之前在研究ElasticSearch的时候,发现竟然已经有 七篇文章了。这些文章通常都是遇到了问题,于是去研读相关代码,试图搞清楚里面的机制,顺带记录下来而成文的。如果加上一些黏边的文章,譬如 ELK的崛起等,则应当在十篇左右。 涉及到了聚合,索引构建,Rest/RCP API,Recovery 等多个方面。相对而言,ES 索引构建流程相关的文章已经比较完备:
在ES中,索引构建和查询因为没有做分离,所以他们之间存在着非常激烈的竞争关系,而ES所暴露出来的那无数参数就是调整两者之间关系的。
Merge的影响其实是非常大的。现在大部分存储系统对于更新和删除其实都是生成新的文件,并不会直接去更新原来的文件,查询时对应的Reader会读取这些文件,从而实现类似合并后的效果。在ES中,Merge由两部分构成,MergeScheduler和MergePolicy。MergeScheduler控制合并的使用的工作线程以及一次合并多少文件等。MergePolicy则是控制如何进行文件的合并。默认的TireMergePolicy,会生成多个不大于5G的文件。
所以,对于Merge其实我们可以调整MergeScheduler和MergePolicy。对应的你可以在ElasticsearchConcurrentMergeScheduler和MergePolicyConfig两个类里看到详细的可配置参数列表。
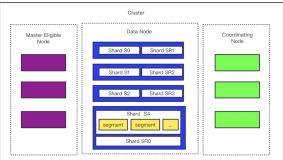
Merge有啥影响的?其实它和Shard数的控制也有很大关系。假设我们有100台服务器,2400颗核,单机24颗核心,那么默认每个分片会有四个线程用于Merge操作。假设我们有500个分片,那么Merge可以使用的CPU核数达到了2000个,在一个数据写入非常频繁的系统,大部分CPU可能都会被Merge给消耗掉。所以并不是分片越多越好,这里需要考虑Merge对系统的影响,并且分片越多,那么用于Bulk的CPU就越多,对Search的性能其实也是有影响的。
在我的实际测试过程中,如果我将分片数设置为服务器数,并且将merge线程设置为1,也就是一个Shard一个merge线程,这种情况下,CPU会有效的降低,并且索引构建性能也能得到一定的提升。我猜测,如果调低 index.merge.policy.max_merged_segment,假设现在设置为1G,那么将一个2M的新的Segment合并到1G的文件将比原来5G的快得多,消耗的CPU也更少,然而带来的影响可能是索引查询性能的下降以及可能导致系统文件句柄的耗尽。
如果一个Shard分片里的数据过大,那么譬如聚合查询的响应时间基本就难以接受了,对于数据规模在五六亿的一个分片而言,简单的groupby 加sum的查询可能耗时都能够达到2分钟,相对而言,Shard的文档数量在百万规模,能够获得一个较好的查询响应时间,然而可能依然以秒计。
Shard一多,Merge以及Bulk构建索引消耗的CPU都会变得巨大,让Search变得愈加困难。而随着数据量规模的日益庞大,而单个Shard数据量又不宜太大,那么只能加大Shard数量,这就导致我们陷入了一个困境。
解决上面的问题似乎有两个简单而有效的方案:
- 让同一Node实例的Shard共用一个Merge线程池,而不是现在的每个Shard单独战友一个Merge线程池。
- 将Shard 字段的列式存储,最好是能够分成多个block,然后利用其有序性,对每个Block保留Min-Max值,从而在做equal或者range类的过滤时,跳过部分Block,避免时间消耗和Shard的数据量成线性关系。而且如果单个文件,则很难全部缓存起来,无法高效利用系统缓存。
- 有些查询理论上是不精准的,有误差的,然而大部分场景下却都是准确的。
- 有些理论上是不精准的,有误差的,实际场景也是有误差的。
那为啥ES不能做精准的计算呢?那是因为ES是一个存储,而不是一个正真意义上的分布式计算引擎。分布式计算引擎一定要有一个强大的Reduce能力,而ES目前还只能在单机做Reduce,这就导致它必定受限于单机的内存,所以他必须做一些假设或者采用某种估算算法才能避免内存被耗尽。
ES-Hadoop基本就是个半成品。为啥说是半成品呢?因为我们确实能够利用ES-Hadoop项目很好的和Spark做结合,将数据导入到ES中。然而进行查询的时候,因为ES-Hadoop采用了http协议,通过RestAPI 去获取ES的数据导入到Spark中做计算,导致加载效率极低。加载效率低的原因其实不仅仅是采用了HTTP协议的缘故(如果换做RPC据说效率有50%以上的提升),还有如:
- Scroll API 需要每次重新获得和过滤候选集,然后得到新批次的数据
- Scan后获得DocId集合,然后fetch _source 是一个随机读过程而让IO性能无法接受
其中影响最大的是fetch _source。 这也是Spark Data source API 带来的问题,也不能全怪ES。为什么这么说呢? 因为Spark Data Source API 依然无法发挥底层存储的计算能力,它只能下沉(PushDown)一些filter,而无法接受groupby后的结果进行计算,这就导致数据规模下不来。
能够跑后台任务对类似ES这种系统是很重要的。现在的ES无法实现把任务丢进去(或者查询),然后可以异步监控获取结果。一种比较直观的场景是,我丢一个SQL进去,类似 insert to newtable from (select * from oldtalbe)这种,然后第二天就可以出结果,然后BI报表读取newtable就能够显示了。这个只是功能的话是比较容易做的,最大的难点是资源的控制,不能说一个query任务就耗尽了所有的资源甚至跑挂了ES。 实际上涉及到两个点:
- 资源隔离
- 任务调度
要实现资源隔离,只能自己去管理内存,可能需要JVM实现一个TaskMemoryManager的管理器,然后所有task都需要到这里来申请资源,其实是很复杂的一件事情。
我们知道 ES是有自己的DSL的,是一个用JSON来定义的查询语言。写起来还是比较繁琐的,而相当一部分功能其实是可以映射到SQL上的。我觉得官方有必要提供对SQL的支持,Solr现在已经做了,但是ES目前还只有第三方在做。在我的视角里,没有SQL支持的查询系统,我基本是不考虑的。Spark 提供了那么多易用的API,然而纯SQL还是最好用的。
在讨论这个问题之前,我们先要理解一下文件的写入过程。当我们打开一个文件描述符往里面写入数据的时候,一般而言会写入文件系统的缓存里,所以再最后需要fsync一下,强制将所有数据刷入磁盘。那么对应的,Segment产生也分两个阶段,一个是产生了文件,一个是fsync到磁盘后不再变化了。
我们这里指的产生Segment就是指已经被commit到磁盘的segment.
Segment这个名词来自于Lucene,在前面Merge相关的内容里已经反复有所提及。Translog是触发Segment生成一个比较重要的地方,因为他们本来就是起互补作用的。当我们要清空Translog然后打开新的Translog时,就会将现有的数据持久化到Segment里。所以Translog的配置直接影响了Segment的生成频率。另外,Translog做Recovery的时候,其实也是会触发flush动作的,比如做SNAPSHOT。当然,ES也可以通过API手动触发Flush从而产生Flush动作。
ES副本对索引性能的影响几乎是100%。 然而目前的机制而言,你是不能去掉副本的,因为一旦发生主片丢失,就不仅仅是已经存在的数据丢失,还包括新的数据部分也无法进入集群。至于为啥影响是100%呢?因为副本和主片都是通过HTTP协议完成的,而不是类似传统的文件拷贝的方式。在5.0之后有一个优化,就是fsync可以实现异步化,可以有效提高吞吐。
随着ES在数据分析领域的大放异彩,索引速度越来越是个瓶颈。企业似乎也愿意投资,使用百台高性能服务器录入千亿规模数据的大有人在。然而和原生的Lucene的速度相比较,差距仍然是比较大的。那么速度到底差在哪里呢?
大体有几个因子影响了索引的速度:
- Translog ,你可以类比MySQL的Binlog
- Version,版本检查
- 一些特殊字段,譬如_all,_fieldNames等
- Schema Mapping相关的(譬如mapping Dynamic Update)
- JSON的解析(ES 交互基本是以JSON为主体的)
- Segments 的Merging
- Refresh Interval ,索引的刷新周期
在默认参数下,Translog 写入的CPU消耗甚至比Lucene 的addDocument 还高两倍。这点我还是蛮诧异的。Translog也要落磁盘,也需要commit,所以我们可以通过将index.translog.durability设置为async,这样translog的写入由默认的每次请求后就执行改成定时(5s)commit一次。这样带来的额外好处是减少 Translog写磁盘的次数,也就了减少了构建索引的消耗。
Translog并不会无限存在,到了一定程度,就需要触发索引的flush,具体动作是
- commit index segment
- clear translog
- open new translog
- flush的越少,那么索引性能越高
- flush的越少,translog就可能越大,那么当发生故障时,恢复时间就可能越长。
这里解释下translog和故障恢复的关系。当数据进行recovery的时候,大致是如下一个流程:INIT -> INDEX -> VERIFY_INDEX -> TRANSLOG -> FINALIZE -> DONE
第二种情况是重新Load某个Shard,比如某个Node被快速重启了,这个时候因为数据还没来得及commit成segment就挂了,再次启动后,丢失的数据就可以从Trasnlog里恢复了,如果Translog多了,就让恢复变得很慢。所以在这种情况下,Translog保留多少条就变得很重要了,可以通过参数index.translog.flush_threshold_ops 控制。
当然,前面讨论的一些设置让translog也变得不可靠,一旦产生当机等问题,可能在内存中的translog没有及时commit到磁盘而导致数据丢失。吞吐和可靠总是存在某种矛盾。
关于Translog的内容,大致就如上了。我觉得Translog的写入和读取等还是有优化空间的。这里再说说5.0里和Translog有关的一个优化,在ES里实时Get的话,其实是通过内存中通过docId拿到translog offset ,然后再去拿的,5.0之后不需要这样了,只要在内存维护最新文档的docId而不是docId和translog offset的映射关系,然后有请求的话,将数据flush到segment里然后直接去取。
我们再说说Version机制,Version大致会有一个Map缓存,如果缓存没有,就会走磁盘。索引Version检查其实是一个昂贵的操作。如果是时序数据(不变数据),则让系统auto generate id可以跳过Version检查,这样的话对性能也是巨大的提升。
在ES里有一些特殊字段,比如_all,_fieldNames,_source等。_all性能影响还是比较大的。_source我们一般需要保留,否则会有很多不便,因为无法还原完整的记录。_all一般而言可以关掉。之前我没注意到_fieldNames这个字段,通过JProfiler我发现如下的代码竟然占了整个Bulk过程CPU的6%左右的消耗。
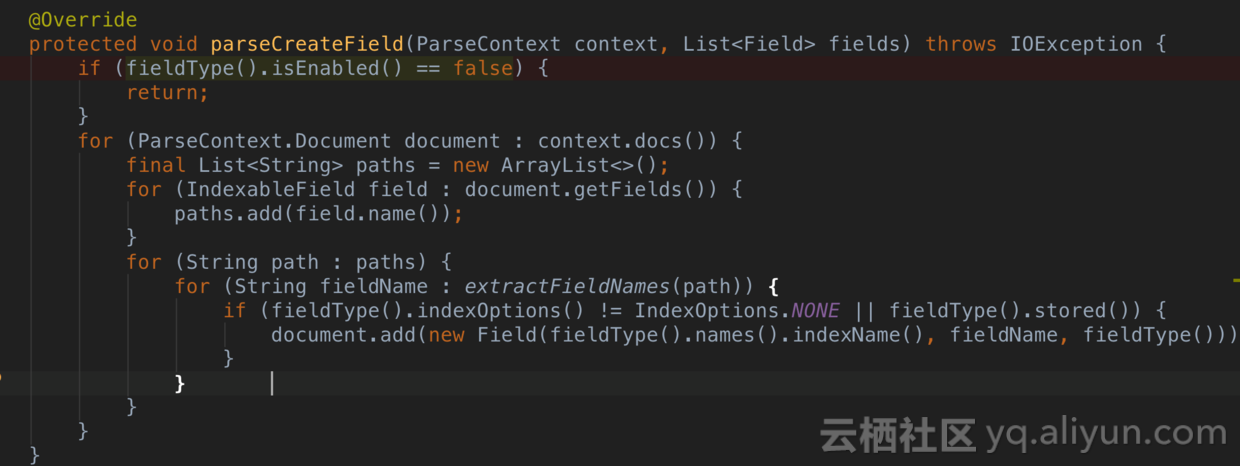
后来一查,发现是为了生成_fieldNames字段的。如果你要追求索引灌入的性能,果断关掉这个字段吧。
ES的Mapping其实消耗也非常大,比如Dynamic update 特性。建议固定好的你Schema,然后在ETL过程中规范你的数据,然后关掉该特性。
JSON的解析其实是比较慢的,通过性能分析发现,比如StringFieldMapper里的parseCreateFieldForString方法消耗CPU就特别厉害,仔细一看,