PS:内容来自开源力量公开课第二十四期-为何Hadoop是分布式大数据处理的未来&如何掌握Hadoop?的文档,算做简单了解,想花时间好好了解hadoop!
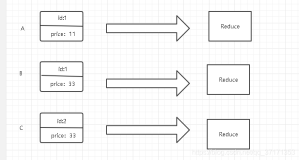
MapReduce原理1
问题:
求出以下数组当中最大的数
1,3,23,3,4,18,2,8,10,16,7,5
int Max(int a[], n)
{
int m=0;
for(int i=0; i<n; i++)
if(m<a[i]) m=a[i];
return m;
}
MapReduce原理2
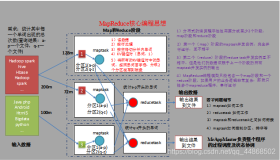
MapReduce是一种编程模型,用于大规模数据集的并行计算。

MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,通俗的说就是将一个大任务分成多个小任务并行完成,然后合并小任务的结果,得到最终结果。
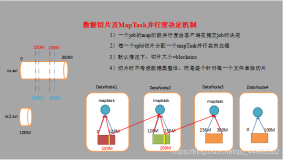
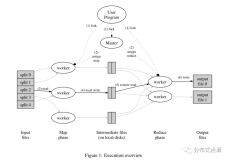
MapReduce运行过程
通过将Map调用的输入数据自动分割为M个数据片段的集合,Map调用被分布到多台机器上执行。输入的数据片段能够在不同的机器上并行处理。使 用分区函数将Map调用产生的中间key值分成R个不同分区。例如,hash(key) mod R),Reduce调用也被分布到多台机器上执行。分区数量(R)和分区函数由用户来指定。
加油

///静下心来读书……