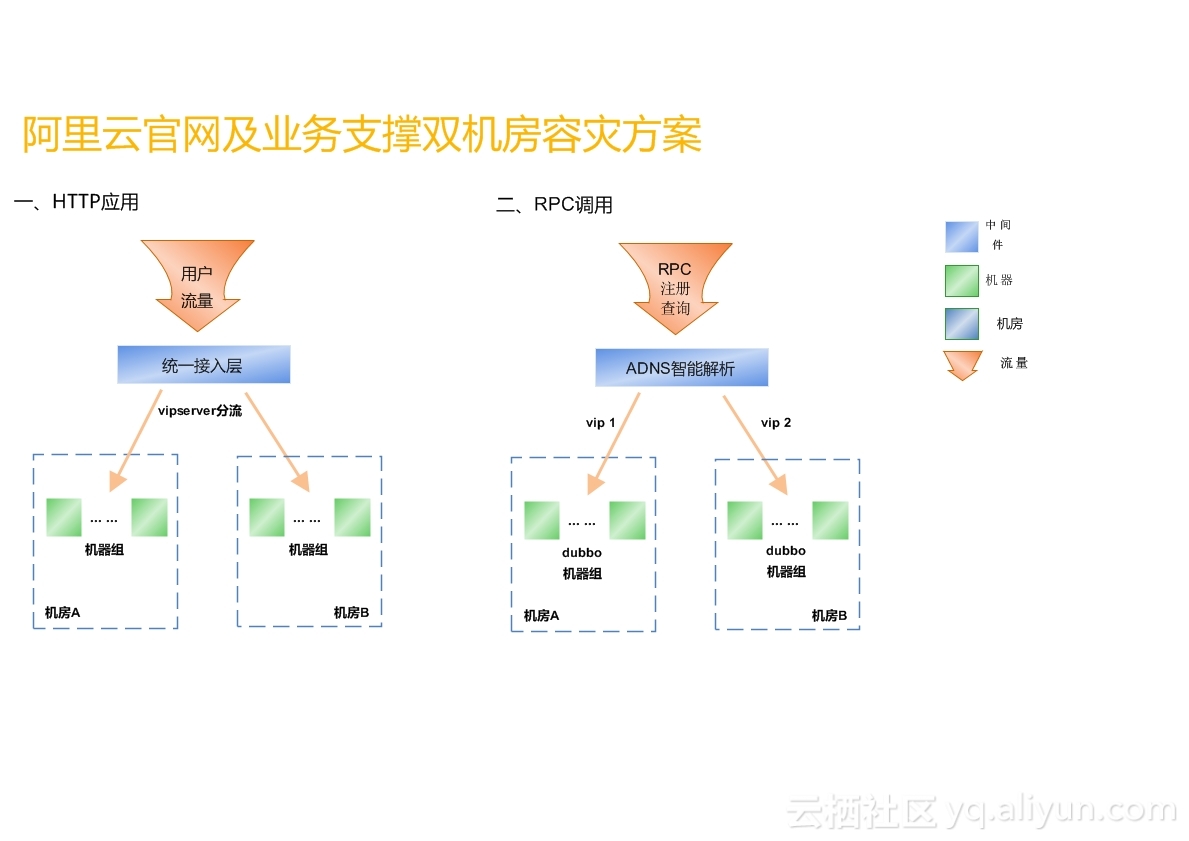
我们将所有流量全部向上提了一层,接统一接入层的http应用。最初的架构并不是这样的,是按照一个频道一个频道接入的,按1:1的模式,这样的架构的好处是互不影响,任何一组机器挂掉,只影响一个模块对外提供的服务,但做双机容灾采用这种方案的话,复杂度太高,所以我们接入统一接入层。
针对接入统一接入的http应用,统一接入层有分流策略,天然支持应用多机房部署。流量进入统一接入后,通过VIPserver进行分流,VIPserver自带健康检查,当应用或者网络出现问题,自动切断流量。
我们还有很大部分是RPC类型的应用,类似今天注册中心、注册发现的这种,不像前端流量直接打进来,其实是注册到注册中心,由注册中心告诉服务注册者或消费者真正的服务在哪里,我们认为它并不适合统一接入,流量大且对时间要求高,所以我们单独对这组机器做了两个VIP,分在两三个机房,对dubbo注册中心域名dubbo.aliyun-inc.com进行ADNS智能解析,当机房出现故障,ADNS会自动踢掉有问题的VIP。
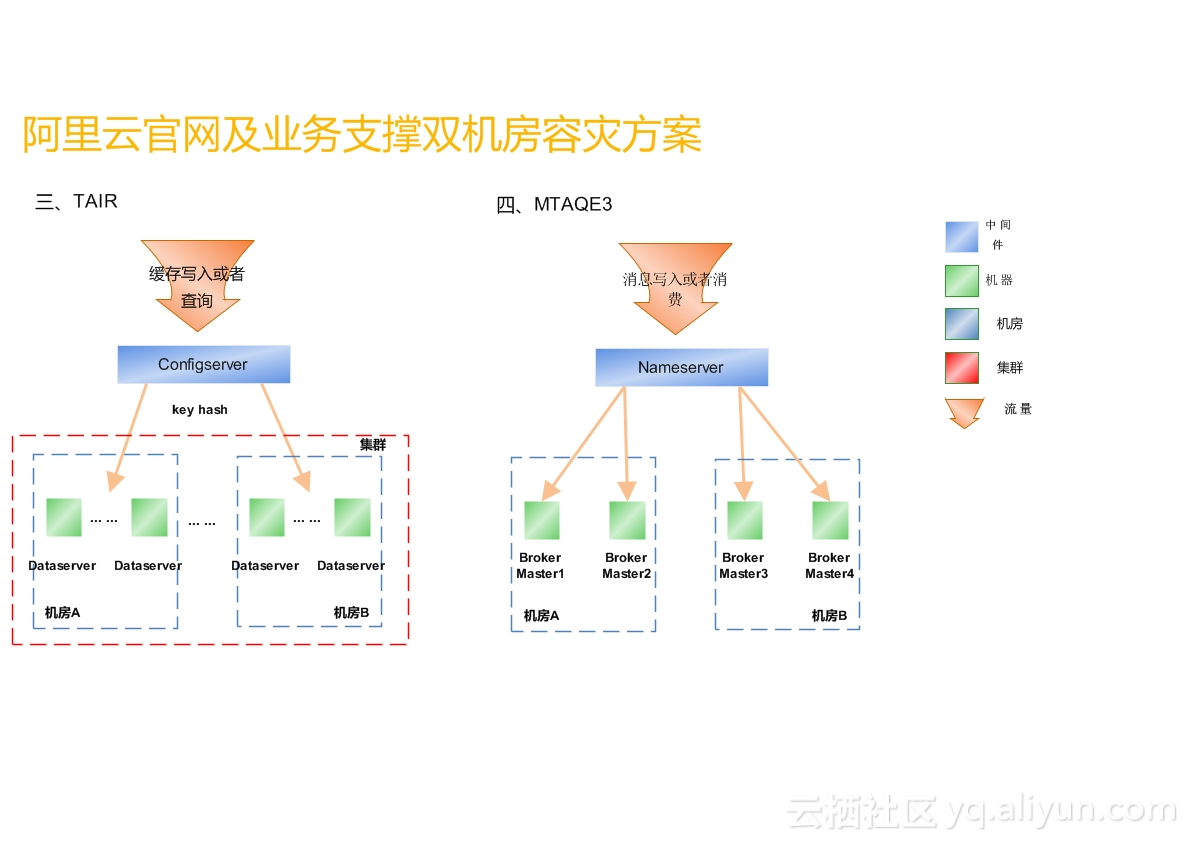
在做规则时,架构分为三层,包括web应用层、中间件层和数据库层。我们选取两个比较有代表性的中间件来讲:
从事实角度来讲,TAIR的改造量是最大的,TAIR有双机房单集群模式、双机房双集群模式,应用只在一个机房时,有些用双机房双集群模式,有一些用双机房单集群,经过技术判断和排查,发现当使用双机房部署时,可以用双机房双集群,但涉及代码改造量会非常大,因为需要保证两个集群数据的一致性,而双机房单集群也有缺陷,比如A机房出现断网断数据情况下,TAIR数据里是有50%数据要丢失,意味着选择双机房单集群就要忍受数据丢失,如果对数据要求非常高,必须选择双机房双集群,如果业务对数据一致性要求较高,但对于数据的丢失可以忍受,那就可以用选择双机房单集群。
MTAQE3也比较有数据,MTAQE3其实是一个队列,队列服务是不允许数据丢失的,所以MTAQE3是在两个机房各设置了两个机器,全部都是master,相当于消息写入时随机写入一个master到某个机房,如果全部都是双master结构也有弊端,就是没有备份,数据有可能在机器故障时丢失,对于我们的应用来说对于该场景的忍受度还可以,这也是基于业务来确定的,如果消息丢失可以重写,双master是被允许的。如果当有一条消息写入到A机房,恰好有B机房的应用读A机房读到一半,A机房断网了,这时消息就会丢失,相当于消费了一半,比如ECS的生产,场景是非常复杂的,取一条消息比如磁盘是多少、cpu是多少,锁定消息后,它是串行的,后面还要烧IP、OS和各种场景,它是要将这条消息取走消费一遍再塞回去,这是一个事务流的场景,可能会断掉,断掉后会有补偿机制,最终结合业务场景和开发人员沟通,确定双master架构,保证消息队列能够平稳正常运行。
任务分解
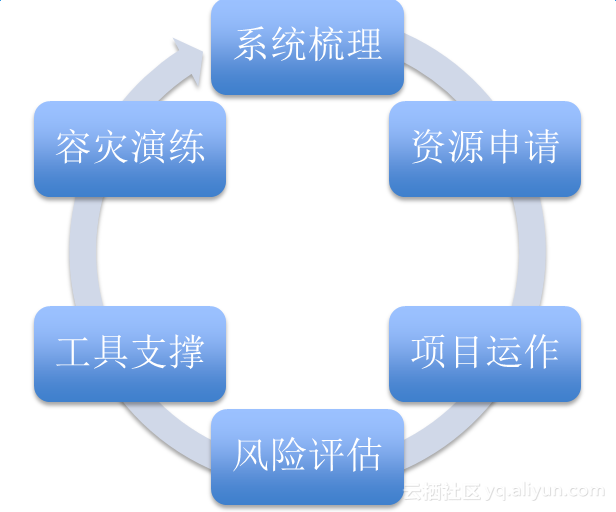
我们对整个项目进行任务分解,首先是系统梳理,到底有哪些系统需要做双机容灾;其次是资源申请,包括服务器申请、人的申请等;接着是项目运作,还要做风险评估,怎样去规避风险;从A机房将所有应用向B机房复制时,势必要有很强大的工具支撑,光靠人力来支撑是无法完成的;所有事情做完后,通过容灾演练来验证项目是否达到预期目标,如果没有,进行改进。
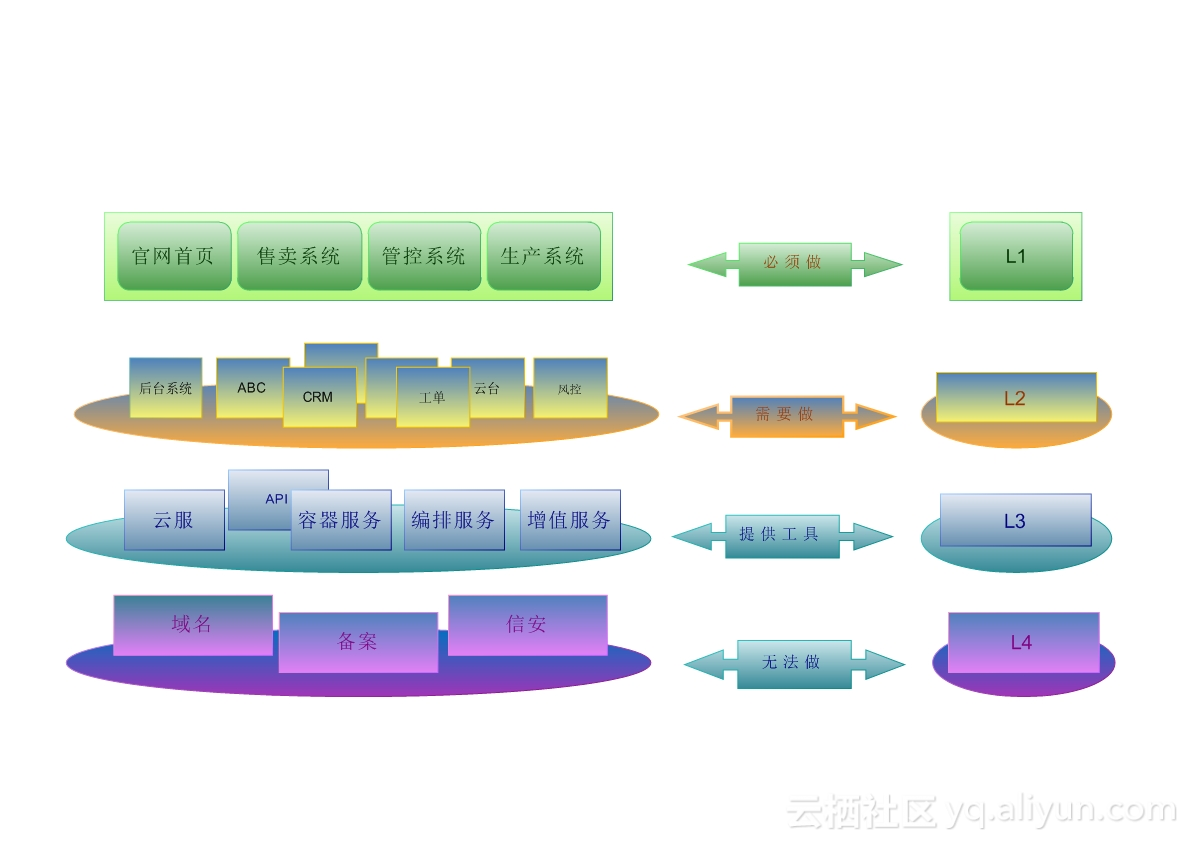
任务分解,在整个官网系统有上千个应用,几千台服务器,这么多系统肯定是要分级别的,具体如下:
- L1级别是最高的,比如官网首页、售卖系统、管控系统和生产系统等一些核心业务必须要完成双机房部署的;
- L2比如后台系统、CRM、工单和云台等作为支撑系统,优先级次之,并不直接对用户提供服务,但对于我们来说是非常重要的,对于客户来说也是非常重要的;
- L3比如像云服、容器服务、编排服务和增值服务等,更多的是由开发同学自己维护和部署,这部分也是需要做的,但是我们需要提供工具,提供咨询和服务;
- L4比如像域名、备案和信安,这些都是强绑定的,暂时没有办法做,带后面所有都完成后,这部分也会做掉,也会对用户直接提供服务,比如域名买了需要备案等。
只要涉及到用户的需求,我们一定会做,严格以用户的需求为需求,所以任务分解是非常重要的一步,所以我们要分阶段去做:
1. 资源申请:我们要申请服务器资源,成立联合项目组,申请中间件及DBA团队支持;
2. 项目运作:建立项目组钉钉群同步改造进度,以项目周报的方式向所有老板及相关同学同步进度,以双周会的形式推进疑难问题解决及风险评估;
3. 工具支撑:开发了专门的工具平台用户应用快速扩容,开发专门的工具用户快速测试等;
4. 容灾演练:制定机房级的断网用以验证同城容灾的结果是否符合架构设计并发现隐藏问题。
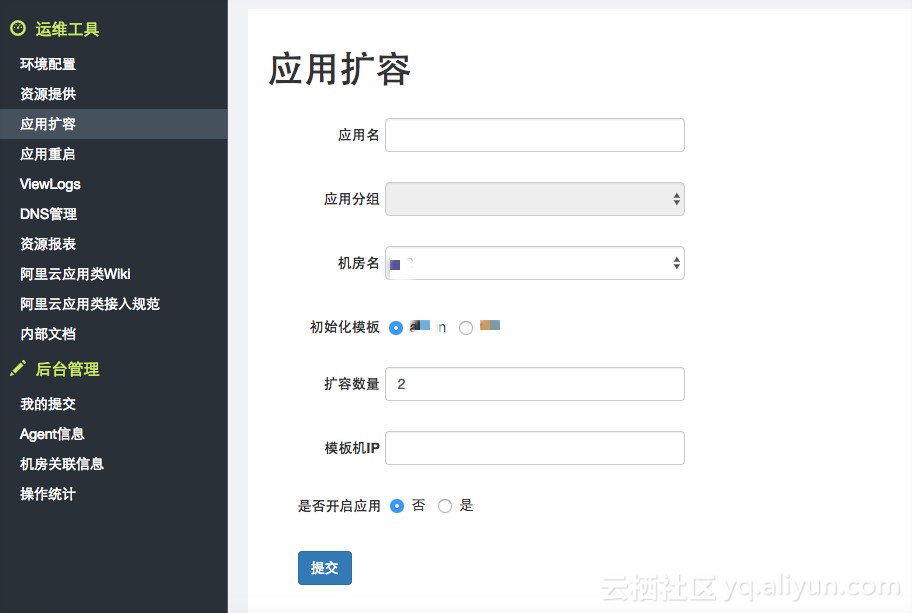
上图为我们开发出的专门的一键扩容工具,将应用填进去,将分组取出来,确定扩容机房,以线上一台模板机作为扩容对象,完全克隆模板机上的所有应用环境配置,可以实现机房级别的快速扩容,极大的提高了效率。后续我们可能会使用自定义镜像去做,将线上一台机器打成自定义镜像,新的机器用自定义镜像开启就好。
架构对比图
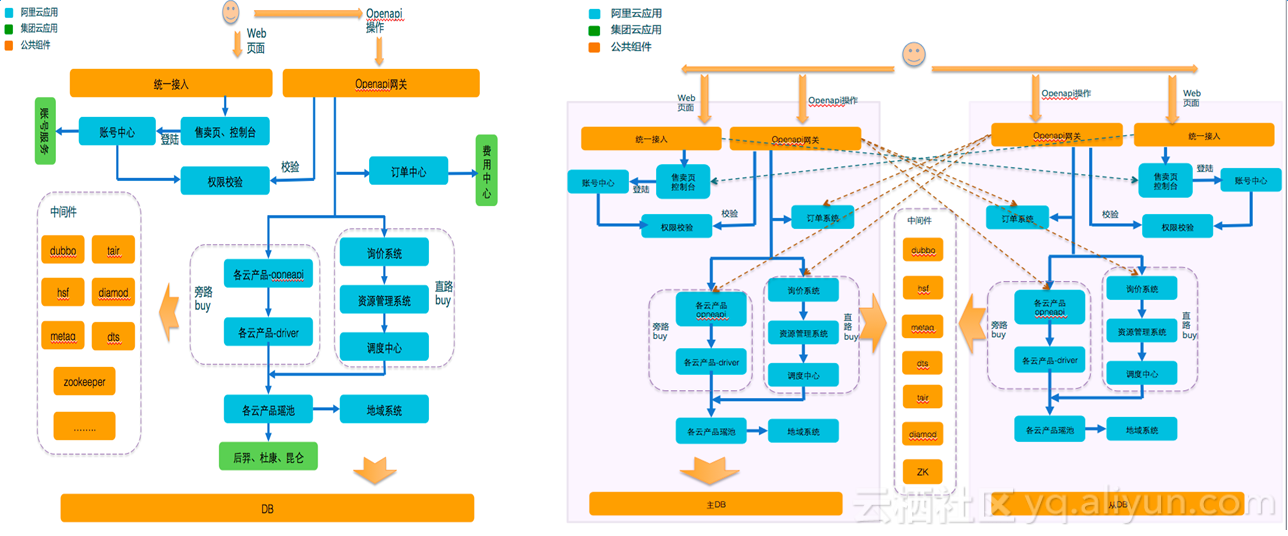
图中左侧为单机房时架构,可以从架构中很清楚的看到,用户进来的最前端有两层,第一层是web层,包括首页、账号、售卖页和支付、控制台等,第二层是open API网关,进来后经过登录和权限校验向下钓,是一个非常简化的官网架构图。
图中右侧为双机房架构,看起来很简单,像是将单机房架构复制了一份,但是简单的背后还是有很多事情要做的,中间件须横跨两个机房,要求A机房断掉后,所有中间件要正常提供服务,所有的应用也能正常提供服务,流量最主要的切换在最上面一层,比如A机房断网后,我们需要把放在A机房统一接入和openAPI的流量全部切到B机房,为此我们专门做了一键切换工具,我们需要检测在什么情况下需要启动切换,这是一个复杂的判断过程。
容灾演练
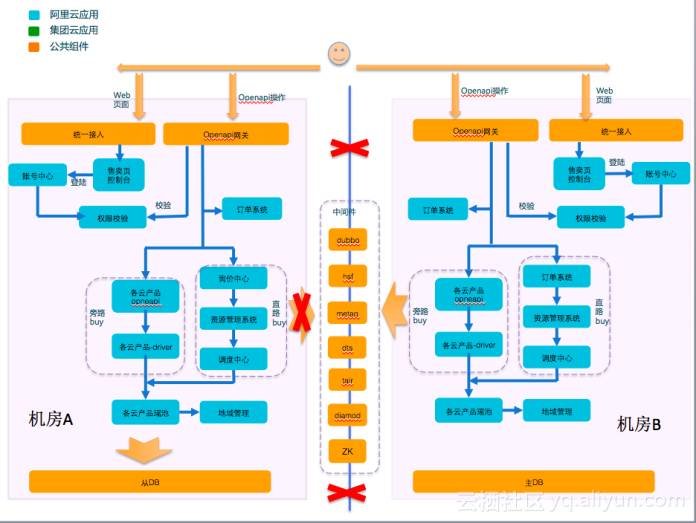
我们要制定演练的方式,具体如下:
- 断网方式:将机房A内网全部通过ACL隔离
- 断网效果:被断网的服务器和其他机房无法进行通信,和本机房通信不受影响,和外围通信(运营商)不受影响
- 流量切换:所有WEB类及Openapi类操作直接通过IDNS智能判断将机房A流量切到机房B
- DB切换:DB采用RDS的proxy实现自动主从切换
- 业务验证:待DB及流量切换完成后采用自动化测试或工具真实售卖、生产及管控进行业务验证
图中A机房连接B机房的路被断掉了,中间件一半的机器被下线了,我们要求所有的中间件集群化,允许一半机器在A机房一半在B机房,不论哪个机房断电都不能影响整个机器的服务,后续我们考虑将ZK去除掉,因为ZK必须是三机房。容灾演练是一个长期的过程,从架构的演进来讲,我们后面更希望做异地容灾,这是更高层的容灾机制。






