阿里云技术总监/研发总监陈一宁博士通过直播分享了《阿里云智能语音交互技术实践》。他首先介绍了智能语音面临的技术挑战,然后对智能语音技术做了详细介绍。其中,他主要分享了阿里云使用的BLSTM & LFR声学模型的优化过程,并对基于深度学习的自然语言理解的不同场景进行了详细分享。
以下内容根据直播视频整理而成。
阿里云智能语音概述
阿里云智能语音交互=语音+自然语言处理,语音包括语音识别、语音合成、声纹等,自然语言处理包括自然语言理解、对话系统、问答系统等。阿里云智能语音团队不是一个简单的算法团队,其把算法包装成引擎提供服务,在引擎之上有离线的pipeline与在线服务,在此之上包装成各种各样的产品对终端客户提供服务。阿里云主要是以to B为主的企业,会做很多to B对应的工作。
智能语音技术挑战
在阿里集团内部,优势是大量的数据,强大的计算能力,优秀的人才队伍;挑战是大量的业务,受限的人力。在公共云服务上遇到的挑战是个性化的需求和公共云服务之间的矛盾。
上图列举了一些阿里云语音能力支撑内部客户需求的一些场景,包括了客服类的产品等。
阿里集团内部技术的挑战
首先,大量的、多种多样的业务,要求阿里云平台化发展,Scale永远是一个问题,体现在采样率包括8K、16K,录音设备包括电话、手机、演讲、车载、智能设备,场景上包括天猫魔盒、手机淘宝、蚂蚁电话客服。在这种情况下,在阿里云内部形成了天生的ISV模式,即提供基础的能力赋能给业务合作伙伴,和业务团队共同成长。
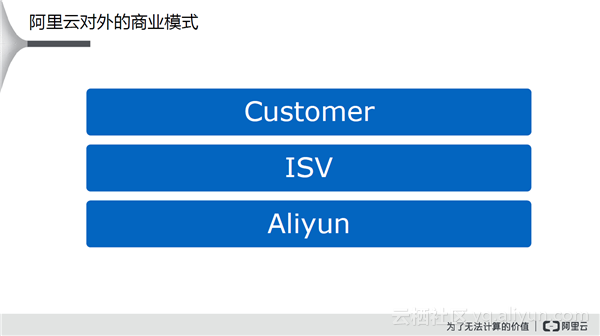
阿里云不会直接面对终端客户,一般都是通过合作伙伴对外提供服务,合作伙伴会对产品做进一步的包装,封装成对应的自己的产品,满足客户的需求。这样,阿里云就可以用一个核心的引擎服务各种各样的用户。
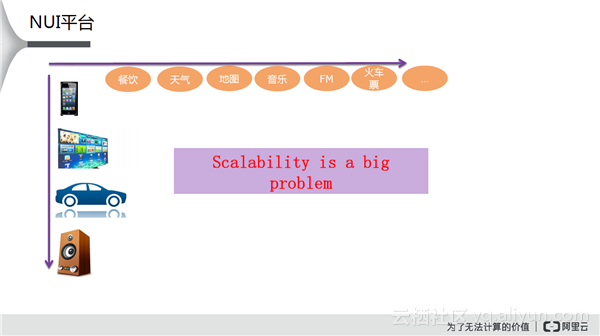
对于自然语言处理,必须要对语音做深入的理解。上图中横向是各种领域,纵向上各种不同的业务也会对自然语言理解有不同的要求。比如在车载环境就必须解决离线的问题。
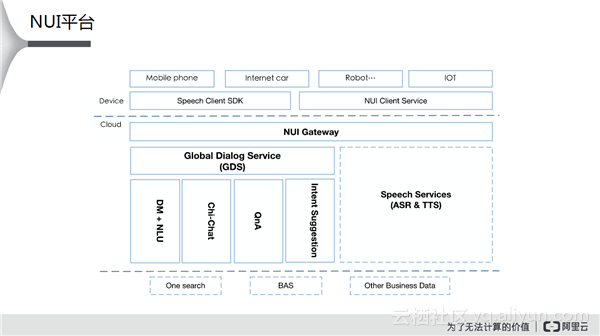
NUI平台架构如上图所示,最右端是Speech Services,总的来看是一个基础的架构。最上方是一些SDK等端上的服务,通过这些服务就可以服务不同的场景。
阿里云智能语音技术详解
语音识别
模型训练的Infrastructure
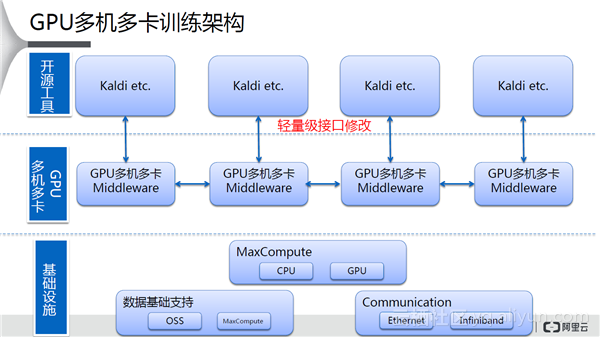
上图展示了GPU多机多卡训练架构,GPU多机多卡架构在深度学习中非常常见。阿里云将GPU多机多卡抽象了一层中间件,通过这个中间件把开源工具文件的读写、通讯之类的接口改写掉。最下方是一些基础设施,MaxCompute进行计算(CPU、GPU统一进行管理),在通信方面以太网和Infiniband均使用,数据可以存储在OSS或者MaxCompute上。
GPU Middleware功能特点包括:提供了API接口使得我们可以通过对训练工具的简单修改实现并行训练;具有灵活性,自主管理任务队列、数据分发、通信、同步等;Master-slave模式, 支持MA / SGD / ASGD等;不同GPU间通过API直接快速通信。
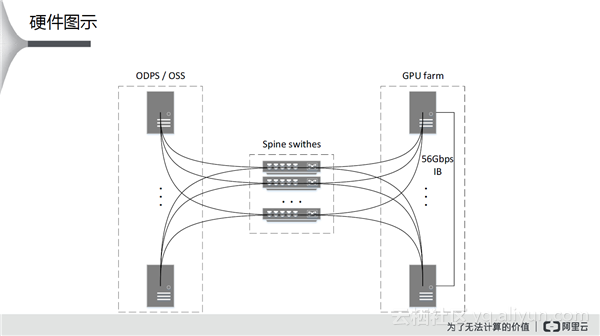
硬件图是如上图所示,右边是GPU集群,集群之间通过Infiniband进行连接。集群和左边存储节点之间由超级交换机来连接。在实际的操作过程中,GPU集群的存储能力比较差,整体的做法是:当需要数据的时候,就从存储节点拉下来使用,用完之后再删掉,通过不断的交换来保证不会等待。
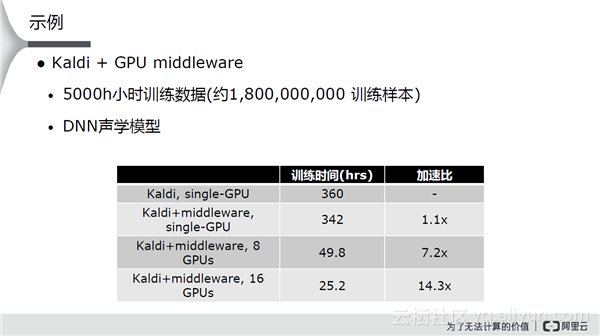
举个例子,比如使用Kaldi + GPU middleware,不管是8 GPUs还是16 GPUs,加速比和全量相比没有太大的差异。
BLSTM & LFR
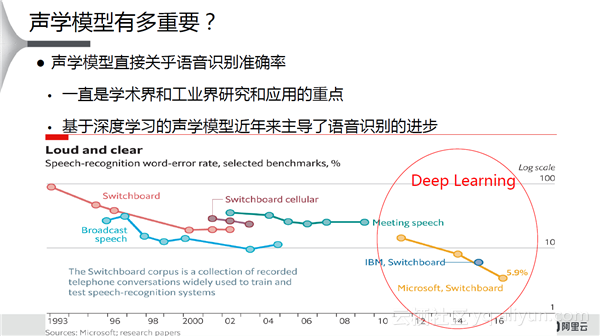
从上图中可以看出,声学模型对于语音识别的准确率提高有至关重要的作用。不论是工业界还是学术界,在声学模型方面都做了大量的工作。近些年来,基于深度学习的声学模型主导了语音识别的进步。阿里云使用了双向的LSTM,2015年12月上线所有客服业务,全世界第一个产品落地;2016年3月阿里云年会实时字幕,是BLSTM全世界第一个实时业务落地。
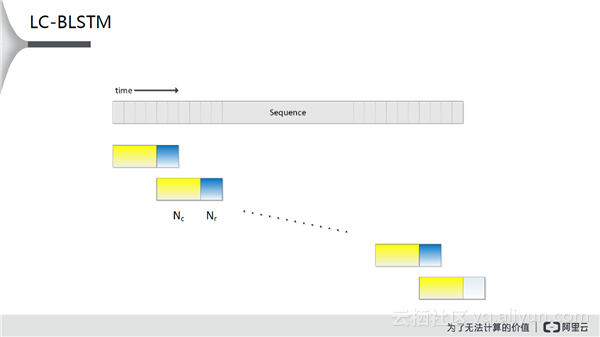
LC-BLSTM,Latency control是要使双向的LSTM反向部分的时延变得可控。在操作过程中分为两段,中间表示实际运算的部分,蓝色部分是用来计算反向的BLSTM的信息,这样就不用需要看到整句的所有信息,可以通过BLSTM数据训练得到很好的近似。
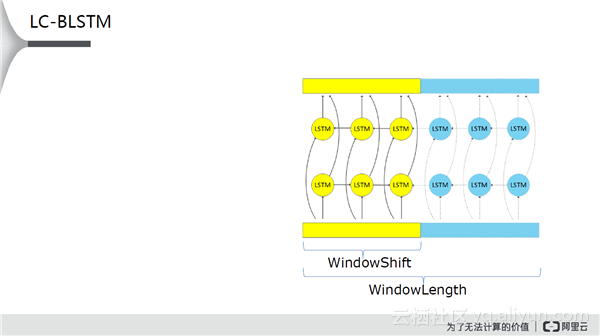
从上图中可以看出, WindowLength中的所有数据都用来计算,但是最终有效产出的是黄色部分WindowShift。
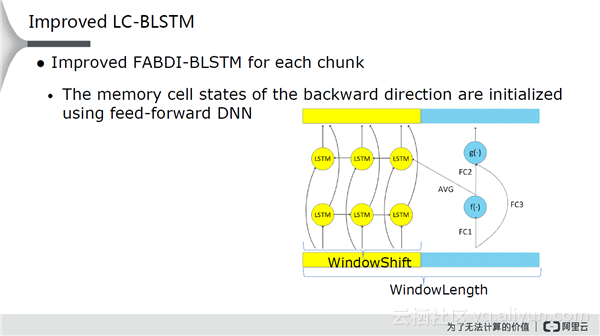
其实,蓝色的部分没有别的用处,只是帮助黄色部分最右边的节点初始化了其状态信息,对其传送的状态做了重新设定。所以,可以用一个更简单的模型来做(因为只需要做初始化)。即使用Full Connect网络+非线性函数做模型,对这个网络进行初始化,由于是多层的LSTM,所以上方需要做近似,在原先的网络基础上再加一层,或者跳过刚才的网络直接从底层预测上去。
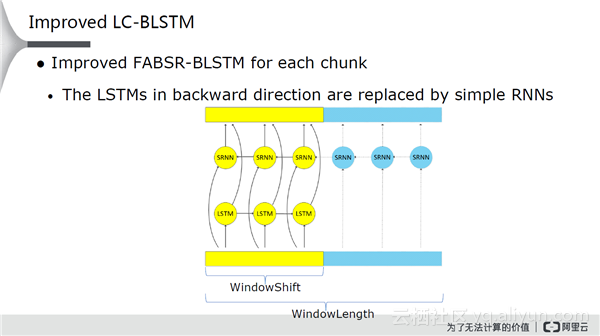
更进一步,反向的LSTM直接使用RNN,简单的RNN可以使运算量有很好的提升。优点是只在WindowLength内部使用RNN,即使出现问题也不会传播很远,对梯度等进行控制可以有效避免出现问题。
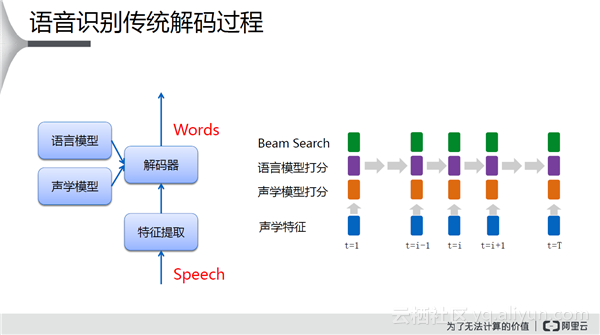
上图回顾了语音识别解码的过程,有一个传统观点:短时平稳信号做短时傅里叶变换,帧移是10ms,帧长是20ms或者25ms,这是一个标准的模式。
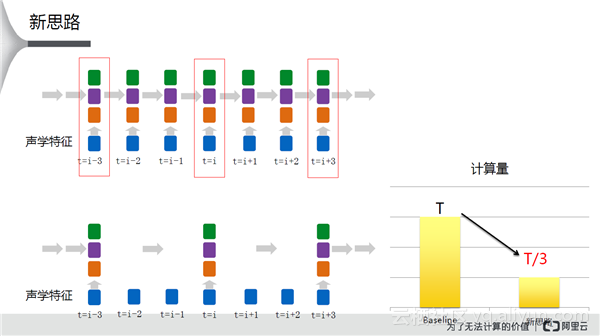
新的思路是,每3帧抽取一次特征做语音识别,立竿见影的好处是运算量变为原来的三分之一。但是,测试结果表明,错误率发生了明显的提升。出现这种情况的原因是,中间两帧的信号完全没有使用,对于语音的完整性有损伤,特征不足不能得到一个很好的识别率。
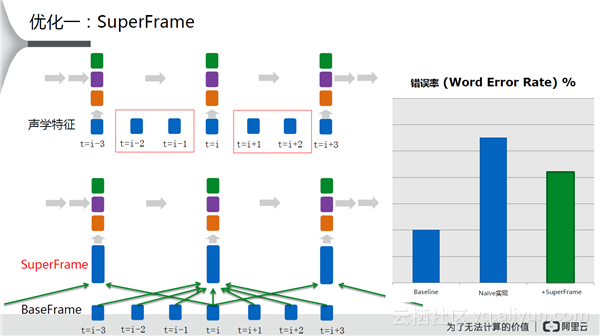
第一种优化是将帧加长,如上图所示做了一个SuperFrame。超长帧可以描述更多的语音信息,这样就可以得到一个比较好的识别效果。
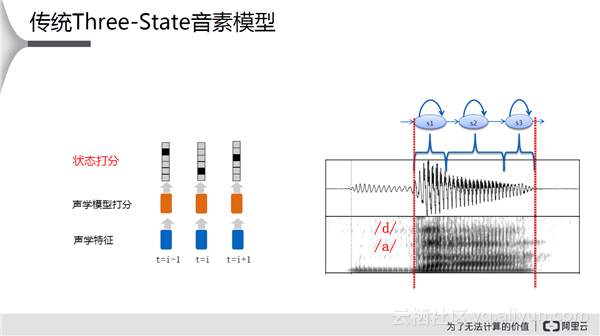
传统的一个Phone、三个State是一个经典的做法,可能分到一个State上的帧会很少。因此对应的想法是, 将一个Phone用一个State来表示, 或者去掉State信号直接用Phone, 结果是错误率有进一步的减小。
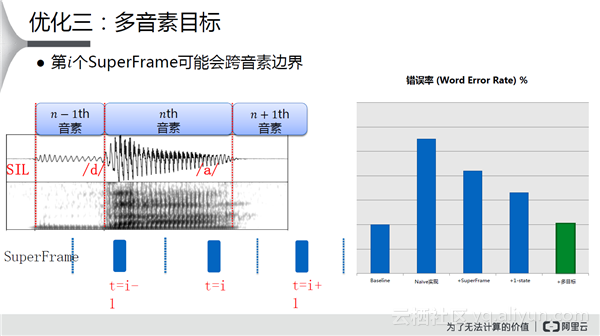
在此基础上,发现30ms太容易跨越一个因素的边界了,对多目标进行优化,识别率和原先方法区别不大,而且速度提升了三倍。
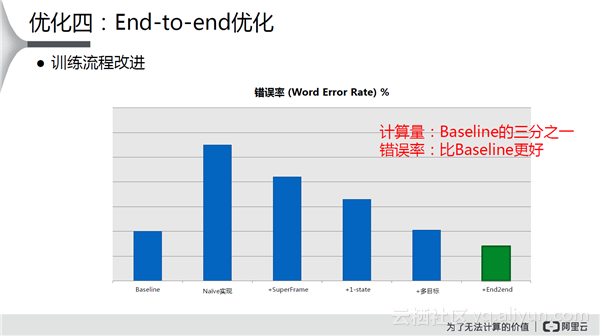
其实可以上来直接做SuperFrame,直接走训练过程,把三个状态直接变成一个状态,可以避免中间做一层一层变化带来的潜在的各种问题。得到最终的End-to-end效果计算量为BaseLine的三分之一,错误率比BaseLine更好。
模型的鲁棒性与个性化
提高模型鲁棒性的方法是训练更多的数据,具体过程包括:数据筛选(删去重复的、没有必要的数据)、+加性噪声、+乘性噪声(模拟不同场景信道情况)、+快语速数据、进行模型训练测试和与结果分析。
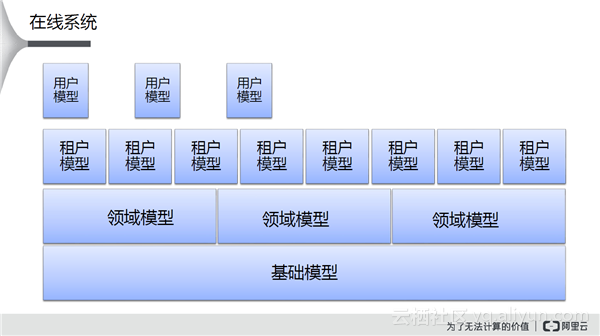
即使完成上述操作,模型已经相当鲁棒了,但是在真实的情况下,每个租户都有自己的需求,而且是五花八门的。所以,在基础模型会摞上领域模型,在其上摞上租户模型,在其上摞上用户模型。
自然语言处理
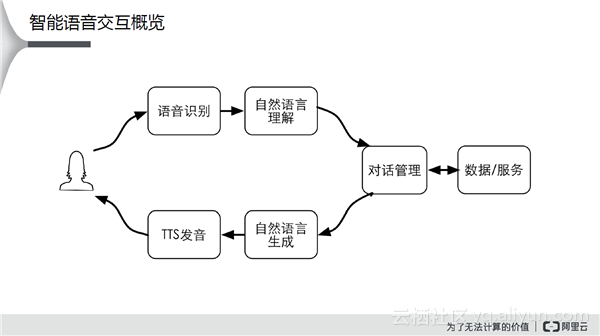
上图是人机交互的经典图,首先进行语音识别,然后自然语言理解,接着对话管理,最后进行服务。最终的结果分为两种情况:面向Task的对话,用户主动,聊天,机器主动。阿里更多是面向Task的对话,这与其To B的业务模式有关。面向Task意味着有多个领域、多个场景。如何做呢?答案是做云+端有机协同的NUI平台(前文已提到,这里不再赘述)。
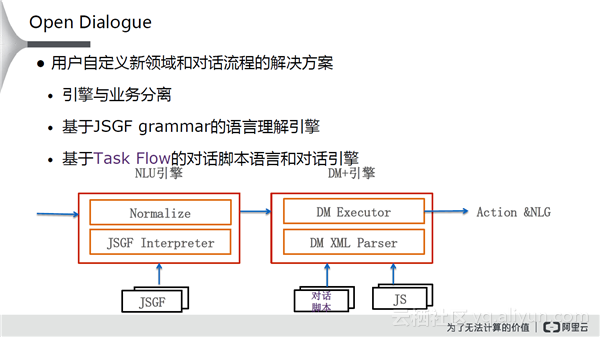
这个平台里比较核心的内容是Open Dialogue。里面有两个重要的部分:JSGF(理解),对话部分(执行对话)。当一个文本进来之后,需要理解其属于哪一个Intention,从Intention中将内容抽出来,根据内容做各种各样的操作,然后拿外部数据、JS脚本来执行。Open Dialogue的核心能力包括:语言理解能力,基于语法脚本和深度学习模型的语言理解,内置时间/地点/数量词组件公共属性的抽取组件,内置确认/取消/下一页等公共意图的处理组件;对话能力,用脚本驱动对话逻辑,支持自定义打断和恢复机制;平台能力,提供运行脚本的引擎和服务,统一部署和监控,日志采集和数据回流。
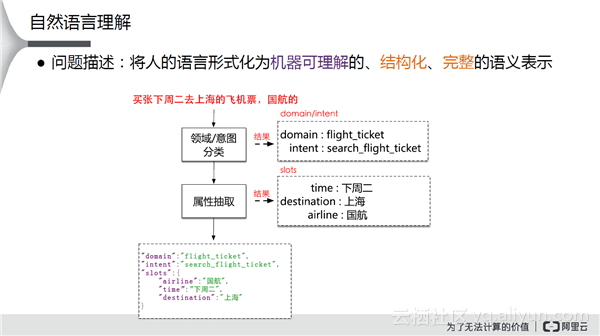
上图是一个很常见的面向任务的自然语言理解任务。我们首先需要进行分类其属于的领域(飞机票领域),Intend是搜索机票,抽取里面的属性(包括时间、目的地、航空公司选择)。实际应用中碰到的问题比较多:多样性的挑战、鲁棒性的挑战、歧义性。
基于深度学习的自然语言理解
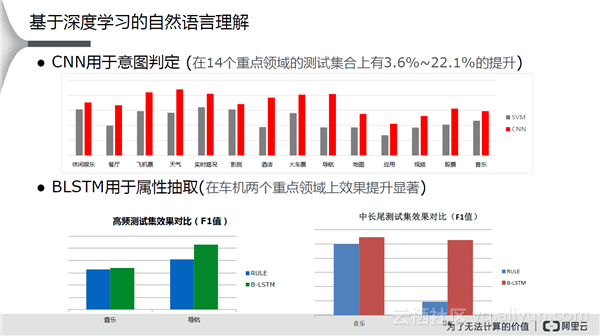
在已知的领域上基本都采用深度学习的方式来做自然语言理解。在意图判定上基本都是采用CNN的方式来判定,在属性抽取上基本采用BLSTM的方式。
对话引擎
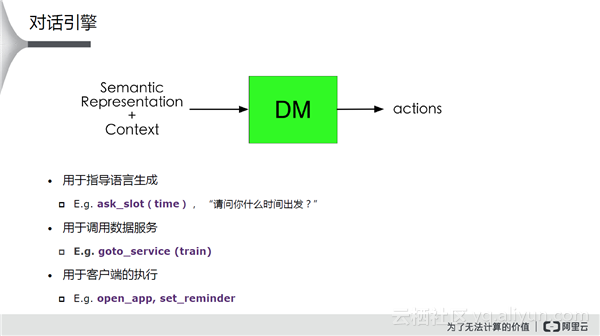
理解只是对话的第一步,在此基础上会做很多对话的管理。对话的管理可以通过云端生成、调一个服务、让客户端做执行的工作。在整个对话的脚本语言里面,阿里云想解决的一个问题是任务之间切换的问题,即做任务边界的划分。基于Task Flow的对话脚本语言描述了任务的起始、中间步骤、扭转和结束,可以指导上述工作。
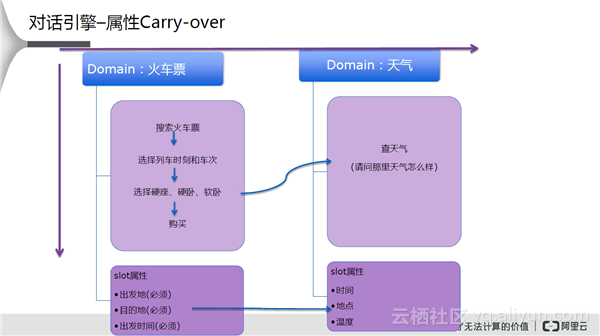
上图是一个典型案例,其中涉及到了属性的Carry-over,当搜索火车票的时候选择目的地、车次、时刻、购买,是一个正常的流程。中间过程中可能突然关心到天气状况。其实,问到目的地的时候,这些信息已经有了,就可以直接带入后一个问题中获得目的地的天气状况。此外,对于任务的打断和返回,我们希望的是之前问过的信息仍然存在。
问答引擎
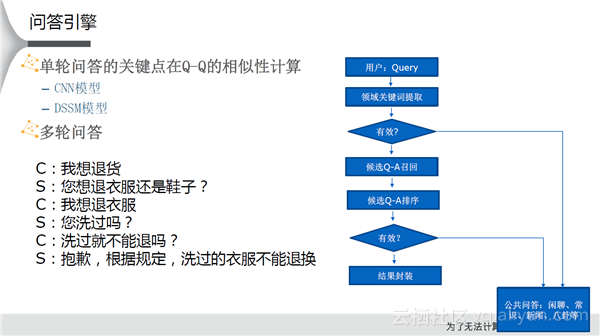
在问答领域,单轮问答是最常见的场景,其关键点在于Q-Q的相似性计算。当一个Question进来之后,我们在库里面找到一个相似的问题,将其返回去作为有效的结果。其中,CNN、BLSTM方法都会用到。右图的流程图是一个比较古老的方式,实际使用的过程中发现上述流程并不是非常有效的。因为真实用户如果是一个自由提问的场景,那么Query一般比较长,很难通过抽取关键词进行匹配,使得识别效果差很多,所以现在一般是直接在库里面做相似度计算。多轮问答也是比较典型的场景,比如退货的场景,同样可以通过Open Dialog的方式完成任务。用户可以指定自己的客服领域。
聊天引擎
阿里云也做了聊天引擎,其是基于<k,v>对的聊天引擎,具备让用户定制的能力,并且是基于深度学习模型的seq2seq聊天引擎,解决的问题包括:非任务性(如chat)的query占比60%左右;基于key-value的聊天模块无法对用户的任意chat输入都能够给出回复。
NUI平台定制能力
总结来说,NUI的定制能力包括:业务领域的语言理解Grammar、业务领域的对话过程、真实情况下可以做卡片和文本展示方式、问答系统。


