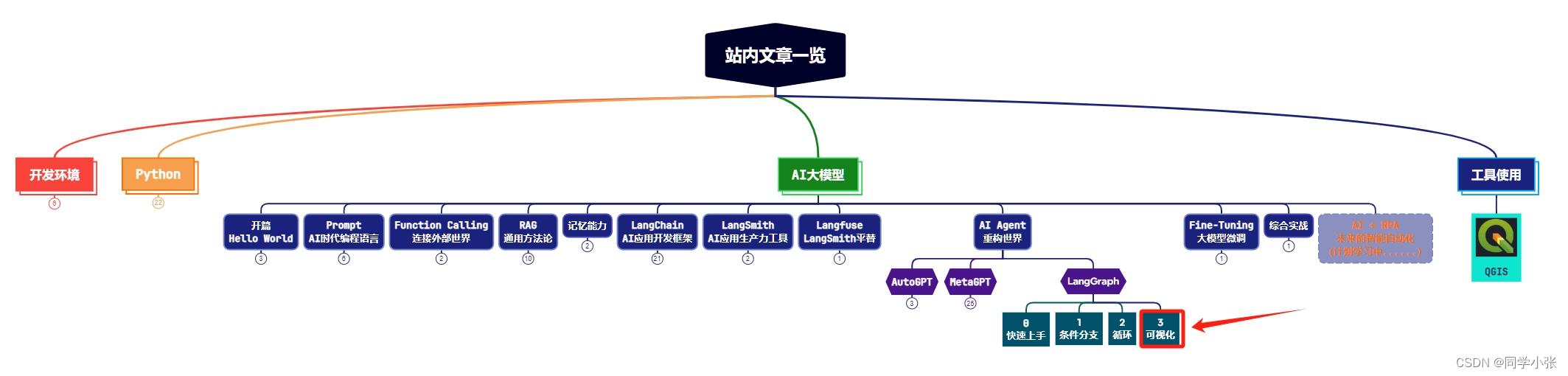
热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
工作中常用的一些Linux指令,简单易记还实用(二)
【linux进程控制(二)】进程等待--父进程是如何等待子进程死亡的?
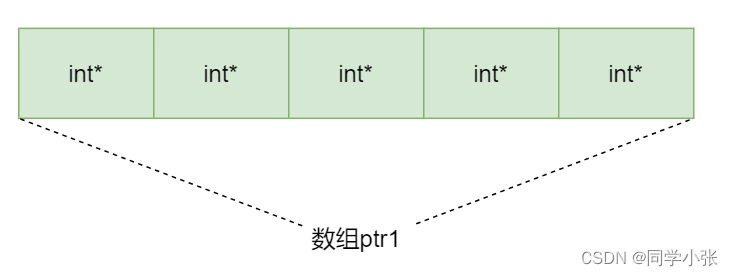
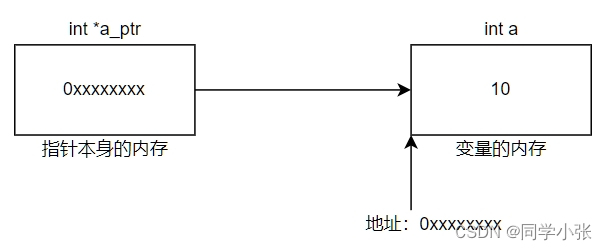
【重学C++】【指针】详解让人迷茫的指针数组和数组指针
工作中常用的一些Linux指令,简单易记还实用
【linux进程控制(一)】进程终止--如何干掉一个进程?
【linux进程(七)】程序地址空间深度剖析
【AI Agent系列】【阿里AgentScope框架】3. 深入源码:Pipeline模块如何组织多智能体间的数据流?- 顺序结构与条件分支
【linux进程(六)】环境变量再理解&程序地址空间初认识
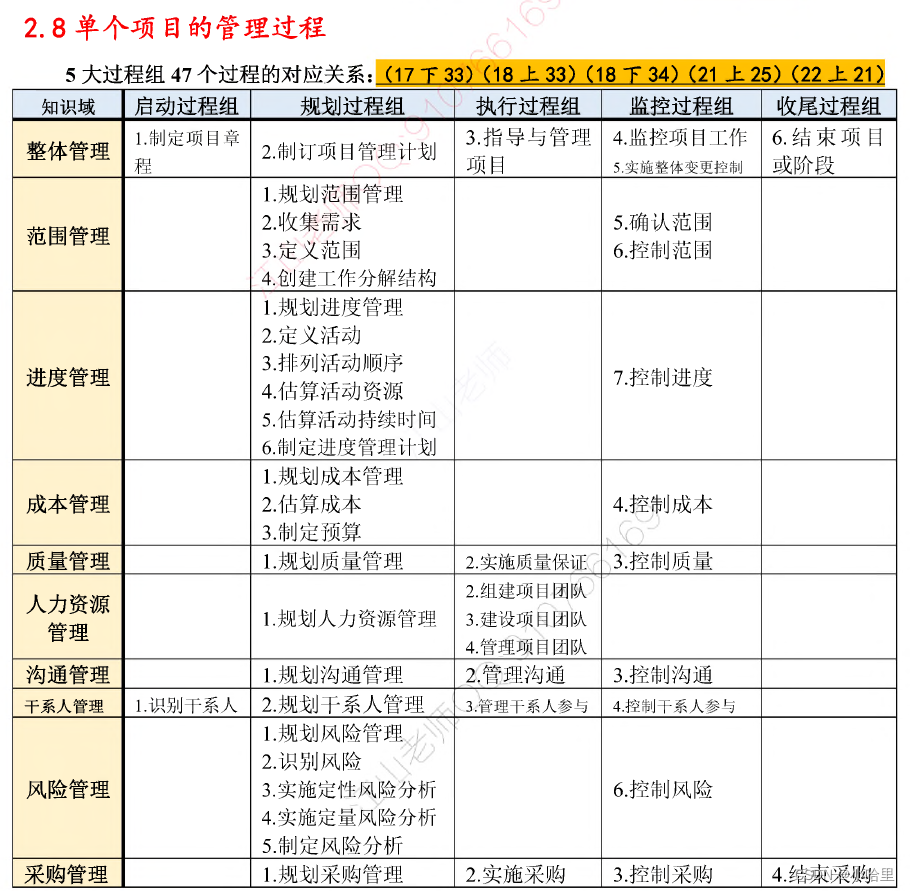
【高项】项目的概念,项目管理基础与立项管理
【C++进阶(九)】C++多态深度剖析
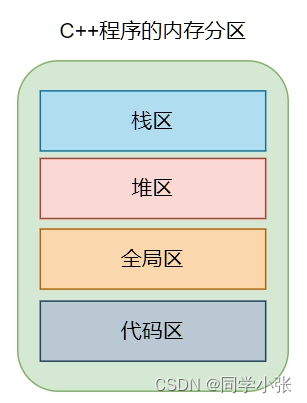
【重学C++】【内存】关于C++内存分区,你可能忽视的那些细节
下次老板问你MySQL如何优化时,你可以这样说,老板默默给你加工资
【C++进阶(八)】C++继承深度剖析
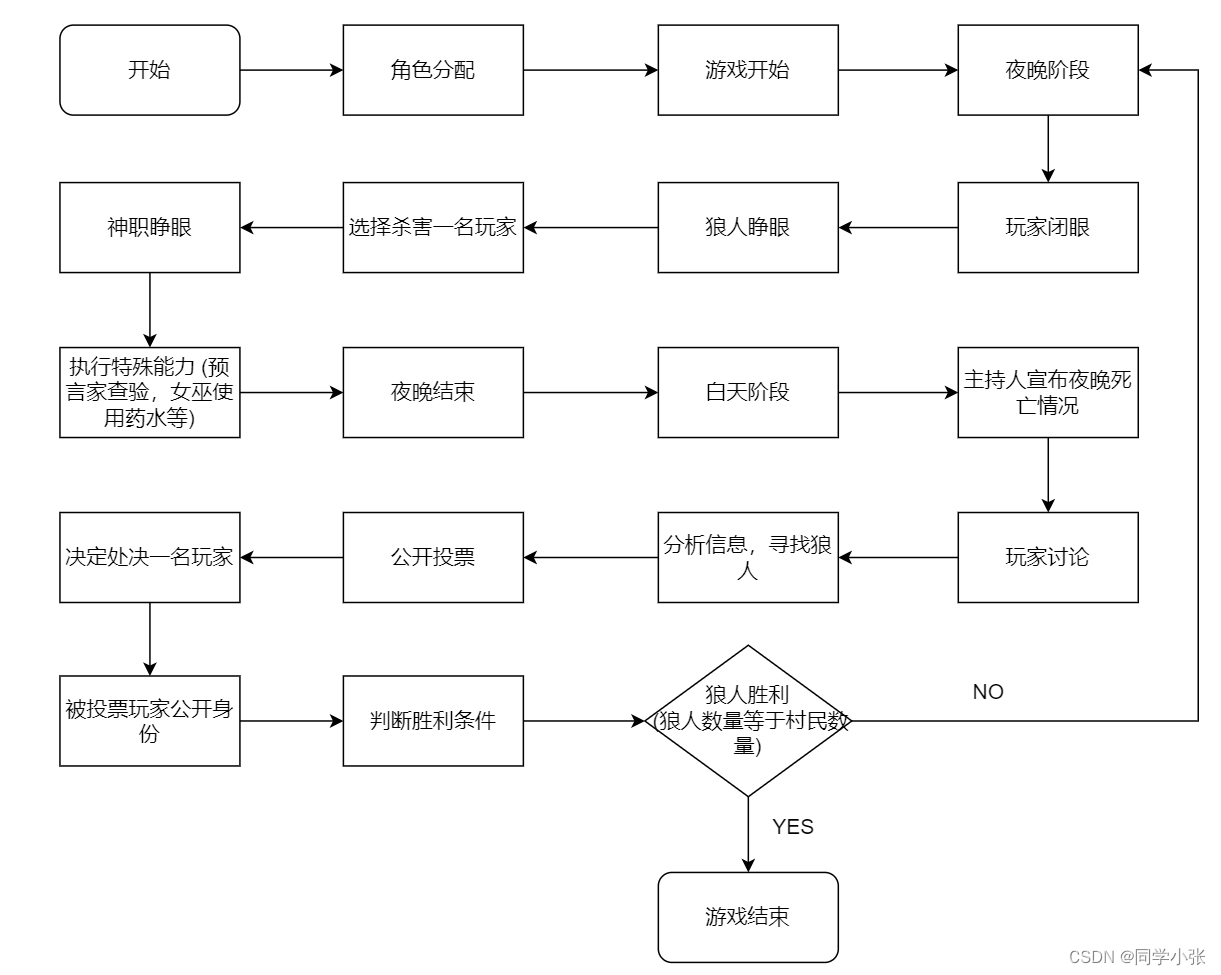
【AI Agent教程】【MetaGPT】案例拆解:使用MetaGPT实现“狼人杀“游戏(1)- 整体框架解析
【linux进程(五)】进程间切换以及环境变量问题
C++ 访问说明符详解:封装数据,控制访问,提升安全性
【linux进程(四)】僵尸进程和孤儿进程概念&进程优先级讲解
【重学C++】【指针】一文看透:指针中容易混淆的四个概念、算数运算以及使用场景中容易忽视的细节
【linux进程(三)】进程有哪些状态?--Linux下常见的三种进程状态
Keepalived集群软件高级使用(工作原理和状态通知)
【linux进程(二)】如何创建子进程?--fork函数深度剖析
【C++进阶(七)】仿函数深度剖析&模板进阶讲解
【C++进阶(六)】STL大法--栈和队列深度剖析&优先级队列&适配器原理
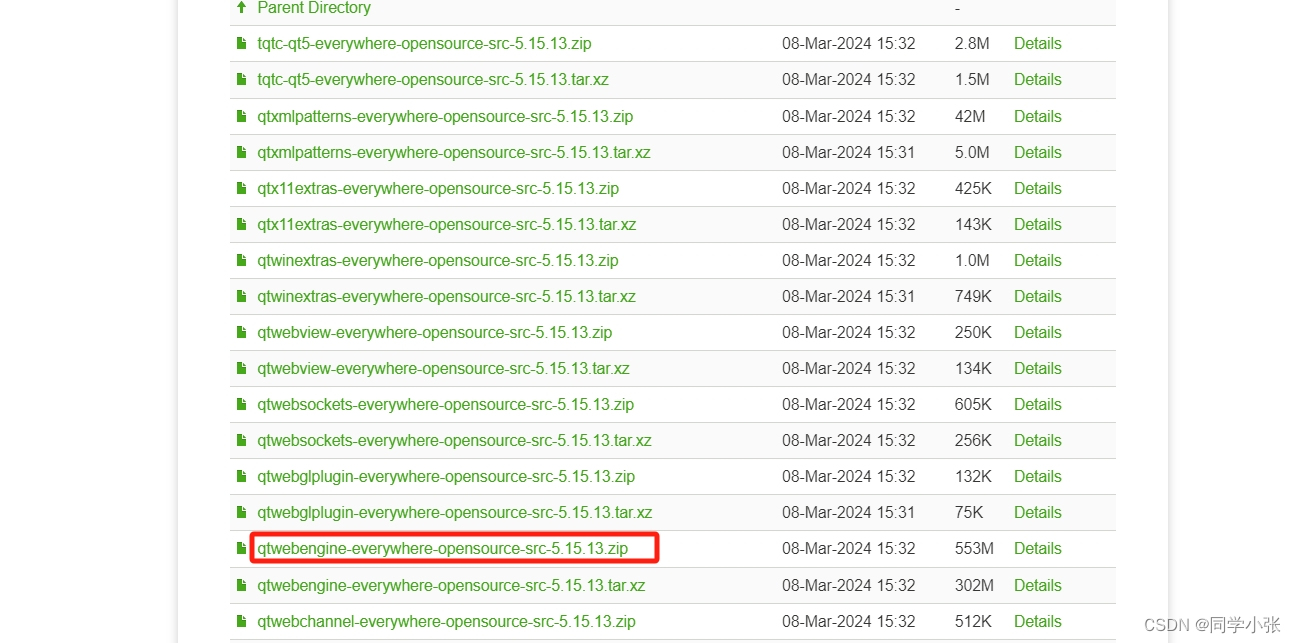
【Ubuntu工具】避坑指南:搞坏一台电脑,终于在Ubuntu系统上成功源码安装了 QT WebEngine 5.15.13
【linux进程(一)】深入理解进程概念--什么是进程?PCB的底层是什么?
【AI Agent系列】【阿里AgentScope框架】1. 深入源码:详细解读AgentScope中的智能体定义以及模型配置的流程
【linux基础(八)】计算机体系结构--冯诺依曼系统&操作系统的再理解
【Ubuntu工具】安装教程:Ubuntu系统上源码编译安装QT5.15.13(有坑)
【linux基础(七)】Linux中的开发工具(下)--make/makefile和git
最新消息, 阿里云通义千问 AI 大模型正式向全社会开放!
Ubuntu14.04快速搭建SVN服务器及日常使用
【linux基础(六)】Linux中的开发工具(中)--gcc/g++
【Ubuntu工具】详细图文教程:Ubuntu系统上安装QT6.2
【linux基础(五)】Linux中的开发工具(上)---yum和vim
【AI Agent系列】【LangGraph】3. 一行代码让你的 LangGraph 结构可视化!
【C++进阶(五)】STL大法--list模拟实现以及list和vector的对比
【vue】如何压缩图片之后传给后端
【C++进阶(四)】STL大法--list深度剖析&list迭代器问题探讨
远程访问本地jupyter notebook服务 - 无公网IP端口映射
linux工具之curl与wget高级使用
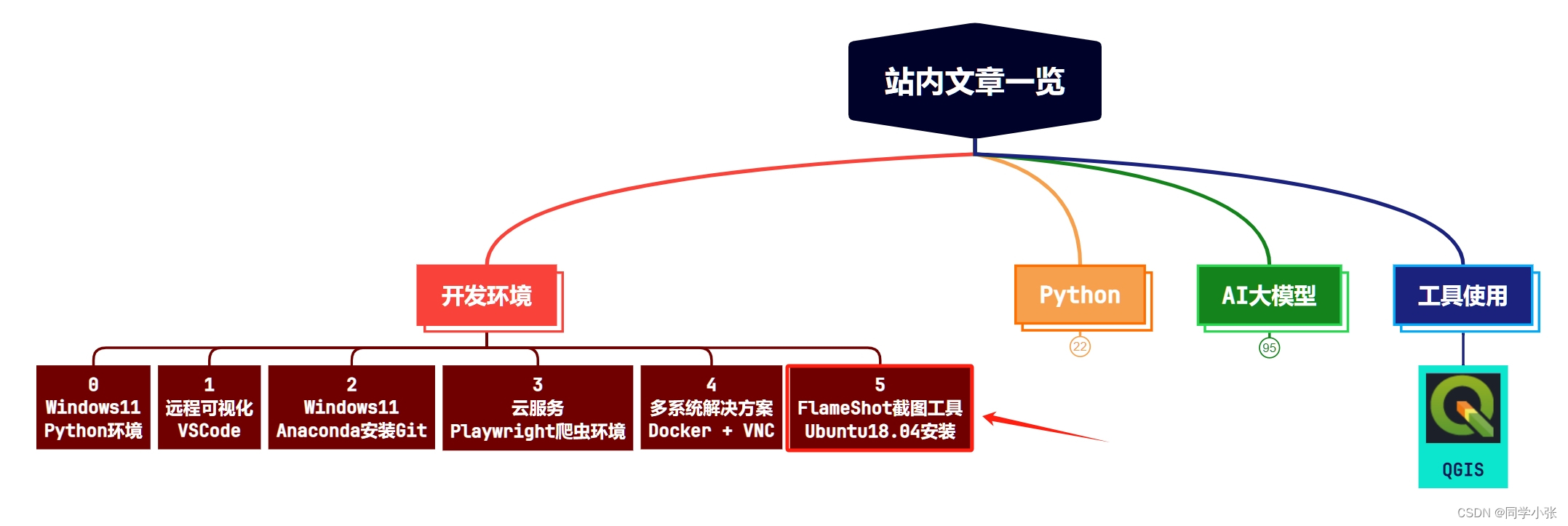
【Ubuntu工具】踩坑记录:Ubuntu18.04安装FlameShot截图工具及使用方法
【C++进阶(三)】STL大法--vector迭代器失效&深浅拷贝问题剖析
【vue】如何实现图片预加载
【C++进阶(二)】STL大法--vector的深度剖析以及模拟实现
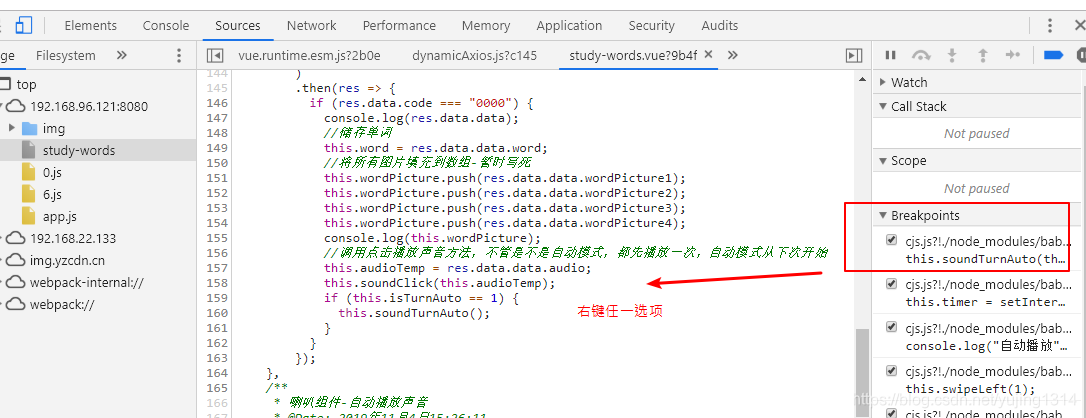
谷歌浏览器如何一键清除所有断点