
1. 前言
自2012年Deep Learning的代表模型AlexNet在ImageNet大赛中力压亚军,以超过10个百分点的绝对优势夺得头筹之后,依托于建模技术的进步、硬件计算能力的提升、优化技术的进步以及海量数据的累积,Deep Learning在语音、图像以及文本等多个领域不断推进,相较于传统作法取得了显著的效果提升。
工业界和学术界也先后推出了用于Deep Learning建模用途的开源工具和框架,包括Caffe、Theano、Torch、MXNet、TensorFlow、Chainer、CNTK等等。其中MXNet、TensorFlow以及CNTK均对于训练过程提供了多机分布式支持,在相当大程度上解放了DL建模同学的生产力。
但是,DL领域的建模技术突飞猛进,模型复杂度也不断增加。从模型的深度来看,以图像识别领域为例,12年的经典模型AlexNet由5个卷积层,3个全连接层构成(图1),在当时看来已经算是比较深的复杂模型,而到了15年, 微软亚洲研究院则推出了由151个卷积层构成的极深网络ResNet(图2);从模型的尺寸来看,在机器翻译领域,即便是仅仅由单层双向encoder,单层decoder构成的NMT模型(图3),在阿里巴巴的一个内部训练场景下,模型尺寸也达到了3GB左右的规模。
从模型的计算量来看,上面提到的机器翻译模型在单块M40 NVIDIA GPU上,完成一次完整训练,也需要耗时近三周。Deep Learning通过设计复杂模型,依托于海量数据的表征能力,从而获取相较于经典shallow模型更优的模型表现的建模策略对于底层训练工具提出了更高的要求。现有的开源工具,往往会在性能上、显存支持上、生态系统的完善性上存在不同层面的不足,在使用效率上对于普通的算法建模用户并不够友好。阿里云推出的PAI(Platform of Artificial Intelligence)产品则致力于通过系统与算法协同优化的方式,来有效解决Deep Learning训练工具的使用效率问题,目前PAI集成了TensorFlow、Caffe、MXNet这三款流行的Deep Learning框架,并针对这几款框架做了定制化的性能优化支持,以求更好的解决用户建模的效率问题。
这些优化目前都已经应用在阿里巴巴内部的诸多业务场景里,包括黄图识别、OCR识别、机器翻译、智能问答等,这些业务场景下的某些建模场景会涉及到几十亿条规模的训练样本,数GB的模型尺寸,均可以在我们的优化策略下很好地得到支持和满足。经过内部大规模数据及模型场景的检测之后,我们也期望将这些能力输出,更好地赋能给阿里外部的AI从业人员。
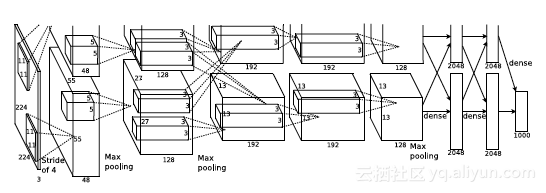
图1. AlexNet模型示例

图2. 36层的ResNet模型示例
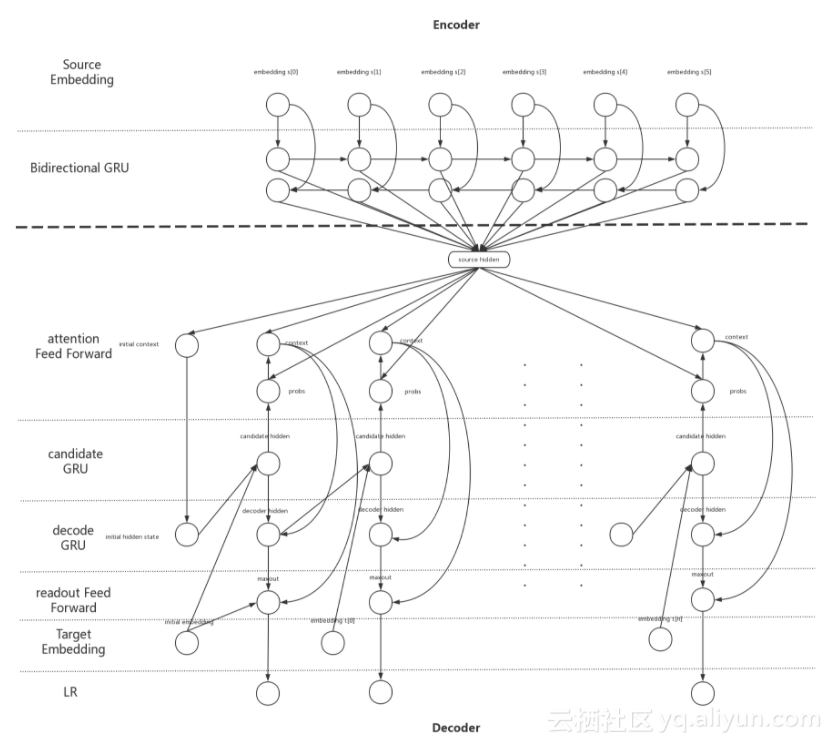
图3. NMT模型架构示例
接下来,本文会扼要介绍一下在PAI里实现的大规模深度学习的优化策略。
2. 大规模深度学习优化策略在PAI中实践应用
大规模深度学习作为一个交叉领域,涉及到分布式计算、操作系统、计算机体系结构、数值优化、机器学习建模、编译器技术等多个领域。按照优化的侧重点,可以将优化策略划分为如下几种:
I. 计算优化
II. 显存优化
III. 通信优化
IV. 性能预估模型
V 软硬件协同优化
PAI平台目前主要集中在显存优化、通信优化、性能预估模型、软硬件协同优化这四个优化方向。
1). 显存优化
内存优化主要关心的是GPU显存优化的议题,在Deep Learning训练场景,其计算任务的特点(大量的满足SIMD特性的矩阵浮点运算执行序列,控制逻辑通常比较简单)决定了通常我们会选择GPU来作为计算设备,而GPU作为典型的高通量异构计算设备,其硬件设计约束决定了其显存资源往往是比较稀缺的,目前在PAI平台上提供的中档M40显卡的显存只有12GB,而复杂度较高的模型则很容易达到M40显存的临界值,比如151层的ResNet、阿里巴巴内部用于中文OCR识别的一款序列模型以及机器翻译模型。从建模同学的角度来看,显存并不应该是他们关心的话题,PAI在显存优化上做了一系列工作,期望能够解放建模同学的负担,让建模同学在模型尺寸上获得更广阔的建模探索空间。在内存优化方面, 通过引入task-specific的显存分配器以及自动化模型分片框架支持,在很大程度上缓解了建模任务在显存消耗方面的约束。其中自动化模型分片框架会根据具体的模型网络特点,预估出其显存消耗量,然后对模型进行自动化切片,实现模型并行的支持,在完成自动化模型分片的同时,我们的框架还会考虑到模型分片带来的通信开销,通过启发式的方法在大模型的承载能力和计算效率之间获得较优的trade-off。
2). 通信优化
大规模深度学习,或者说大规模机器学习领域里一个永恒的话题就是如何通过多机分布式对训练任务进行加速。而机器学习训练任务的多遍迭代式通信的特点,使得经典的map-reduce式的并行数据处理方式并不适合这个场景。对于以单步小批量样本作为训练单位步的深度学习训练任务,这个问题就更突出了。
依据Amdahl’s law[19],一个计算任务性能改善的程度取决于可以被改进的部分在整个任务执行时间中所占比例的大小。而深度学习训练任务的多机分布式往往会引入额外的通信开销,使得系统内可被提速的比例缩小,相应地束缚了分布式所能带来的性能加速的收益 。
在PAI里,我们通过pipeline communication、late-multiply、hybrid-parallelism以及heuristic-based model average等多种优化策略对分布式训练过程中的通信开销进行了不同程度的优化,并在公开及in-house模型上取得了比较显著的收敛加速比提升。
在Pipeline communication(图4)里,通过将待通信数据(模型及梯度)切分成一个个小的数据块并在多个计算结点之间充分流动起来,可以突破单机网卡的通信带宽极限,将一定尺度内将通信开销控制在常量时间复杂度。

图4. Pipeline communication
在Late-multiply里,针对全连接层计算量小,模型尺寸大的特点,我们对于多机之间的梯度汇总逻辑进行了优化,将“多个worker计算本地梯度,在所有结点之间完成信息交互”(图5)的分布式逻辑调整为“多个worker将全连接层的上下两层layer的后向传播梯度及激活值在所有计算结点之间完成信息交互”(图6),当全连接层所包含的隐层神经元很多时,会带来比较显著的性能提升。

图5. Without late-multiply

图6. With late-multiply
在Hybrid-parallelism里,针对不同模型网络的特点,我们引入了数据并行与模型并行的混合策略,针对计算占比高的部分应用数据并行,针对模型通信量大的部分应用模型并行,在多机计算加速与减少通信开销之间获得了较好的平衡点。通过图7,可以看到将这个优化策略应用在TensorFlow里AlexNet模型的具体体现。
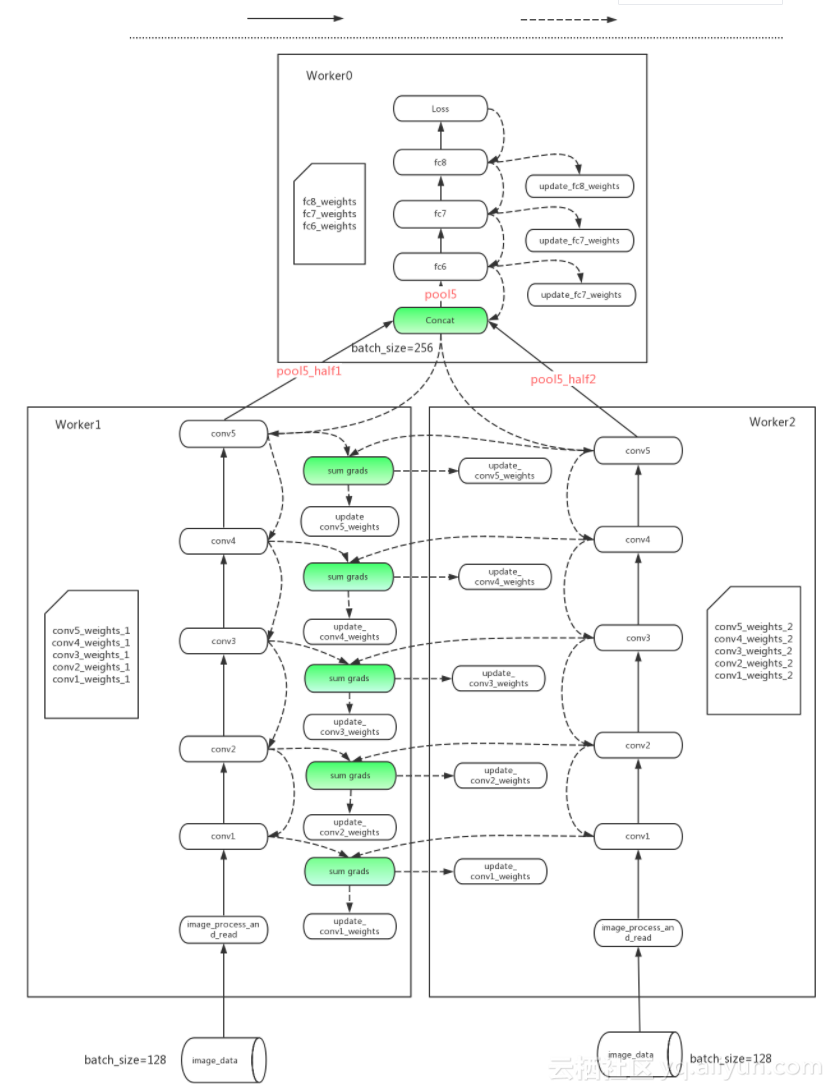
图7. AlexNet with hybrid-parallelism
3). 性能预估模型
对于建模人员来说,他们关心的往往是以最具性价比的方式完成他们的建模训练任务,而不是用多少张卡,以什么样的分布式执行策略来完成他们的训练任务。而目前Deep Learning训练工具以及训练任务的复杂性,使得建模人员往往不得不透过leaky abstraction的管道,去关心为了完成他们的一个建模实验,应该使用多少张GPU卡,多少个 CPU核、什么样的通信介质以及选择哪种分布式执行策略,才能有效地完成自己的训练任务。
基于性能预估模型,我们期望能够将建模人员从具体的训练任务执行细节中解放出来。具体来说,给定建模用户的一个模型结构,以及所期望花费的费用和时间,PAI平台会采用模型+启发式的策略预估出需要多少硬件资源,使用什么样的分布式执行策略可以尽可能逼近用户的期望。
4). 软硬件协同优化
上面提到的3个优化策略主要集中在任务的离线训练环节,而Deep Learning在具体业务场景的成功应用,除了离线训练以外,也离不开在线布署环节。作为典型的复杂模型,无论是功耗、计算性能还是模型动态更新的开销,Deep Learning模型为在线部署提出了更高的要求和挑战。在PAI平台里,关于在线部署,我们除了软件层面的优化之后,也探索了软硬件协同优化的技术路线。目前在PAI平台里,我们正在基于FPGA实现在线inference的软硬件协同优化。在PAI里实现软硬件协同优化的策略与业界其他同行的作法会有所不同,我们将这个问题抽象成一个domain-specific的定制硬件编译优化的问题,通过这种抽象,我们可以采取更为通用的方式来解决一大批问题,从而更为有效地满足模型多样性、场景多样性的需求。
3. 小结
大规模深度学习优化是一个方兴未艾的技术方向 ,无论是工业界还是学术界在对这个领域都有着极高的关注度,围绕这个主题也涌现出若干个成功的start-up,通过分享这篇文章,我们期望能够让PAI的终端用户了解到为了提升用户提升,改善用户建模效率,我们在背后所做出的优化努力。
今年5月份,NVIDIA GTC 2017北美主场会在硅谷举行,PAI团队也会在硅谷现场给出一个以大规模深度学习优化为主题的分享。今年7月份,在Strats+Hadoop World 2017大会上,PAI团队也会做一个相关主题的分享。也希望能够以这篇文章为引子,以这篇个技术会议为渠道,跟国内外更多从事相关领域工作的业界同行有更多交流和碰撞,一起来推进大规模深度学习这个技术方向的进展和建设。
参考文献
[1]. Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep
convolutional neural networks. In Advances in neural information processing systems , pages
1097–1105, 2012.
[2]. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image
recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ,
pages 770–778, 2016.
[3]. Geoffrey Hinton, Li Deng, Dong Yu, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly,
Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sainath, et al. Deep neural networks
for acoustic modeling in speech recognition: The shared views of four research groups.
IEEE Signal Processing Magazine , 29(6):82–97, 2012.
[4]. Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan
Catanzaro, and Evan Shelhamer. cudnn: Efficient primitives for deep learning. arXiv preprint
arXiv:1410.0759 , 2014.
[5]. Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov.
Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine
Learning Research , 15(1):1929–1958, 2014.
[6]. George E Dahl, Tara N Sainath, and Geoffrey E Hinton. Improving deep neural networks
for lvcsr using rectified linear units and dropout. In Acoustics, Speech and Signal Processing
(ICASSP), 2013 IEEE International Conference on , pages 8609–8613. IEEE, 2013.
[7]. Jiquan Ngiam, Adam Coates, Ahbik Lahiri, Bobby Prochnow, Quoc V Le, and Andrew Y
Ng. On optimization methods for deep learning. In Proceedings of the 28th International
Conference on Machine Learning (ICML-11) , pages 265–272, 2011.
[8]. Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training
by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 , 2015.
[9]. Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint
arXiv:1412.6980 , 2014.
[10]. Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint
arXiv:1607.06450 , 2016.
[11]. Chun-Wei Tsai, Chin-Feng Lai, Ming-Chao Chiang, Laurence T Yang, et al. Data mining for
internet of things: A survey. IEEE Communications Surveys and Tutorials , 16(1):77–97, 2014.
[12]. A Hannun, C Case, J Casper, B Catanzaro, G Diamos, E Elsen, R Prenger, S Satheesh, S Sengupta, A Coates, et al. Deepspeech: scaling up end-to-end speech recognition. 2014. arXiv
preprint arXiv:1412.5567 .
[13]. Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro,
Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, et al. Deep speech 2: Endto-
end speech recognition in english and mandarin. arXiv preprint arXiv:1512.02595 , 2015.
Ronan Collobert and Jason Weston. A unified architecture for natural language processing:
[14]. Deep neural networks with multitask learning. In Proceedings of the 25th international conference
on Machine learning , pages 160–167. ACM, 2008.
[15]. Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine
translation system: Bridging the gap between human and machine translation. arXiv
preprint arXiv:1609.08144 , 2016.
[16]. Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural
networks. In Advances in neural information processing systems , pages 3104–3112, 2014.
[17]. http://www.nvidia.com/object/tesla-m40.html
[18]. https://yq.aliyun.com/articles/57677
[19]. https://en.wikipedia.org/wiki/Amdahl%27s_law
迈向数据智能之路,一个数据工程师的蜕变 ;学大数据技能去哪里,来阿里云数加体验馆:https://data.aliyun.com/experience
