大数据开发套件里可以通过配置同步任务,实现数据在不同数据源之间的迁移。但是因为目前只部署在华东1(参考文档),有一些特殊网络环境可能无法覆盖到。比如VPC下的DRDS或者其他区域自建数据库内网就不通了。不过套件还提供了脚本模式+调度资源设置这2个大杀器,满足各种复杂场景下的数据同步功能。
本文就数据从MaxCompute的数据导出到VPC下的DRDS为例,详细介绍如何使用这两种方法来实现灵活的数据同步。
同步原理
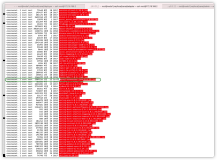
首先介绍下大数据开发套件的同步任务是怎么做的。![]()
(这个图片来自这里)
常有人以同步是MaxCompute的功能,其实MaxCompute和DRDS、RDS一样只是一种数据源。图片中间的框框是一个数据同步服务,它有一个Reader和一个Writer配置,通过Reader从来源抽取数据,然后用Writer写到目标数据源上。
如果有各种网络通不通的问题,其实就是来源数据源到同步服务通不通,以及同步服务到目标数据源通不通两个问题。大数据开发套件提供了一个数据同步的服务,部署在华东1,所以也就有了前文提到的华东1的说法。在这种场景下,就需要考虑华东1的同步集群到来源数据源和目标数据源通不通。因为本文的例子里,虽然MaxCompute和同步集群虽然是通的,但是在华北2的VPC下的DRDS内网是不通,所以就有了同步不了的尴尬情况。
除了用大数据开发套件提供的同步服务集群外,也可以用直接的自己的ECS来做同步,那这样的问题就变成了来源数据源和目标数据源这两个数据源和自己的ECS通不通的问题了。这时候就可以通过安全组设置、高速通道等方法,实现数据的同步。而且这样防火墙等安全设置自主可控,用户自己排查网络问题也比较方便。本文就是用这种方法实现把数据写入到华北2的VPC内的DRDS的。为了能够和华北2的VPC内的DRDS能很好的内网连接,我使用华北2的VPC下的ECS来做调度资源。
DRDS的配置
DRDS没有做特殊的设置,只是说明下情况:它是在华北2的VPC里,里面的数据表是做了分库的。
需要特殊说明的是,这里因为VPC下的DRDS目前不支持设置白名单,所以本文不涉及白名单的部分。但是如果是其他的数据源(比如自建Mysql),需要看同步服务是什么。如果是用大数据开发套件默认的同步集群,需要参考文档设置白名单或者在防火墙/安全组等安全设置上开放这些IP的访问。如果是用自己的ECS做的调度资源,那只需要开放自己的ECS的IP给数据源,保证数据源和ECS之间是通的,系统的IP就可以不设置。只是如果因为用自己的ECS调度,没有开放系统的那些IP的话,可能在用模板模式配置任务的时候可能会有问题(比如本文如果用模板模式的话会在DRDS数据源里获取数据库下的表的列表的时候出现连接不通的情况),这时候就切换成脚本模式,直接修改同步脚本即可。
DRDS购买成功后,我从DMS登录到数据库上,使用
create table user_pay(
user_id varchar(100),
shop_id varchar(100),
time_stamp timestamp) ;在DRDS里创建好表。
ECS的配置
我的ECS是新购买的,购买时选择了和DRDS一样的专有网络和虚拟交换机,使得DRDS和ECS内网能通。另外我设置了公网IP,准备通过公网从MaxCompute获取数据。
调度资源
机器购买成功后需要配置这台ECS,让大数据开发套件知道这台机器可以用来做调度资源。到调度资源列表里创建一个调度资源,添加一台ECS
数据源
创建数据源的步骤也只是跟着文档配置,没太多需要注意的。因为VPC下的DRDS不需要设置白名单,所以这里也省了一步。如果是其他数据源,注意对配置处提示的IP添加白名单放行。
任务配置
接下来是最重要的同步脚本编写。到数据集成页面创建一个任务,直接使用脚本模式。选择好数据是从Odps导入到DRDS后,得到一个模板(模板自动生成的,这里就不再写拷一次)。
填上实际的业务数据后,变成
{
"configuration": {
"setting": {
"speed": {
"mbps": "1"
}
},
"reader": {
"parameter": {
"partition": "",
"column": [
"*"
],
"table": "user_pay",
"datasource": "maxcompute_ds"
},
"plugin": "odps"
},
"writer": {
"parameter": {
"writeMode": "replace",
"preSql": [
"delete from user_pay;"
],
"column": [
"user_id",
"shop_id",
"time_stamp"
],
"table": "user_pay",
"datasource": "vpc_drds"
},
"plugin": "drds"
}
},
"type": "job",
"version": "1.0"
}然后保存提交。
修改调度资源
任务提交后,需要到任务运维里修改任务运行使用的调度资源,这样任务才是运行在自己的ECS上的,可以看这个图
修改好了后,直接在这个页面可以点截图右下角的操作下拉选项里的补数据来跑任务。
总结
本文主要用自定义的ECS来调度来解网络不可达的问题。通过使用脚本模式来解因为网络不可达导致的向导模式无法配置的问题。脚本模式除了能解这个问题外,其实还能支持比向导模式更多的数据源。
最后需要提醒一句,大数据开发套件的产品形态还没有完全固定,产品本身还在做迭代,在界面和功能上后续可能还是会有一些不同,但是数据同步大致的思路就是这样不会变。希望本文能给大家在做ETL上有一些帮助和启发。
本文使用的产品涉及大数据计算服务(MaxCompute),地址为https://www.aliyun.com/product/odps
配合大数据开发套件 https://data.aliyun.com/product/ide 完成的。
如果有问题,可以加入我们的钉钉群来咨询