阿里云InfluxDB®是一版免运维,稳定可靠,可弹性伸缩的在线时序数据库服务,目前围绕InfluxDB的TIG(Telegraf/InfluxDB/Grafana)生态和高可用服务版本已经商业化,可以在阿里云官网直接购买。在日常业务中,用户会比较关心两个问题:
- 实例故障后,之前写的数据会丢吗?
- 你的服务能提供不间断服务吗,实例故障后能不能迅速恢复?
对于问题1,阿里云InfluxDB®底层采用了自研盘古分布式存储系统,保证了数据99.9999999%的高可靠性;并且InfluxDB采用WAL机制来保障恢复重启实例中cache的写入数据;
对于问题2,目前阿里云InfluxDB®采用了基于raft一致性协议的三副本机制,当其中某个节点故障之后保证能够持续提供数据写入、查询服务。
高可用相对于单机版本,能提供更高服务SLA保障。本文接下来也主要针对阿里云InfluxDB®高可用设计和Raft协议内部原理展开具体描述。
高可用架构设计
数据服务高可用目前似乎是软件设计必要考虑要素。在实际的工程实践中,基于需求有各种不同的解决方案,如SQL Server的share everything;Oracle RAC的share storage;GPDB/Spanner的share nothing架构;最近,基于kubenetes容器编排技术的高可用方案也越来越受欢迎。
Share everything/storage架构方案一般会被具有资深研发背景的数据库厂商采用;在大部分互联网初创公司或者数据库产品发展的早期技术栈中,share nothing的分布式架构使用比较广泛,它利用多副本机制来保障服务的可靠性,某个节点出现故障时,能迅速切换到备用节点继续提供服务;容器编排技术通过将服务资源进行统一封装管理,当节点故障之后能够快速拉起继续提供服务。
阿里云InfluxDB®的高可用架构设计中,也充分调研了各种技术方案:
一、基于共享存储:各个实例通过挂载共享存储,共享存储在节点故障时不需要数据迁移,可以即时拉起,目前在计算存储分离架构中运用比较多。对于有状态的共享存储服务,常常需要解决用户态文件缓存和内存cache数据同步问题,也要避免写文件冲突,需要引入类似GFS的分布式文件系统,实现比较复杂。
二、Share nothing技术方案:Share nothing的各副本之间分为有角色管理和无角色管理两种。为了保证各个副本数据一致以及事务之间的隔离性,两种技术方案在实现细节上有较大的不同。
- 无角色管理:无角色管理较为经典的有Dynamo的NWR模型,也称写多数协议,即在N个副本中需要至少写W个副本才能标记写入成功;对于读操作一样,查询次数R要保证R>N-W,从R份查询结果中找出数据的最新版本返回。NWR协议存在储存脏数据问题,InfluxDB Enterprise通过Anti-Entropy Repair技术对各个副本定期扫描修复来实现数据的最终一致性,但实现复杂度比较高,具有高延迟和高资源消耗。
- 有角色管理:在左耳朵耗子的<分布式系统的事务处理>中,副本之前的角色主要分为M/S, M/M, Leader-Fellower等。M/S, M/M之间通过异步复制保证数据一致性,M/S需要容忍节点间延迟以及故障恢复时服务的短暂中断;M/M需要解决对同一条记录更新的写写冲突,需要引入逻辑时钟或者分布式锁的概念,技术难度高。
在分布式协议发展的后期,为了实现故障恢复时Master、Slave之间角色的自动轮转,实现了Paxos与Raft协议。本人觉得两阶段提交的Paxos与Raft协议同属于一个技术栈,Raft协议相对来说更易理解,在Go技术栈中运用更为广泛,故选取了Raft一致性协议来实现高可用副本之间数据的一致性问题。Raft协议的具体选举算法可以参考Paper<In Search of an Understandable Consensus Algorithm>以及译文<Raft一致性算法论文译文>。Raft协议通过先写数据操作日志,然后回放Apply操作来保证各个节点间数据的一致性。为了保证各个副本角色切换后Raft日志的一致性,Raft在日志写入和匹配的时候保证了以下特性:
- 如果在不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
- 如果在不同日志中的两个条目有着相同的索引和任期号,则它们之间的所有条目都是完全一样的。
第一条保证了任意一条日志的索引位置创建后不会改变;第二条保证了新的Leader被选举后,日志追加写入时,其它Fellower节点需要检查保证与Leader节点日志一致。时序的应用场景中,在有大量写入的业务中,需要保证写入节点不可用之后服务快速恢复,作为公有云服务,保证写入数据不丢失和查询的最终一致性,并且Raft实现比较轻量,最终我们采用了Raft这一开源的分布式协议。
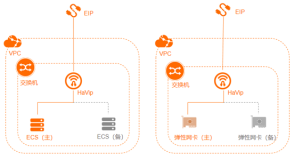
阿里云InfluxDB®高可用方案

如上图所示,阿里云InfluxDB的高可用架构侧重于AP,对于数据/元数据的写和更新,采用Raft一致性协议;为缩短查询流程,读采用了弱一致性。
- 元数据更新:为避免元数据脏写以及数据库元信息与实际数据不对称,元数据更新采用了串行执行的方案,apply之前必须保证其它所有操作Apply结束才进行元数据修改。
- 时间点写入更新:为尽量减少节点间数据同步对写入吞吐的影响,考虑到时间点数据较少存在写冲突,对于时间点的写入采用了并发apply模型。当前节点接收到数据之后会同步到leader节点,序列化raft entry log。raft内部通信模块将这些entry log以message的方式批量同步到各个节点apply执行。当前阿里云InfluxDB®在请求接收点和master节点apply成功后便返回给客户端。
数据查询:数据查询类操作为缩短执行流程,采用了弱一致性方案,没有走raft流程,在请求节点执行成功后便返回给客户端。
Raft一致性协议
关于raft的选举算法,在各篇文章中有详细的介绍,这里便不再做具体描述,下面主要介绍raft数据写入流程和数据存储策略。
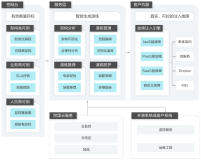
raft数据写入流程

数据写入流程如上图所示:
- 若接收请求的节点(A)为follower节点,首先会将请求以message的形式发送到leader节点(B);
- leader节点(B)收到请求的raft entry log后,会将log序列化写入存储中;
- leader节点(B)raft内部的决策系统会轮循当前节点状态和log同步进度,定期将raft log以批量的方式同步到fellower节点(A/C);
- fellower节点(A/C)收到leader节点(B)推送的数据后也会将entry log序列化存储,并更新同步状态,处理完后回复leader节点(B);
- 当leader节点收到所有fellower节点数据同步完成之后更新commit index并回复propose节点(A);
- 各节点的raft模块并发扫描本地raft log entry 执行;
- 请求节点(A)apply 执行完成后返回给客户端。
raft storage
raft storage用于存储raft log entry,raft log由以下成员组成:
- storage :存放已经持久化数据的storage接口,append数据将在此保存。
- unstable ents:unstable结构体,用于保存应用层还没有持久化的数据。
- committed index:保存当前提交的日志数据索引。
- applied index:保存当前传入状态机的数据最高索引,索引之前的数据操作均已apply。
- firstIndex: 保存了snapshot之后active raft log第一条日志的索引。
- lastIndex: 保存了应用层持久化后的最后一条日志的索引。
- unstable.offset:为lastIndex索引的下一个索引值。

replicate时,如果next标记的索引值介于snapshot和unstable.offset之间(firstIndex<=next<=lastIndex),则从leader的持久化日志中读取entry进行同步;接着unstable ents也会发送到应用层storage中进行持久化;当storage持久化日志数据之后,便根据apply和commit信息进行回放数据操作。
阿里云InfluxDB®为了实现raft log的持久化和故障可恢复,采用了自研的hybrid storage方案,详细可以参考<阿里云InfluxDB® Raft HybridStorage实现方案>。
总结
本文主要从工程实践的角度出发,介绍了阿里云InfluxDB®高可用架构的实现以及raft内部机制。为了提高用户服务的SLA,当前阿里云InfluxDB®高可用版本已经商业化,技术方案也在不断的演进中。未来,我们将在降低使用成本、提高性能方面做进一步提升,希望对阿里云InfluxDB®或者高可用技术感兴趣的同学能一起交流,共同打造一款服务能力更强、价格更低的阿里云InfluxDB®时序数据库产品。