“在原来自建的环境里进行一个维度的数据处理大约需要 2-3天时间,而使用数加平台处理相同数据只需要 3-6 个小时。这些效率的提升可以缩短数据分析应用产品的研发周期,并能更好的提高这些产品的需求符合度。”-CTO 许鹏
关于江苏佰腾
江苏佰腾科技有限公司(以下简称“佰腾”)成立于2012年,是一家专业从事知识产权服务的高科技服务企业,国内知名的知识产权服务机构,江苏省最大的民营知识产权综合服务机构。佰腾科技以专利信息应用和专利咨询服务为核心,面向国内外用户提供专利信息检索、专利大数据应用开发、专利代理服务、专利预警分析、专利战略研究、知识产权贯标辅导、知识产权管理、专利技术成果转化交易等服务,为客户提供知识产权、科技创新的整体解决方案。佰腾科技的专利信息检索平台(专利探索者)已经持续研发了 10 年,是目前国内最知名的免费面向公众服务的大数据应用平台,为中国专利事业的发展做出了很多的突出贡献。2014年起,佰腾实施“互联网+专利”计划,开发了国内首家专利电商平台—专利巴巴,使公司转型为知识产权领域内的互联网公司,并采用B2B、O2O线上线下相结合的模式为客户提供全方位的、全流程的知识产权一体化服务。用互联网的思维和技术来改造传统的知识产权行业,在这个过程中,大数据技术的应用是佰腾科技最重要的手段之一。佰腾在专利信息应用上研究多年,一直致力于解决一个问题:让专利信息应用变得大众化。公司累计服务企业达120000多家,其中上市公司560多家。
挑战
佰腾科技致力于为客户提供最好的专利信息和技术创新服务。近年来,一些企业,特别是出口型企业开始慢慢认识到,不仅要在技术上做突围,同时也要构筑自己的专利壁垒,因此就一定需要创新。对企业来讲,创新投入的费用非常大,因此要找捷径,了解当前所在行业领域的技术发展程度,迫切需要找到技术的热点和空白点,于是这也就成为了佰腾专利信息应用的新的课题,这就要求佰腾不能单纯把专利信息的内容简单地拆解出来,而是需要通过大数据挖掘、大数据应用进行分析。在大数据处理流程中,不仅仅使用专利数据进行数据挖掘,还会更多地引用期刊文献、法律诉讼信息、企业信息,并将其整合。佰腾之前自建的数据平台已经不能满足大数据挖掘和应用的需求,在以下方面存在巨大的挑战:
1.投入成本过高。“整个平台,自建投入费用过百万,每年的维护也需要差不多十几万,投入非常大。”CTO许鹏讲道。
2.海量数据处理的能力差,不满足周期性的数据更新要求。“专利信息的大数据与其它领域的大数据不同,虽然全球专利信息的总量仅在 1.3 亿多条,但是每条专利信息要分析获取的数据维度目前就多达200多项,实际处理的数据量在100亿多条级别,同时,针对各种客户的不同需求,还要基于这些数据实现数百种的分析模型和方法,从中挖掘出专利信息的深层次价值。当前,专利大数据的业务已经非常复杂,数据业务场景从10年前的个位数增长到十位数,可用数据维度从30多项增加到200多项。”许鹏讲道。佰腾不仅仅提供给用户文本检索功能,还有图像检索、特征检索、关联检索,并将它们串起来,产生相应的报告;数据应用的深度也已经加大,数据维度的增加使数据处理量翻了数十倍,数据处理的能力已不再满足周期性的数据更新。一开始能做到每个维度都更新,后来随着数据维度的增加,处理不过来,有一些数据维度则会把更新的周期拉长。而且,在海量数据处理时,自建系统很多情况下在数据处理到80%的时候才会发现有问题,由于处理时间过长,当发现问题时只能重新开始,浪费的时间非常多,数据的处理周期会成倍拉长。
3. 数据处理和数据应用瓶颈频发。瓶颈主要存在以下3个方面:
• 分布式抓取模型,维护成本大,资源利用率不高;
• 单点数据存储结构,无法满足大量的读写并发,降低了数据检查和数据处理的速度;
• 索引数据和文本数据混合存储,数据应用性能较差。
• 需要分析的数据维度比较多,因此处理环节非常多,数据处理流程异常复杂,流程编排完全靠手工,任务繁重,无法自动化编排。
4.专利大数据的深度挖掘越来越需要依赖新的数据挖掘技术,比如文本聚类、机器学习、图像识别等,而佰腾不可能短时间内建立并拥有研发这些技术的专业团队,迫切需要借助第三方的平台及工具支撑。
5.专利大数据的应用是一个实践性非常强的领域,随着客户应用需求的不断提升,佰腾需要不断更新分析和展示数据结果的模型和方法,不仅有提升数据处理效率的问题,也有提升数据分析应用能力的问题。因此还需要数据平台具有可扩展性,可以快速响应不断变化的客户需求,而之前的平台有几十个组件均需要维护,而每有一个新的客户需求都需要重新做组件。
为什么选择阿里云数加
佰腾之前采用自建的数据平台进行大数据的处理和分析,如上所述,自建大数据基础设施需要采购和维护大量硬件设备,部署和配置复杂的系统环境,需要耗费大量资源保证服务的持续、稳定运行,并且对于运维人员的要求会更高。而且,原有的数据框架平台已使用多年,技术比较落后,在性能和功能上存在很多瓶颈,已经不能很好的支撑新的大数据研发需求。云服务最大的特点就是只用使用服务,不需要关心底层技术架构、安全性、可靠性、稳定性等方面的问题。而且,对于专利大数据处理业务来讲,云服务是整个业务系统依赖的重要基础,能节省大量的基础建设费用。而且,阿里云数加平台在国内大数据技术方面处于领先地位,也是最早进行大数据云化的平台,因此佰腾决定使用阿里云数加作为大数据平台。同时,也会根据自身业务的需求,对云服务进行进一步的开发,形成最有利于自身业务发展的大数据分析应用平台。
解决方案及架构
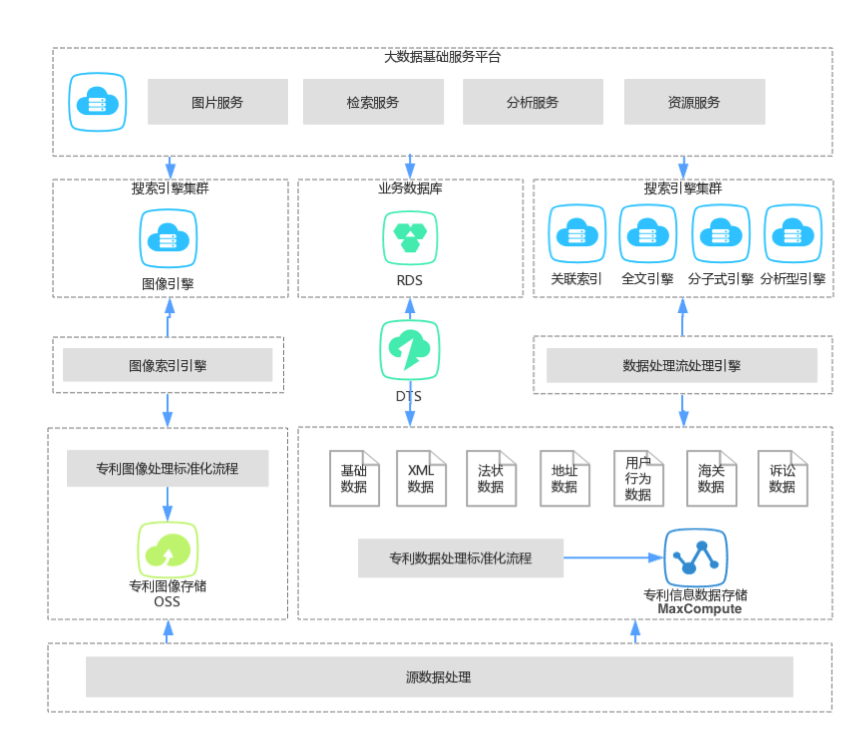
随着对专利信息维度挖掘的深入,佰腾对于信息挖掘的需求正在从“文字表述“向“逻辑概念”转移,比如希望从专利信息中挖掘出技术概念并发现它们之间的关系,这样就能帮助客户更好的分析技术发展的趋势和热点。目前,佰腾正在推进专利信息深度挖掘技术的研发,借助数加平台的机器学习以及数据分析能力,为客户提供更加精准、更加全面、更个性化的专利大数据应用服务。基于阿里云的大数据平台技术架构如页面下方架构图所示。整个平台按照数据业务处理过程中的职能对平台架构进行分层设计:
数据获取层:负责从数据源拉取数据,检验数据的完整性。如图中源数据处理组件所示,现在有1亿3千多万条专利数据,每周的更新量很大,要保证每周的数据都要拉取正确。
数据处理层:负责对原始数据进行数据维度的挖掘。现在200个数据维度,都通过这一层处理,将处理结果放到整体系统的核心—数据维度数据库,主要通过数加平台的MaxCompute作为数据维度数据库并通过Data IDE进行复杂的分布式大数据处理。此外,图像信息存储在OSS中,通过专利图像处理标准化流程,用于后续的数据应用层的图像索引引擎。
数据应用层:负责对数据维度进行各类索引以便应用。如图所示包括全文引擎、图像引擎等,还有关联索引,用于检索专利间的关系。最左边的图像引擎,和文本处理有些不同,但处理方式差不多。
数据服务层:负责对外提供统一的数据服务接口,保障服务质量。如图所示大数据基础服务平台所涵盖的图片服务、检索服务、分析服务和资源服务。
数据管控层:在架构图中未体现,贯穿上下各层,负责对整个数据平台进行运行监控。
此外,架构图中间还有RDS,将用于展示的数据单独拿出来,和索引分开,可以提高大数据应用的效率。
使用的阿里云数加产品有:
• 大规模计算服务(MaxCompute)
• 大数据开发套件(Data IDE)
• 机器学习
收益
1.成本大大降低。使用数加平台后,如上所述,无需基础设施投入,按需付费,而且无需关注运维问题。据统计,目前佰腾整个数加平台的年消费不到原来自建系统年维护费用的1/5。2. 数加平台的 MaxCompute 解决了数据存储量大的问题,保证了数据的安全性和完整性,数据存储和处理效率有了大幅提升。“在原来自建的环境里进行一个维度的数据处理大约需要 2-3天时间,而使用数加平台处理相同数据只需要 3-6 个小时。这些效率的提升可以缩短数据分析应用产品的研发周期,并能更好的提高这些产品的需求符合度。”许鹏讲道。
3. Data IDE的图形化任务开发功能很好的解决了数据处理过程中流程标准化的问题,可以将任务托管后自动化执行,解放了开发人员双手;分布式的框架结构解决了多任务的并发处理问题,提高了任务处理的速度,实现了数据价值的快速挖掘,避免了自建系统存在的诸多不稳定问题。
4. 上云之后的大数据处理流程,比之前的流程简单很多。所有流程都实现了自动化编排,一键式处理就可以完全编排,非常高效。新流程相比原来的具备以下优势:更高效、更丰富的数据维度挖掘;减少人工介入,降低了成本;全流程、全自动化的数据处理;索引数据和文本数据分离处理,提高数据应用性能。
5.机器学习平台降低了算法的学习成本,也可利用既有的数据模型算法解决数据挖掘过程中的问题。
6. 目前佰腾已经将基础数据处理和部分数据挖掘的任务放在阿里云数加平台上完成,然而更重要的是,阿里云数加一站式大数据平台还可以在文本数据挖掘、图像数据识别、数据关联分析等方面给予佰腾更多的能力支撑,以助力佰腾在专利大数据分析应用领域继续拓展业务并快速发展。
架构图
相关文章
https://yq.aliyun.com/articles/72250
https://
yq.aliyun.com/articles/70510
https://yq.aliyun.com/articles/70509
https://
yq.aliyun.com/articles/69333
https://yq.aliyun.com/articles/68211
https://yq.aliyun.com/articles/67275
https://yq.aliyun.com/articles/70359
https://yq.aliyun.com/articles/70353
https://yq.aliyun.com/articles/70412
https://yq.aliyun.com/articles/70347