Knative 中提供了自动扩缩容灵活的实现机制,本文从 三横两纵 的维度带你深入了解 KPA 自动扩缩容的实现机制。让你轻松驾驭 Knative 自动扩缩容。
注:本文基于最新 Knative v0.11.0 版本代码解读
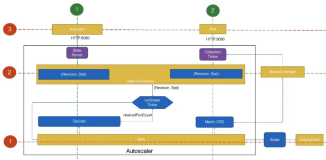
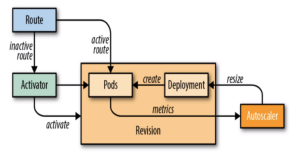
KPA 实现流程图

在 Knative 中,创建一个 Revision 会相应的创建 PodAutoScaler 资源。在KPA中通过操作 PodAutoScaler 资源,对当前的 Revision 中的 POD 进行扩缩容。
针对上面的流程实现,我们从三横两纵的维度进行剖析其实现机制。
三横
- KPA 控制器
- 根据指标定时计算 POD 数
- 指标采集
KPA 控制器
通过Revision 创建PodAutoScaler, 在 KPA 控制器中主要包括两个资源(Decider 和 Metric)和一个操作(Scale)。主要代码如下
func (c *Reconciler) reconcile(ctx context.Context, pa *pav1alpha1.PodAutoscaler) error {
......
decider, err := c.reconcileDecider(ctx, pa, pa.Status.MetricsServiceName)
if err != nil {
return fmt.Errorf("error reconciling Decider: %w", err)
}
if err := c.ReconcileMetric(ctx, pa, pa.Status.MetricsServiceName); err != nil {
return fmt.Errorf("error reconciling Metric: %w", err)
}
// Metrics services are no longer needed as we use the private services now.
if err := c.DeleteMetricsServices(ctx, pa); err != nil {
return err
}
// Get the appropriate current scale from the metric, and right size
// the scaleTargetRef based on it.
want, err := c.scaler.Scale(ctx, pa, sks, decider.Status.DesiredScale)
if err != nil {
return fmt.Errorf("error scaling target: %w", err)
}
......
}
AI 代码解读
这里先介绍一下两个资源:
- Decider : 扩缩容决策的资源,通过Decider获取扩缩容POD数: DesiredScale。
- Metric:采集指标的资源,通过Metric会采集当前Revision下的POD指标。
再看一下Scale操作,在Scale方法中,根据扩缩容POD数、最小实例数和最大实例数确定最终需要扩容的POD实例数,然后修改deployment的Replicas值,最终实现POD的扩缩容, 代码实现如下:
// Scale attempts to scale the given PA's target reference to the desired scale.
func (ks *scaler) Scale(ctx context.Context, pa *pav1alpha1.PodAutoscaler, sks *nv1a1.ServerlessService, desiredScale int32) (int32, error) {
......
min, max := pa.ScaleBounds()
if newScale := applyBounds(min, max, desiredScale); newScale != desiredScale {
logger.Debugf("Adjusting desiredScale to meet the min and max bounds before applying: %d -> %d", desiredScale, newScale)
desiredScale = newScale
}
desiredScale, shouldApplyScale := ks.handleScaleToZero(ctx, pa, sks, desiredScale)
if !shouldApplyScale {
return desiredScale, nil
}
ps, err := resources.GetScaleResource(pa.Namespace, pa.Spec.ScaleTargetRef, ks.psInformerFactory)
if err != nil {
return desiredScale, fmt.Errorf("failed to get scale target %v: %w", pa.Spec.ScaleTargetRef, err)
}
currentScale := int32(1)
if ps.Spec.Replicas != nil {
currentScale = *ps.Spec.Replicas
}
if desiredScale == currentScale {
return desiredScale, nil
}
logger.Infof("Scaling from %d to %d", currentScale, desiredScale)
return ks.applyScale(ctx, pa, desiredScale, ps)
}
AI 代码解读
根据指标定时计算 POD 数
这是一个关于Decider的故事。Decider创建之后会同时创建出来一个定时器,该定时器默认每隔 2 秒(可以通过TickInterval 参数配置)会调用Scale方法,该Scale方法实现如下:
func (a *Autoscaler) Scale(ctx context.Context, now time.Time) (desiredPodCount int32, excessBC int32, validScale bool) {
......
metricName := spec.ScalingMetric
var observedStableValue, observedPanicValue float64
switch spec.ScalingMetric {
case autoscaling.RPS:
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicRPS(metricKey, now)
a.reporter.ReportStableRPS(observedStableValue)
a.reporter.ReportPanicRPS(observedPanicValue)
a.reporter.ReportTargetRPS(spec.TargetValue)
default:
metricName = autoscaling.Concurrency // concurrency is used by default
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicConcurrency(metricKey, now)
a.reporter.ReportStableRequestConcurrency(observedStableValue)
a.reporter.ReportPanicRequestConcurrency(observedPanicValue)
a.reporter.ReportTargetRequestConcurrency(spec.TargetValue)
}
// Put the scaling metric to logs.
logger = logger.With(zap.String("metric", metricName))
if err != nil {
if err == ErrNoData {
logger.Debug("No data to scale on yet")
} else {
logger.Errorw("Failed to obtain metrics", zap.Error(err))
}
return 0, 0, false
}
// Make sure we don't get stuck with the same number of pods, if the scale up rate
// is too conservative and MaxScaleUp*RPC==RPC, so this permits us to grow at least by a single
// pod if we need to scale up.
// E.g. MSUR=1.1, OCC=3, RPC=2, TV=1 => OCC/TV=3, MSU=2.2 => DSPC=2, while we definitely, need
// 3 pods. See the unit test for this scenario in action.
maxScaleUp := math.Ceil(spec.MaxScaleUpRate * readyPodsCount)
// Same logic, opposite math applies here.
maxScaleDown := math.Floor(readyPodsCount / spec.MaxScaleDownRate)
dspc := math.Ceil(observedStableValue / spec.TargetValue)
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
logger.Debugf("DesiredStablePodCount = %0.3f, DesiredPanicPodCount = %0.3f, MaxScaleUp = %0.3f, MaxScaleDown = %0.3f",
dspc, dppc, maxScaleUp, maxScaleDown)
// We want to keep desired pod count in the [maxScaleDown, maxScaleUp] range.
desiredStablePodCount := int32(math.Min(math.Max(dspc, maxScaleDown), maxScaleUp))
desiredPanicPodCount := int32(math.Min(math.Max(dppc, maxScaleDown), maxScaleUp))
......
return desiredPodCount, excessBC, true
}
AI 代码解读
该方法主要是从 MetricCollector 中获取指标信息,根据指标信息计算出需要扩缩的POD数。然后设置在 Decider 中。另外当 Decider 中 POD 期望值发生变化时会触发 PodAutoscaler 重新调和的操作,关键代码如下:
......
if runner.updateLatestScale(desiredScale, excessBC) {
m.Inform(metricKey)
}
......
AI 代码解读
在KPA controller中设置调和Watch操作:
......
// Have the Deciders enqueue the PAs whose decisions have changed.
deciders.Watch(impl.EnqueueKey)
......
AI 代码解读
指标采集
通过两种方式收集POD指标:
- PUSH 收集指标:通过暴露指标接口,外部服务(如Activitor)可以调用该接口推送 metric 信息
- PULL 收集指标:通过调用 Queue Proxy 服务接口收集指标。
PUSH 收集指标实现比较简单,在main.go中 暴露服务,将接收到的 metric 推送到 MetricCollector 中:
// Set up a statserver.
statsServer := statserver.New(statsServerAddr, statsCh, logger)
....
go func() {
for sm := range statsCh {
collector.Record(sm.Key, sm.Stat)
multiScaler.Poke(sm.Key, sm.Stat)
}
}()
AI 代码解读
PULL 收集指标是如何收集的呢? 还记得上面提到的Metric资源吧,这里接收到Metric资源又会创建出一个定时器,这个定时器每隔 1 秒会访问 queue-proxy 9090 端口采集指标信息。关键代码如下:
// newCollection creates a new collection, which uses the given scraper to
// collect stats every scrapeTickInterval.
func newCollection(metric *av1alpha1.Metric, scraper StatsScraper, logger *zap.SugaredLogger) *collection {
c := &collection{
metric: metric,
concurrencyBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
rpsBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
scraper: scraper,
stopCh: make(chan struct{}),
}
logger = logger.Named("collector").With(
zap.String(logkey.Key, fmt.Sprintf("%s/%s", metric.Namespace, metric.Name)))
c.grp.Add(1)
go func() {
defer c.grp.Done()
scrapeTicker := time.NewTicker(scrapeTickInterval)
for {
select {
case <-c.stopCh:
scrapeTicker.Stop()
return
case <-scrapeTicker.C:
stat, err := c.getScraper().Scrape()
if err != nil {
copy := metric.DeepCopy()
switch {
case err == ErrFailedGetEndpoints:
copy.Status.MarkMetricNotReady("NoEndpoints", ErrFailedGetEndpoints.Error())
case err == ErrDidNotReceiveStat:
copy.Status.MarkMetricFailed("DidNotReceiveStat", ErrDidNotReceiveStat.Error())
default:
copy.Status.MarkMetricNotReady("CreateOrUpdateFailed", "Collector has failed.")
}
logger.Errorw("Failed to scrape metrics", zap.Error(err))
c.updateMetric(copy)
}
if stat != emptyStat {
c.record(stat)
}
}
}
}()
return c
}
AI 代码解读
两纵
- 0-1 扩容
- 1-N 扩缩容
上面从KPA实现的 3个横向角度进行了分析,KPA 实现了0-1扩容以及1-N 扩缩容,下面我们从这两个纵向的角度进一步分析。
我们知道,在 Knative 中,流量通过两种模式到达POD: Serve 模式和 Proxy 模式。
Proxy 模式: POD数为 0 时(另外针对突发流量的场景也会切换到 Proxy 模式,这里先不做详细解读),切换到 Proxy 模式。
Serve 模式:POD数不为 0 时,切换成 Serve 模式。
那么在什么时候进行模式的切换呢?在KPA中的代码实现如下:
mode := nv1alpha1.SKSOperationModeServe
// We put activator in the serving path in the following cases:
// 1. The revision is scaled to 0:
// a. want == 0
// b. want == -1 && PA is inactive (Autoscaler has no previous knowledge of
// this revision, e.g. after a restart) but PA status is inactive (it was
// already scaled to 0).
// 2. The excess burst capacity is negative.
if want == 0 || decider.Status.ExcessBurstCapacity < 0 || want == -1 && pa.Status.IsInactive() {
logger.Infof("SKS should be in proxy mode: want = %d, ebc = %d, PA Inactive? = %v",
want, decider.Status.ExcessBurstCapacity, pa.Status.IsInactive())
mode = nv1alpha1.SKSOperationModeProxy
}
AI 代码解读
0-1 扩容
第一步:指标采集
在POD数为0时,流量请求模式为Proxy 模式。这时候流量是通过 Activitor 接管的,在 Activitor 中,会根据请求数的指标信息,通过WebSockt调用 KPA中提供的指标接口,将指标信息发送给 KPA 中的 MetricCollector。
在 Activitor 中 main 函数中,访问 KPA 服务 代码实现如下
// Open a WebSocket connection to the autoscaler.
autoscalerEndpoint := fmt.Sprintf("ws://%s.%s.svc.%s%s", "autoscaler", system.Namespace(), pkgnet.GetClusterDomainName(), autoscalerPort)
logger.Info("Connecting to Autoscaler at ", autoscalerEndpoint)
statSink := websocket.NewDurableSendingConnection(autoscalerEndpoint, logger)
go statReporter(statSink, ctx.Done(), statCh, logger)
AI 代码解读
通过 WebSockt 发送请求指标代码实现:
func statReporter(statSink *websocket.ManagedConnection, stopCh <-chan struct{},
statChan <-chan []autoscaler.StatMessage, logger *zap.SugaredLogger) {
for {
select {
case sm := <-statChan:
go func() {
for _, msg := range sm {
if err := statSink.Send(msg); err != nil {
logger.Errorw("Error while sending stat", zap.Error(err))
}
}
}()
case <-stopCh:
// It's a sending connection, so no drainage required.
statSink.Shutdown()
return
}
}
}
AI 代码解读
第二步:根据指标计算 POD 数
在 Scale 方法中,根据 PUSH 获取的指标信息,计算出期望的POD数。修改 Decider 期望 POD 值,触发 PodAutoScaler 重新调和。
第三步:扩容
在KPA controller中,重新执行 reconcile 方法,执行 scaler 对当前Revision进行扩容操作。然后将流量模式切换成 Server 模式。最终实现 0-1 的扩容操作。
1-N 扩缩容
第一步:指标采集
在 POD 数不为0时,流量请求模式为 Server 模式。这时候会通过PULL 的方式访问当前 revision 中所有 POD queue proxy 9090 端口,拉取业务指标信息, 访问服务 URL 代码实现如下:
...
func urlFromTarget(t, ns string) string {
return fmt.Sprintf(
"http://%s.%s:%d/metrics",
t, ns, networking.AutoscalingQueueMetricsPort)
}
AI 代码解读
第二步:根据指标计算 POD 数
在 Scale 方法中,根据 PULL 获取的指标信息,计算出期望的POD数。修改 Decider 期望 POD 值,触发 PodAutoScaler 重新调和。
第三步: 扩缩容
在 KPA controller中,重新执行 reconcile 方法,执行 scaler 对当前Revision进行扩缩容操作。如果缩容为 0 或者触发突发流量场景,则将流量模式切换成 Proxy 模式。最终实现 1-N 扩缩容操作。
总结
相信通过上面的介绍,对Knative KPA的实现有了更深入的理解,了解了其实现原理不仅有助于我们排查相关的问题,更在于我们可以基于这样的扩缩容机制实现自定义的扩缩容组件,这也正是 Knative 自动扩缩容可扩展性灵魂所在。
欢迎加入 Knative 交流群