Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎,可以完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。本文主要目的是为大家提供一种非常简单的方法,在阿里云上部署Spark集群。
通过<阿里云ROS资源编排服务>,将VPC、NAT Gateway、ECS创建,Hadoop和Spark部署过程自动化,使大家能够非常方便地部署一个Spark集群。本文创建的Spark集群包含三个节点:master.hadoop,slave1.hadoop,slave2.hadoop。
急速部署Spark集群

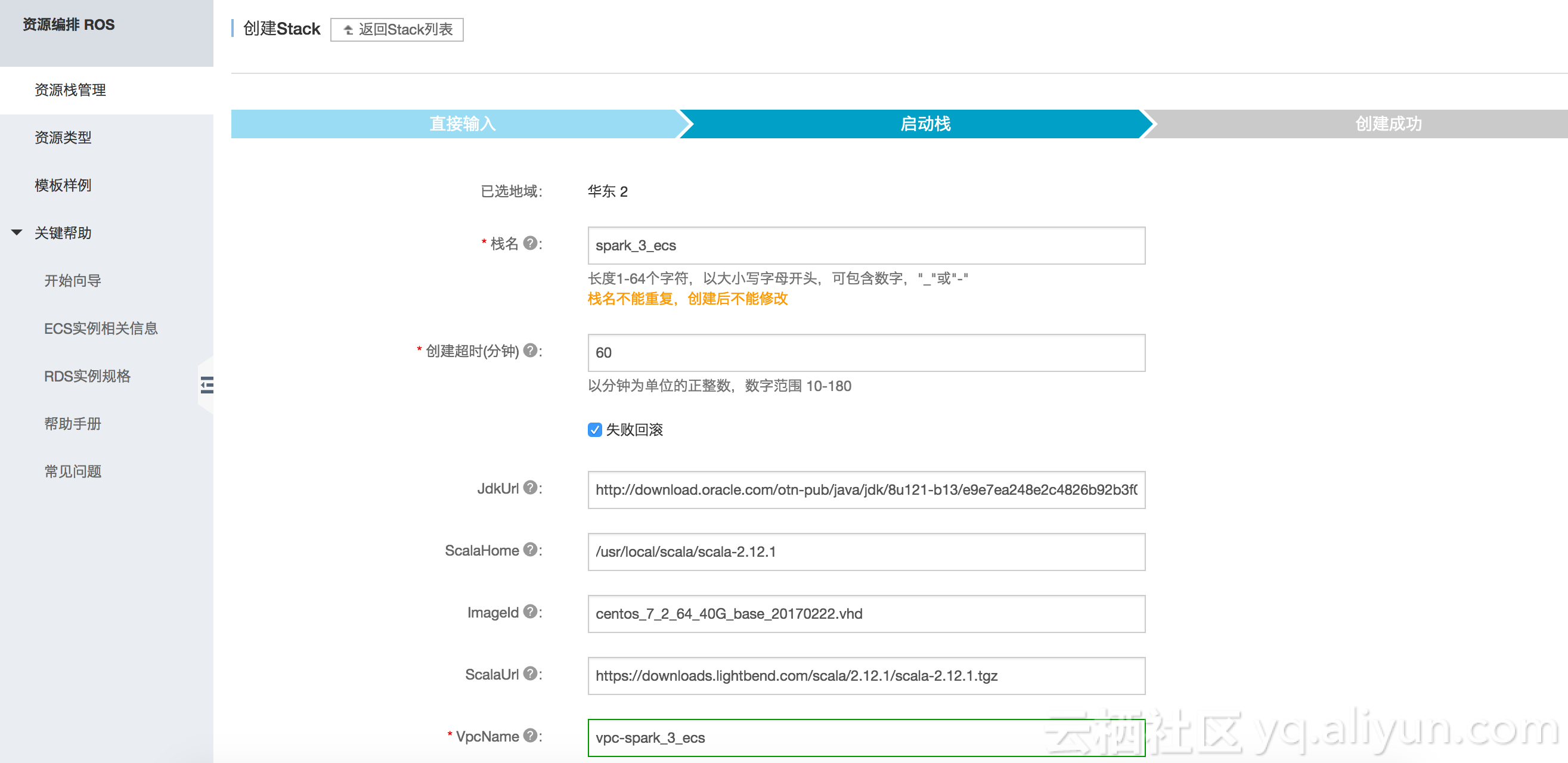
注意:
- 必须确保可以正确下载Jdk,Hadoop,Scala和Spark安装包,我们可以选择类似如下的URL:
- http://download.oracle.com/otn-pub/java/jdk/8u121-b13/e9e7ea248e2c4826b92b3f075a80e441/jdk-8u121-linux-x64.tar.gz (Must set 'Cookie: oraclelicense=accept-securebackup-cookie' in Header, when download.)
- http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.7.1/hadoop-2.7.1.tar.gz
- https://downloads.lightbend.com/scala/2.12.1/scala-2.12.1.tgz
- http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.7.tgz
- 利用该模板创建时,只能选择CentOS系统;
- 为了防止Timeout 失败,可以设置为120分钟;
- 我们选择的数据中心在上海/北京。
ROS模板安装Spark四部曲
Spark的依赖环境比较多,一般安装Spark可分为四步:安装配置Hadoop集群,安装配置Scala,安装配置Spark包和启动测试集群。
1. 安装配置Hadoop
安装Hadoop比较复杂,我们在上一篇博客《阿里云一键部署 Hadoop 分布式集群》中已经做过详细介绍,这里不再赘述。
2. 安装配置Scala
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架,Scala可以像操作本地集合对象一样轻松地操作分布式数据集。
"aria2c $ScalaUrl \n",
"mkdir -p $SCALA_HOME \ntar zxvf scala-*.tgz -C $SCALA_HOME \ncd $SCALA_HOME \nmv scala-*.*/* ./ \nrmdir scala-*.* \n",
"echo >> /etc/profile \n",
"echo export SCALA_HOME=$SCALA_HOME >> /etc/profile \n",
"echo export PATH=$PATH:$SCALA_HOME/bin >> /etc/profile \n",
"ssh root@$ipaddr_slave1 \"mkdir -p $SCALA_HOME; mkdir -p $SPARK_HOME; exit\" \n",
"ssh root@$ipaddr_slave2 \"mkdir -p $SCALA_HOME; mkdir -p $SPARK_HOME; exit\" \n",
"scp -r $SCALA_HOME/* root@$ipaddr_slave1:$SCALA_HOME \n",
"scp -r $SCALA_HOME/* root@$ipaddr_slave2:$SCALA_HOME \n",
3. 安装配置Spark
Master上安装Spark,并将配置正确后的Spark Home目录远程复制到Slave主机上,并设置环境变量。
"aria2c $SparkUrl \n",
"mkdir -p $SPARK_HOME \ntar zxvf spark-*hadoop*.tgz -C $SPARK_HOME \ncd $SPARK_HOME \nmv spark-*hadoop*/* ./ \nrmdir spark-*hadoop* \n",
"echo >> /etc/profile \n",
"echo export SPARK_HOME=$SPARK_HOME >> /etc/profile \n",
"echo export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin >> /etc/profile \n",
"source /etc/profile \n",
" \n",
"cp $SPARK_HOME/conf/slaves.template $SPARK_HOME/conf/slaves \n",
"echo $ipaddr_slave1 > $SPARK_HOME/conf/slaves \n",
"echo $ipaddr_slave2 >> $SPARK_HOME/conf/slaves \n",
"cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh \n",
"echo export SCALA_HOME=$SCALA_HOME > $SPARK_HOME/conf/spark-env.sh \n",
"echo export JAVA_HOME=$JAVA_HOME >> $SPARK_HOME/conf/spark-env.sh \n",
"scp -r $SPARK_HOME/* root@$ipaddr_slave1:$SPARK_HOME \n",
"scp -r $SPARK_HOME/* root@$ipaddr_slave2:$SPARK_HOME \n",
" \n",
"ssh root@$ipaddr_slave1 \"echo >> /etc/profile;echo export SCALA_HOME=$SCALA_HOME >> /etc/profile;echo export PATH=$PATH:$SCALA_HOME/bin >> /etc/profile;echo export SPARK_HOME=$SPARK_HOME >> /etc/profile;echo export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin >> /etc/profile;exit\" \n",
"ssh root@$ipaddr_slave2 \"echo >> /etc/profile;echo export SCALA_HOME=$SCALA_HOME >> /etc/profile;echo export PATH=$PATH:$SCALA_HOME/bin >> /etc/profile;echo export SPARK_HOME=$SPARK_HOME >> /etc/profile;echo export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin >> /etc/profile;exit\" \n",
4. 启动测试集群
最后格式化HDFS,关闭防火墙,启动集群。
"hadoop namenode -format \n",
"systemctl stop firewalld \n",
"$HADOOP_HOME/sbin/start-dfs.sh \n",
"$HADOOP_HOME/sbin/start-yarn.sh \n",
"$SPARK_HOME/sbin/start-all.sh \n",
测试部署结果
创建完成后,查看资源栈概况: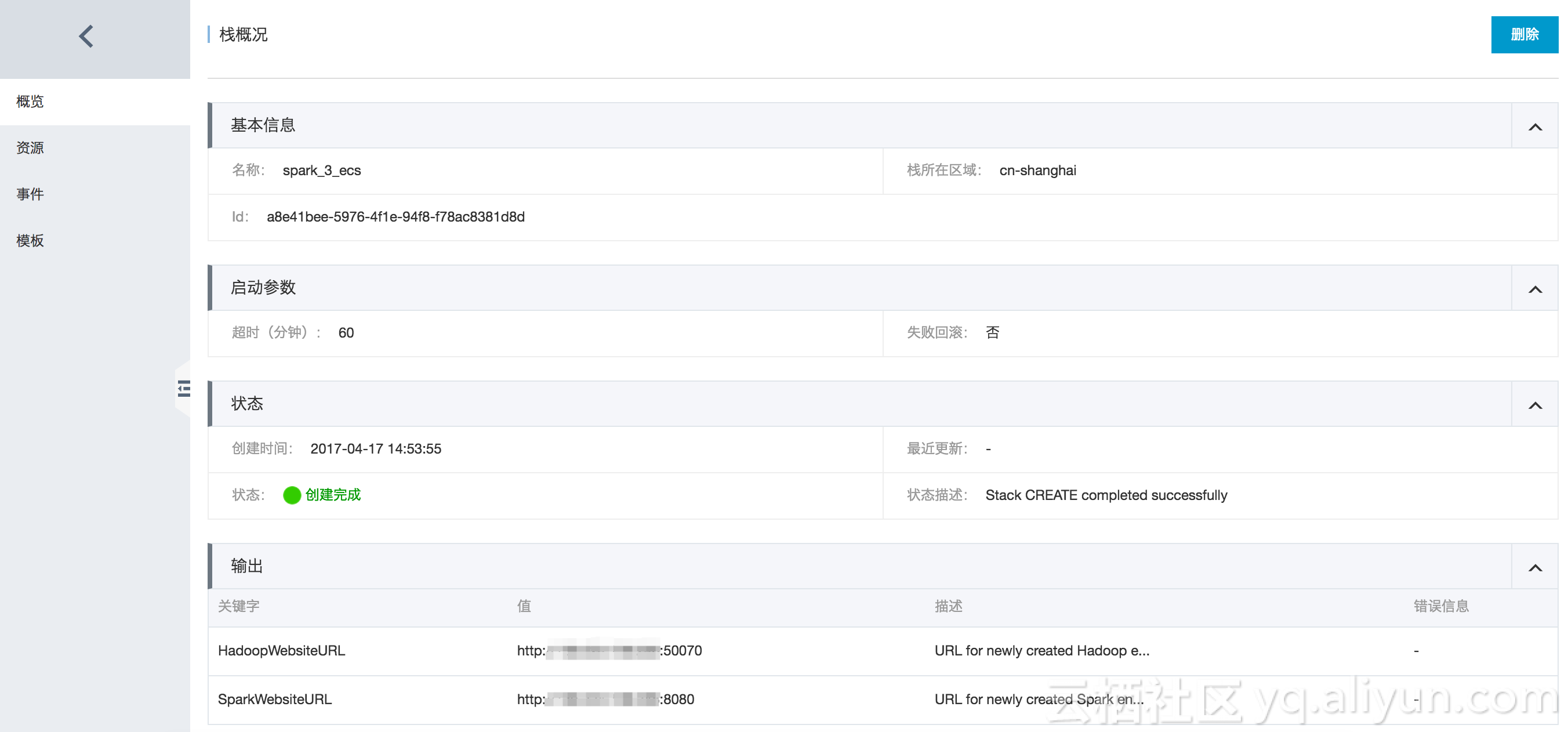
浏览器中输入图中的的SparkWebsiteURL,得到如下结果,则部署成功: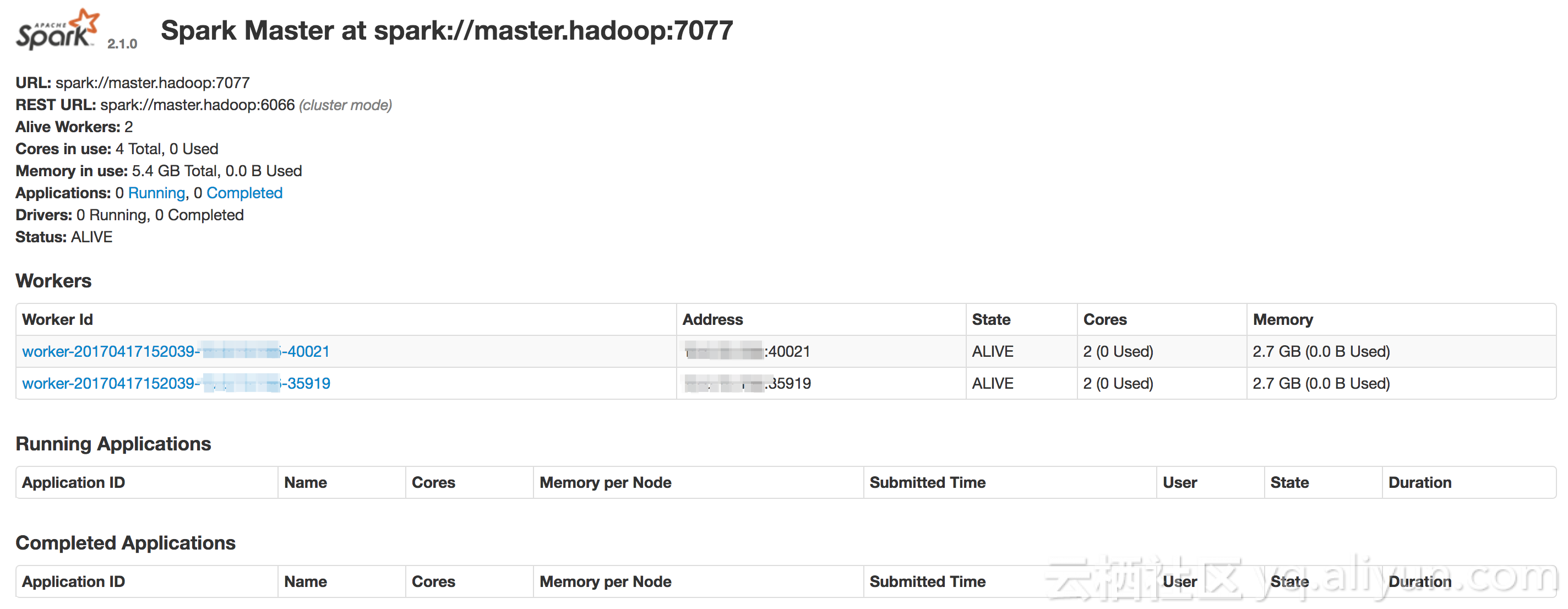
ROS示例模板
Spark_Hadoop_Distributed_Env_3_ecs.json:通过该模板可以一键部署上面的集群。
Spark_Hadoop_ecsgroup.json:该模板允许用户指定slaves节点的数量。