TL; DR
本文将讨论机器/深度学习基础设施运维(MLOps)中的机器学习流水线。文章将覆盖以下内容和技术点:
- 定义了生产环境中对 ML pipeline 的要求(requirements)。
- 提供了基于阿里云函数工作流 (FnF),函数计算 (FC) Serverless ML Pipeline 解决方案 Github。
- 解决方案提供 FC 与阿里云容器服务 K8s (ACK) 结合教程,讲解触发任务,部署预测推理服务和暴露服务步骤。
- 对解决方案和类似方案进行分析比较结论:Serverless ML pipeline 可以提高研发效率,优化运维和经济成本,帮助 ML 更快产生价值。
- 讨论 ML 基础设施的选型:函数计算可以很好地和 K8s 集群形成优势互补。
前言
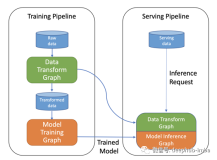
随着机器/深度学习的商业价值体现的越来越明显,围绕 ML 的软件技术也日新月异,训练 (training),模型 (model),算法 (algorithm),预测 (predictions),推理 (inference) 这些概念以及 Spark MLlib, Tensorflow 这些软件框架也变成了超高频词。在本地机器上用 Jupyter notebook 调用 Tensorflow 训练几万张图片,不断调参,然后产出的模型推理/预测看到结果准确当然是很兴奋的,但是然后呢 (so what)?发表在 NIPS 的论文 Hidden Technical Debt in Machine Learning Systems 中的这幅图非常准确地展示了在产生商业价值的过程中,支持机器学习的周边设置的开发,运维 (MLOps)的工程量要远大于机器学习的核心开发。生产环境中的 MLOps 根据业务场景差别会非常大,模块多,无法在一篇文章中覆盖,本文将聚焦在其中的一个模块 -- 机器学习流水线, 重点介绍如何利用阿里云 Serverless 云服务提高研发和运维的效率,自动化地将算法变成训练后的模型,经过测试和审批最终在生产环境中通过预测/推理产生商业价值。

场景抽象,问题定义
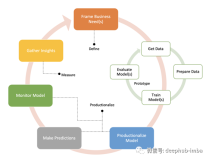
如下图所示,我们将复杂的 MLOps 简化抽象成 算法开发 -> 模型构建 (build) -> 训练 (training) -> 部署 (serving)-> 测试,审批 -> 生产发布,然后再次返回算法开发的反馈回路。

逻辑虽然清楚简单,然而流水线系统需要满足下面的特性才适用于生产环境:
- 支持长时间执行: 模型训练根据数据量和算法执行时间数量级跨度从分钟到小时甚至更长。
- 流程可视化: ML/data scientist 和 DevOps 工程师使用的技术栈有明显区别,需要通过可视化将逻辑描述和实现细节解耦。
- 状态可观测性: ML/data scientist 和 DevOps 工程师在流水线的不同步骤需要交流,协调,配合,需要对流程的进度做观测。
- 描述能力丰富: 相比于 CI/CD 流水线,ML 流水线中业务逻辑更灵活和复杂,例如需要根据结果做选择下一个步骤,循环回到前面的步骤等。
- 事件不丢失: 流水线事件(code push,构建,部署开始结束等时间)在有各种机器宕机或是进程异常的情况下都可以被重新接收处理。
- 步骤可重试: 流水线上的每个任务都有概率随机失败,为步骤加重试可以大幅提高整个流程的成功率。
- 状态持久化: 在宕机或是进程异常的情况下,流水线重新执行可以继续从最近成功的步骤开始,无需重新开始。
- 高可用,低延迟,可扩展: 无需赘述。
- 经济成本高效: 相比起计算资源,流水线编排占总成本比例需要很低。
- 运维成本低: 相比起计算资源,流水线编排占总成本比例需要很低。

- 不同团队,技能栈要求不尽相同。注:图片来源 Machine Learning Model Deployment: Strategy to Implementation
流水线的概念和上述的要求并不新奇,也有开源的解决方案被广泛应用,如 CI/CD 系统常使用的 Jenkins, 工作流引擎 Airflow, Uber Cadence 等。然而在阿里云平台上还没有比较流行的 ML 流水线解决方案,本文将提供一种结合 Serverless 云服务和阿里云容器服务 K8s 的解决方案。
解决方案
本文假设训练,预测推理使用阿里云 K8s(ACK) 集群 或者是基于 ECS 自搭的 K8s 集群。训练使用了 Fashion MNIST dataset 。预测服务接受图片输入产生对应的预测结果 (如是衣,帽,鞋)。Training 和 serving 有分别的容器镜像。流水线编排使用阿里云函数工作流(FnF) 和函数计算 (FC)。FC 和 FnF 都是 Serverless 云服务,都有全托管,免运维,只为使用量付费,无限扩展等特性。流水线逻辑图如下:

- 算法,调参或者其他代码改动触发阿里云容器镜像服务镜像 (image)构建
- 镜像构建成功后配置的 webhook 触发函数计算 HTTP 触发器,函数实现了发起函数工作流流程执行。
- FnF 调用 FC 函数向用户 VPC 内的 K8s apiserver 发起创建任务(jobs)的请求, apiserver config 通过容器服务 DescribeClusterUserKubeconfig 接口获得。模型训练成功后,模型文件会被上传到 OSS。
- FnF 调用 FC 函数向 K8s apiserver 发起创建部署 (deployments)的请求,K8s 会启动容器从 OSS 下载模型,并且监听本地 8501 端口接受预测/推理请求。此时的 serving 服务还无法从 cluster 外部访问。
- FnF 调用 FC 函数向 K8s apiserver 发起创建服务(service)的请求,并且指定 service spec type: LoadBalancer,K8s 根据这个 spec 会创建相应的可以公网访问的 SLB,产生 internet IP 接受 HTTP 请求。
- FnF 调用 FC 向 serving service 发起 HTTP Restful API 调用,判断模型预测精度质量,测试结束后发起人工审核。
- 如果人工审核通过则继续部署生产环境,步骤类似 3,4,5,此处不再重复。
方案部署教程
- 依照Github awesome-fnf/machine-learning-pipeline 项目 README 操作步骤完成部署
- 从函数工作流控制台开始流程执行,输入 input 见 Github README.md,点击下面视频播放流水线效果:
方案分析
上文提到了使用阿里云 Serverless 服务函数计算(FC)和函数工作流 (FnF) 来实现 ML 流水线的协调,有一个很自然的问题就是为什么要做这样的选型,相比已有的开源的工作流引擎有哪些优势。回答这个问题还是要回到问题定义部分中我们列出的生产环境 ML 流水线需要具备的能力一一对比分析:
| 比较项 | FnF & FC | Apache Airflow | Uber Cadence | Jenkins |
|---|---|---|---|---|
| 长时间执行 | 支持 | 支持 | 支持 | 支持 |
| 流程可视化 | 有 | 强 | 无 | 有 |
| 状态可观测 | 可视化 + API | 可视化 + API | API | 可视化 |
| 描述能力 | FDL 描述,高度灵活 | Python DAG 有向无环图描述,受限于数据结构,缺少循环能力,选择功能较弱 | 代码描述,最灵活 | 多种语言 DSL 描述,各步骤类型更适用于 CI/CD,不适用于通用任务 |
| 事件不丢失 | 保证 | 保证 | 保证 | 保证 |
| 状态持久化 | 保证 | 保证 | 保证 | 保证 |
| 高可用 | 保证 | 不保证,需要额外投入实现 | 保证 | 不保证,需要额外投入实现 |
| 低延迟 | 延迟低,100ms 级别步骤转换间隔 | 延迟高,10s 级别步骤转换间隔 | 延迟较低,亚秒级别步骤转换间隔 | 无数据 |
| 水平扩展架构 | 强,无限水平扩展 | 弱,单集群有瓶颈,需要分集群+分数据库做流量扩展 | 强,无限水平扩展 | 弱,单集群有瓶颈,需要分集群做流量扩展 |
| 经济成本效率 | 高效, Serverless 服务仅按使用付费 | 低效,单租集群,多个团队部署多套限制浪费明显 | 低效,支持多租户。自搭集群有闲置浪费。 | 低效,单租集群,多个团队部署多套限制浪费明显 |
| 运维成本 | 低,Serverless 服务免运维 | 高,多个团队多套集群,每个集群多个微服务监控,部署,扩容缩容,failover 机器等 | 高,单集群多个微服务监控,部署,扩容缩容,failover 机器等 | 高,多个团队多套集群,每个集群多个微服务监控,部署,扩容缩容,failover 机器等 |
| 阿里云云服务集成 | 有,FC, MNS 队列 | 无,需要自己实现 | 无,需要自己实现 | 无,需要自己实现 |
| 适用场景 | 通用工作流引擎 | 对延迟,稳定性可以容忍,任务执行较长的批量任务编排 | 通用工作流引擎 | 专注于 CI/CD pipeline, 有很多已有的 CI/CD 功能方便使用 |
FnF & FC 的方案较开源工作流/流水线方案满足上文提出的对生产环境 ML 流水线的所有要求,并且在以下的特点尤其突出:
- 高可用,低延迟,无限水平扩展
- 与阿里云服务的原生集成:FnF 是阿里云产品中第一个专注于工作流的产品,通过原生集成 Serverless 计算服务函数计算,消息服务 MNS 等阿里云服务,打通了几乎所有阿里云产品的编排。加上自身灵活的流程 FDL 描述,满足了从简单到复杂的各式工作流场景。
- 经济成本成本效率高:没有闲置的流水线服务集群,资源利用率最高
- 运维成本低:全托管,免运维,研发交付效率最高。机器学习模型训练等计算资源相对较重(如 K8s 集群,GPU 实例),运维压力也相对重。ML 流水线这类系统通过 Serverless 服务的实现,从主计算资源中剥离出来,不仅简化了 K8s 集群上的部署,也免除对流水线系统的运维,让时间更有效地投入在模型训练,算法调优上。
- 描述能力灵活和可视化的结合:上文介绍的 ML 流水线,是过度简化过的实现,实际业务中的流程逻辑会更复杂。例如在某步骤失败后要实现自动回滚,或者循环回到之前的步骤重新进行。相比于 DAG,FnF FDL 描述更灵活,满足更复杂的流水线场景。自带可视化降低了流程开发难度也增强了运行过程中的可观测性。
场景延伸
本文解决方案中, 训练和预测服务环节是通过 K8s 上的任务 (jobs) 和部署(deployments)实现的,K8s 集群是一种相对较重的资源,资源利用率低是常见的问题。函数工作流结合函数计算解决方案的一大优势是其极高的灵活性,例如下列的使用方式:
- FC 预测服务: 对于成本控制和资源利用率要求较高的用户,预测服务也完全可以以函数计算 HTTP 触发器的形式暴露,降低 K8s 集群 node 数量,实现 Serverless 的预测服务(参考文章 为你写诗:3 步搭建 Serverless AI 应用 以及 基于函数计算 + TensorFlow 的 Serverless AI 推理)。
- FC 模型训练:假设训练模型速度较快,且不需要使用 GPU 这类资源,训练任务也可以选择使用 FC 来实现,真正实现了 Serverless ML。
- FC 数据清洗,预处理 ETL:对于数据需要大规模并行清洗,或者 map-reduce 的场景,使用 FnF + FC 高效可靠地提供 ETL 数据清洗,预处理能力 (参考文章 使用函数工作流+函数计算轻松构建 ETL 离线数据处理系统)。
- 异构计算资源:FnF 中的训练步骤也可以由函数计算发起 弹性容器实例ECI 任务,或是提交到阿里云 PAI 机器学习平台。
更多排列组合,期待开发者的发掘。

联系我们
关于函数工作流或是函数计算有任何需求,反馈讨论,欢迎加入官方钉钉群:
函数工作流官网群
- 群号:23116481

函数计算官网群
- 群号:11721331

参考
- Hidden Technical Debt in Machine Learning Systems
- Why Not Airflow?
- 为你写诗:3 步搭建 Serverless AI 应用
- 基于函数计算 + TensorFlow 的 Serverless AI 推理
- 使用函数工作流+函数计算轻松构建 ETL 离线数据处理系统
- Train and serve a TensorFlow model with TensorFlow Serving
- Machine Learning Model Deployment: Strategy to Implementation
- 函数工作流产品详情
- 函数计算产品详情