大数据时代,数据保存的重要性不言而喻。在数据保存过程中,数据的备份更是一个值得深入研究的课题。在3月12日下午举行的MongoDB杭州用户交流会上,阿里云技术专家明俨分享了MongoDB Sharding备份和恢复的技术解密。他通过介绍不同的备份方法及备份的主要问题等方面来阐述阿里云在MongoDB Sharding备份和恢复方面所做的工作。
在“MongoDB Sharding杭州用户交流会”上,阿里云技术专家明俨分享了MongoDB Sharding备份和恢复的技术解密。他通过介绍不同的备份方法及备份的主要问题等方面来阐述MongoDB Sharding在备份和恢复方面实施的解决方案。
他的演讲内容主要分为三个方面:
- MongoDB Sharding架构简介
- MongoDB Sharding备份的主要问题
- 阿里云MongoDB Sharding备份
以下内容根据现场分享和幻灯片整理而成。
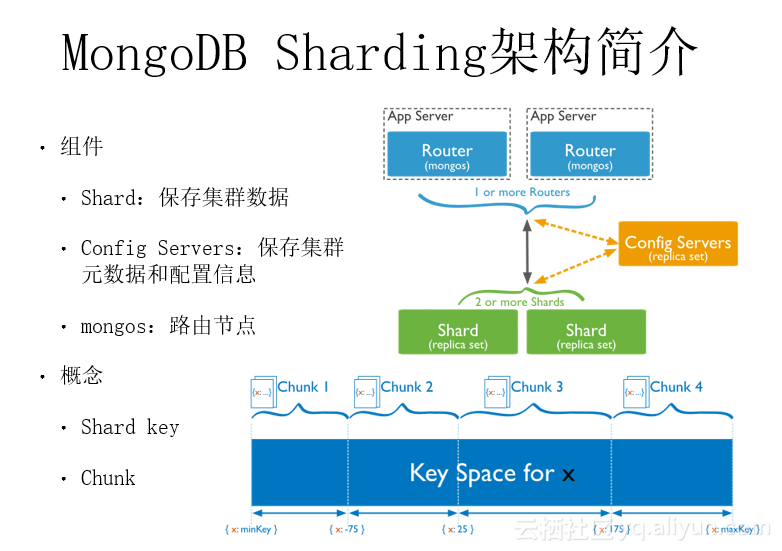
MongoDB Sharding架构组件
由于MongoDB Sharding是一种分布式集群架构,它的备份与传统的单机数据库相比更具有挑战性。
MongoDB Sharding主要有三个组件。
1. shard。shard是保存集群数据的节点,它本身是一个副本集。一个sharding可以有多个shard。2. Config Servers。Config Server是用来保证集群元数据和配置信息的节点。在3.2版本之前,它是一个三镜像的组成,3.2版本之后,也是一个普通的副本集。3. mongos。mongos是一个路由节点。用户在使用的时候通过连接一个或多个mongos来访问整个集群。
MongoDB Sharding是一个分片集群,在使用时需要先对数据进行分片。MongoDB分片的单元是集合,可以对集合制定分片的策略。MongoDB支持两种分片策略:一是基于哈希的分片策略,二是基于range的分片策略。这两种策略有各自适合的场景,可以根据业务的使用情况选择。
数据分片后最主要问题就是如何找到分片,因为数据可能分布在所有shard上。这就是Config Server上保存的最重要的集群元数据。在访问的时候,用户通过mongos访问,Mongos从Config Server获取路由信息(某个分片数据在哪个shard上)并会缓存在本地。Config server主要保存路由信息之外还保存一些配置信息。比如哪些集合做了分片,分片的形式是如何,分片的规则又是如何。这些都是在config server上保存的。
还有两个MongoDB Sharding相关的概念必须了解:
1. Shard key。Shard key就是分片时指定的片键。每个分片集合必须要指定一个shard key,根据这个Shard key对数据进行分片,接下来的写入和读取都需要通过shard key来访问。2. Chunk。Chunk就是Shard key的值所在名字空间的一个小范围的集合。MongoDB会为每个Shard key的值定义一个minKey和一个maxKey。如图上的例子假设Shard key是一个整型字段x,x的值所在名字空间分成了4个chunk,其中minKey到-75之间是第一个chunk,-75到25之间是第二个chunk。25到175之间是第三个chunk,175到maxKey之间是第四个chunk。
总结一下,MongoDB内部把整个Shard key的值所在名字空间分成了若干个chunk,每个shard上保存多个chunk。MongoDB的数据迁移是基于chunk来迁移的,同时Config Server维护的路由信息也是基于chunk的,即它是记录哪一个shard上面有哪几个chunk。
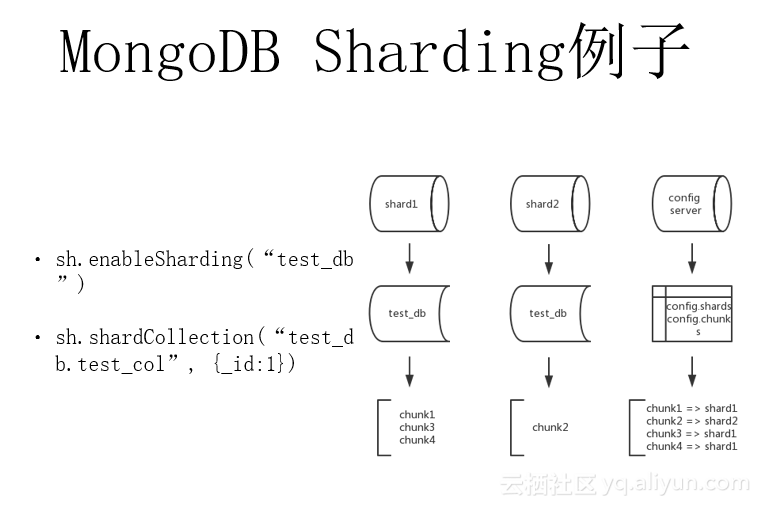
现在我们再从数据层面来回顾一下MongoDB Sharding的节点存的都是哪些数据。假设现在有一个MongoDB Sharding集群,包含两个shard(shard1和shard2)以及一个config server。如果我们对test_db这个数据库开启分片,并按照range策略使用_id作为shard key对test_db里的test_col这个集合开启分片。那么shard1,shard2上存放的是test_db里test_col这个集合的数据。而在config server上则有config.shards、config.chunks等这些表。其中Config.shards表是记录集群里有哪些shard,每个shard的访问地址是什么。而Config.chunks表则记录了每个shard对应存放哪些chunk的分布。
Sharding备份形式
简单介绍完MongoDB Sharding的架构,我们来看看Sharding的备份形式。Sharding备份形式基本上可以分为两种,分别是异构备份恢复和同构备份恢复。
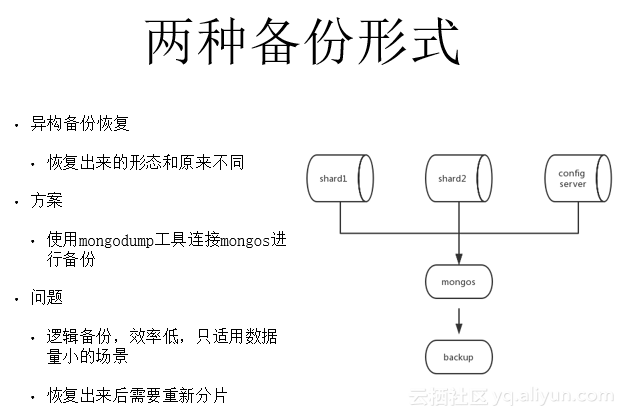
一、异构备份恢复
异构备份恢复指通过备份恢复出来的形态和原来不同,在需要改变形态的情况下可以使用此备份形式。
异构备份恢复的基本方案是通过mongodump(官方的备份工具)连接mongos进行逻辑备份。这种备份形式和访问mongod进行备份类似,它通过mongo提供的访问接口把所有数据一条一条dump出来,因此它的效率比较低,只适用于数据量比较小的场景。在恢复方面,目前的mongorestore只支持把数据无分片的恢复到Sharding的一个Shard节点上面,需要重新对数据进行分片。这也是我把这种形式叫做异构备份恢复的主要原因,它提供了一定的灵活性,可以是你在想对数据重新进行分片时的一种选择。
二、同构备份恢复
和异构备份恢复相对,同构备份恢复就是指恢复出来的形态与原来的架构完全一致,是一种一对一的恢复。比如原来的Sharding有两个shard,一个config server,恢复后还是两个shard和一个config server。同构备份恢复可能没有异构备份恢复那么灵活,但它最大优点就是业务上不需要做修改,原来数据怎么访问,恢复出来的数据也以同样的方式访问即可。同构备份恢复所涉及的问题和解决方案是此次分享的重点。
有效备份的理解
在讲述同构备份恢复之前,我们先来思考一个问题,一个备份要怎样才能称作是有效的。在我看来,一个备份要称为有效需要包含以下几点:
- 备份能够恢复出来,并且数据是正确可用的。如果一个备份恢复不出来,这个备份等于无效的。
- 备份能对应到某个时间点。如果一个备份无法确定它是哪一个时间点,这个备份也不能称为一个有效的备份。备份在需要用来恢复之时,基本都是因为源数据已经出现问题。比如数据被误删,我们需要找到删除数据的时间点之前的备份才能恢复数据。如果备份不能对应到某个时间点,那么我们就无法确定这个备份恢复出来的数据到底是不是是自己所需要的,那这个备份也是无效的。
对MongoDB Sharding而言,最关键的问题是获取能对应到某个时间点的一致的sharding备份,即该备份中,整个sharding集群数据与元数据都是对应到该时间点。同时,整个sharding集群的数据和元数据必须一致。我们知道,Sharding集群包含多个shard节点,以及一个config server节点。每个节点备份出来之间的数据都需要是同一个时间点,这样整个Sharding备份才可以对应到这一个时间点。此外,如果某一个shard备份出来的数据跟config server备份出来的元数据中该shard所负责的chunk信息不一致,那么这个Sharding备份的数据和元数据是不一致的。这可能导致恢复出来后找不到数据。
现在说下MognoDB Sharding同构备份恢复的方案,首先我们能想到的备份方法就是基于单节点备份的扩展。也就是依次为每个节点(包括shards、cs)都进行备份,然后把所有节点备份的集合作为整个Sharding集群的备份。这个方法的主要问题是很难取得一个一致的sharding备份,因为备份过程中有外部修改和内部迁移这两个因素的影响。

影响因素1:外部修改
首先说下第一个影响因素,外部修改。在备份过程中,MongoDB集群持续对外服务。即不停的有新的写入和修改。如下图这个例子:
假设我们现在有一个Sharding集群,包含一个mongos、两个shard和一个config server。并且我们的外部访问情况是每个shard每秒有100个插入请求。假设我们使用逻辑备份,我们知道通过mongodump的『--oplog』选项可以在备份过程中将修改的oplog也一块备份出来,这样我们可以得到一个对应确定时间点的备份。现在假设在12点时我们让每个shard和config server都同时开始备份。因为config server上存储的元数据信息数据量通常比较小,假设只需要5分钟就可以备份完,那么它的备份对应的时间点是12点05分;Shard1数据量也比较少,用8分钟备完,备份的对应时间点是12点08分;Shard2则需要10分钟备份完,备份的对应时间点是12点10分。由于在备份期间每个shard每秒有100个插入请求,这样就会导致所有节点备份的数据无法对应到同一个时间。即,这时候备份出来的数据中,shard1比config server上多几分钟的写入,同样shard2比shard1还要多几分钟的写入,所以整个Sharding备份不能称作一致的备份。
因此外部修改的主要问题就是因每个节点的容量不同导致备份耗时不同,在外部有持续修改的情况下,无法为整个备份确定一个时间点。解决这个问题有一个很简单的方案就是在备份期间停止外部修改。当然这明显会严重影响服务的可用性。因此,可行的方案是在Secondary上做备份,在备份前同时把所有节点的Secondary节点摘掉或加写锁,使得这些Secondary节点暂时不接受同步。这样在这些Secondary节点上统一备份的数据就是摘掉或加写锁时间之后的数据。这个方法最主要的问题一个是备节点在整个备份的过程中都需要断开同步,导致备节点备份完之可能与主节点跟不上同步,另外一个是精确控制各节点同时操作的难度。
影响因素2:内部迁移
接下来我们说下第二个影响因素,内部迁移。因为Sharding数据分布在多个节点,节点会有增减,数据的分布可能会有不均衡的情况出现,所以肯定会发生内部的迁移。
内部迁移以chunk为单位进行迁移,发生chunk迁移原因主要有三点:
- 负载不均衡。Sharding集群会自发进行chunk迁移以使得负载变得均衡。在3.2版本上,每个mongos有一个负载负载均衡的进程叫balancer。balancer会定期检查集群是否需要做负载均衡,它会根据一个算法(根据整个集群的总chunk数和各个shard的chunk数进行判断)判断当前是否需要进行chunk迁移,哪个shard需要迁移,以及迁移到哪里。此外,用户也可以通过moveChunk命令手动发起一个chunk迁移。
- RemoveShard操作需要数据迁移。比如整个集群的数据量变小了,不需要那么多shard了,这时候可以通过RemoveShard操作去把某个Shard下线。下线操作发起后,mongoDB内部会自发地把这个shard上的数据全部迁移到其他的shard上,这个操作会触发chunk迁移。
- MongoDB sharding的Shard Tag功能。Shard Tag功能可以理解为一个标签,可以用来强制指定数据的分布规则。你可以为某个shard打标签,再对shard key的某些分布范围打上相同的标签,这样MongoDB会根据这些标签把相同标签的数据自动迁移到标签所属的shard上。这个功能通常可以用来实现异地分流访问。
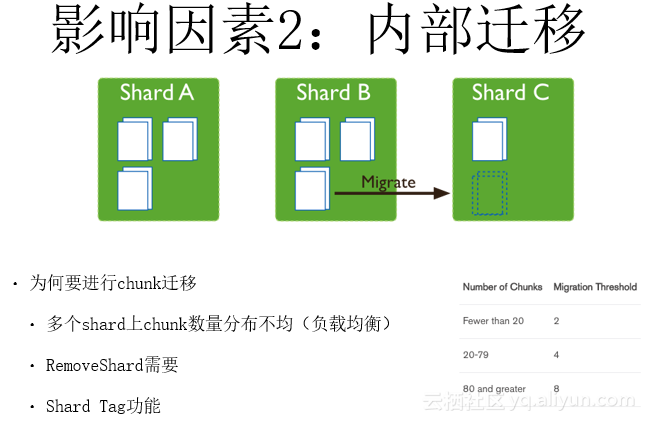
Chunk迁移流程介绍
简单介绍一下chunk迁移的流程。刚刚说过Chunk迁移是由mongos接收到用户发的moveChunk命令,或balancer主动发起的。这里主要分为四个步骤:
第一步:Mongos发一个Movechunk命令给一个Source shard。第二步:Source shard通知Dest shard同步chunk数据。第三步:Dest shard不停地同步chunk数据,同步数据完成时通知Source shard现在同步已经完成了,可以把访问切换到我这了。第四步:Source shard到config server上更新chunk的位置信息。它会告诉config server这个chunk已经迁移到另一个Dest shard上了。接下来的数据请求全部需要到那个shard上。第五步:Source shard删除chunk数据,这个是异步做的。
以上就是一个chunk迁移的主要流程。它涉及到Source shard、Dest shard、config server上的修改,有多个数据修改,因此是比较复杂的一个过程。
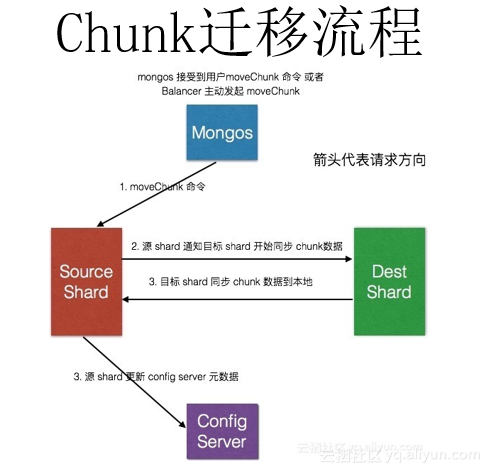
内部迁移的影响
我们来看下内部迁移会有什么影响。举个例子,同样是两个shard,一个config server。他们的初始分布如下图。即chunk1、chunk3、chunk4在shard1上,chunk2在shard2上,config server上记录了chunk1,chunk2,chunk3,chunk4分别所处的位置。
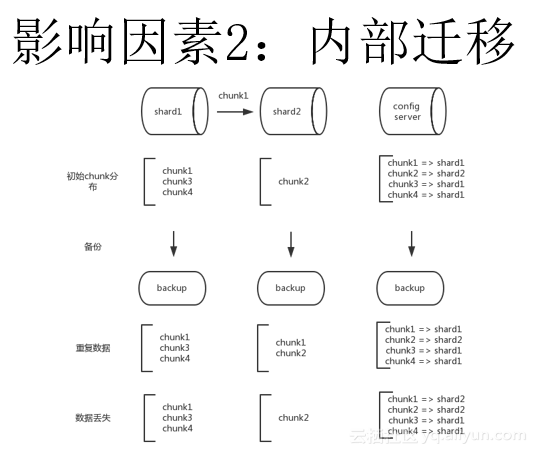
假设现在没有外部修改,我们开始给各个节点做备份。因为例子中第一个shard上有三个chunk,而另外一个shard上只有一个,数据明显是不均衡的,所以MongoDB可能在某个时间点把shard1上的某个chunk迁移到shard2上,使得数据可以均衡。
假设在备份过程中发生了将chunk1从shard1迁移到shard2的操作,这可能导致以下几种结果:
- 备份出了重复数据。先看下config server的备份,因为迁移过程涉及config server的修改(更新chunk1的位置信息),而备份也在进行当中,所以备份出来的数据可能是修改之前的,也有可能是修改之后的。假设备份的数据是在修改前的,那么config server的备份数据还是原来的样子,即chunk1在shard1上。同时假设备份shard2的时候chunk1的数据已经迁移完了,那么shard2的备份会包含chunk1和chunk2。Chunk1在迁移之后还有一个删除动作,它会把自己从shard1上删除。假设shard1上备份的时候chunk1未删除,这时候shard1的备份上也还会有chunk1,chunk3,chunk4。这样就会导致在整个Sharding备份看来,备份出来的数据包含两份chunk1的数据。当然,这个影响并不是很大因为原来的数据都还能找到,而多出来的shard2上的chunk1是一个外部访问不到的数据。因为备份恢复出来后,是按照config server上的路由表来访问。它会认为chunk1这时候还在shard1上面,接下来对chunk1的访问全部还是在shard1上访问。而shard2上的chunk1则是一个野chunk,对访问并无影响。这种野chunk后续可以通过运维手段清除。
- 第二种结果就是备份出来的数据出现了丢失。如果在备份config server的时候,已经是一个修改后的数据,即此时,它已经认为chunk1是在shard2上面了。而在备份shard2的时候,chunk1的数据还未完全拷贝完成,即shard2上面其实还是只有chunk2的数据。备份Shard1时还是chunk1,chunk3,chunk4。这样就会导致恢复出来的数据丢失了chunk1这个数据。因为config server认为chunk1在shard2上面,而shard2上面并没有chunk1这个数据。这时候,shard1上虽然有chunk1,但它也是找不到的。这时问题比较严重,因为造成了数据丢失。
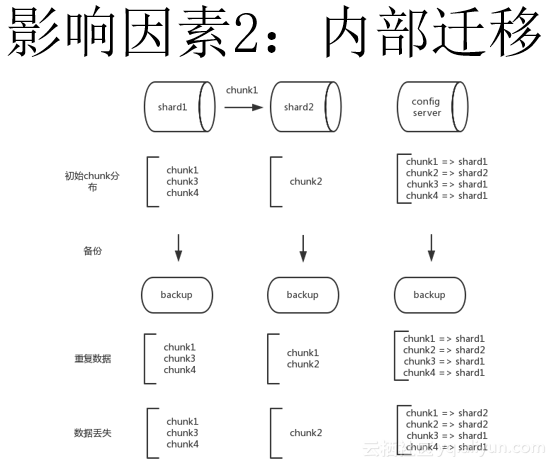
综上,在备份过程中如果发生了内部chunk迁移最主要的问题就是由于chunk迁移涉及多个节点的数据修改,而各个节点备份的时间不同,可能会导致shard备份的数据和config server备份的数据是不一致的,可能导致恢复出来的数据重复或丢失。
这个问题也有一个很简单的解决方式,就是在备份过程中关掉balancer,并且禁止用户发起内部迁移,这样就可以安全地备份。但个解决方式还是不完美,如果备份的数据量大,备份的时间较长,长时间把balancer关掉,集群就无法负载均衡。另外,禁止用户发起内部迁移需要做一些修改。事实上,对于一个云服务提供者来说,禁止用户做内部迁移是比较困难的,因为用户确实会有迁移的需求,他们在某些情况下确实比系统更清楚数据需要迁移到什么地方。
阿里云MongoDB Sharding备份的介绍
接下来介绍一下阿里云MongoDB Sharding的备份和恢复方案。阿里云MongoDB Sharding备份主要采用同构备份恢复的形式,因为异构备份恢复在用户体验上不如同构备份恢复。阿里云MongoDB Sharding备份恢复的方式是克隆一个新的实例出来,会跳到购买页面让用户重新选配。这样这个新实例会和源实例拥有一模一样的架构,你可以在新实例上对数据进行校验,确认没问题后将访问切到新实例上。这里有个前提是需要保证这个新实例的shard节点数大于或等于源shard节点数。比如原来有三个shard,新克隆的实例至少也要有3个shard,可以是4个shard,此时有个shard上的数据为空。
那么阿里云是如何解决刚刚前面提到的同构备份恢复的外部修改和内部迁移这两个问题呢?首先,阿里云MongoDB Sharding备份通过换个角度来解决外部修改问题。既然我们很难在备份过程中保证数据备份出来是同一个时间点的,那我们可以选择在恢复的时候,让所有节点恢复到同一个时间点来实现。这要求具备实现恢复到任意时间点这个功能。而对于内部迁移的问题,阿里云MongoDB Sharding不希望停止balancer,也不希望禁止用户进行内部迁移。我们采用的是牺牲一些恢复时间点的选择,即对恢复时间点进行了一些限制,避开有内部迁移发生的时间段这种方式。这要求需要通过一些手段能够知道Sharding集群在哪些时间段有发生内部迁移,然后禁止用户恢复到这些时间段内的时间点。

所有节点恢复到同一个时间点
我们先说解决第一个问题的关键,恢复到同一个时间点。恢复到同一个时间点的产品定义是把所有实例数据恢复到具体某个时间点(精确到秒,包含该秒)的一个状态,这可以通过定期进行全量备份和持续进行增量备份来实现。
全量备份可以是逻辑备份(通过mongodump),也可以是物理备份(文件系统、逻辑卷快照,或加锁拷贝)。全量备份需要解决的主要问题是它也要能够确定到一个对应的时间点,需要知道数据是属于哪个时间点的。如果使用逻辑备份,mongodump有一个『--oplog】选项,会把备份过程中还在进行的外部修改(oplog)抓出来,进而得到某个一致时间点的备份。这时候你可以选取抓取到的最后一条oplog的时间戳作为这个全量备份的时间点,此时这个全量备份一定包含此时间点之前的所有数据。如果使用物理备份,可以取持久化快照前的最后一条oplog的时间戳作为时间点。
增量备份就是抓取oplog。恢复时选取一个全量备份进行恢复,然后在此基础上进行一个oplog的重放,就可以实现重放到指定的某个时间点。
通过各节点定期的全量备份和持续的增量备份实现恢复到统一个时间点。采用这种方式有一个额外的要求,即各节点的时钟不能相差太多,要有一个时钟同步的机制。现在通常的NTP服务误差基本都可以做到在100毫秒以内,所以可以放心地将各个节点都恢复到某一秒。

逻辑备份和物理备份的比较
这里再说下全量备份中的逻辑备份和物理备份。逻辑备份很简单,通过mongodump和mongorestore来实现。它存在如下几个问题:
问题一:逻辑备份的效率比较低。在备份的过程中dump比较慢,因为它是一条一条数据读出来的,恢复也较慢,需要一条一条往里插。并且恢复还需要重建索引,如果一个索引的数量很大,单独索引重建的时间就会很长,恢复个好几天都是正常的。
问题二:通过逻辑备份来获取时间点快照需要使用【--oplog】选项。这个选项会在全量备份过程中的oplog抓下来。我们知道mongodb的oplog集合是固定大小的,当集合满时会重复利用旧的数据所占的空间用来存放新的数据。因此如果备份时间很长,oplog增长又很快,很有可能会在备份过程中oplog被滚掉,导致备份失败。这里我们阿里云在内核上做了一些改进,能够确保备份过程中oplog能够被抓完。
问题三:逻辑备份在某些场景可能备份失败。第一个场景是如果备份过程中集合被drop掉,会导致备份失败。第二个场景是对唯一索引的处理,如果在备份过程当中,连续delete/insert某个唯一索引的某一个相同的key,可能会导致恢复失败。因为这时候mongodump可能会dump出相同的key,恢复出正确的数据依赖于这当中的oplog被正确回放(对这个相同的key先delete再insert,最后恢复出来还是只有这1个key)。问题就在于mongorestore的行为是恢复完数据后先建索引,然后才重放oplog。这样在建唯一索引的时候,这个地方就过不去了。这两个问题都是我们在线上运维时真实遇到的,目前官方也未解决。
再来说下物理备份。物理备份就是直接拷贝数据文件,它最大的优点就是效率高,还可以解决上述逻辑备份中出现的所有问题。
官方物理备份的方法在官方文档上有介绍。它要求在备份过程中先对节点加一个写锁,然后后才能安全地把数据拷贝走(或实施底层文件系统或逻辑卷的快照),之后再解锁。这也有一个问题,就是备份过程全程加锁,如果数据量大,也有可能发生Secondary节点oplog追丢的问题(加锁通常不会在Primary节点上做)。这里阿里云MongoDB对物理备份做了一些优化,不需要全程加锁就可以实现备份。这个功能接下来也马上就会在线上使用到。

避开内部的迁移操作的方法
接下来介绍Sharding同构备份恢复第二个内部chunk迁移问题的解决。前面提到我们通过对恢复时间点进行限制,避开发生内部迁移的时间段来解决这个问题。我们是通过后台实时分析整个集群有哪些内部迁移操作来做到这一点的。我们记录了所有内部迁移发生的时间段,以用来在恢复时间点选择的时候进行判断。如果恢复的时间点发生在某次内部迁移以内,则会禁止这个恢复操作。当然,由于MognoDB Sharding对chunk有大小限制(默认为64MB),通常一次chunk迁移涉及的时间都非常短,因此这对恢复时间点的选择影响并不大。事实上我们还发现,不止chunk迁移会有影响,如果在备份过程中存在以下的这些操作都会存在一些问题,包括moveChunk、movePrimary、shardCollectio、dropDatabase、dropCollection等。这些操作都是相对比较复杂的操作,涉及到多个节点数据的修改,因此在恢复的时间点的选择上我们会要求用户避开选择发生这些事件的时间范围。

阿里云MongoDB Sharding的备份策略
最后介绍一下阿里云MongoDB Sharding的备份策略,目前在我们在用户创建好一个sharding实例后默认会为所有节点开启定期的全量备份和持续的增量备份。备份默认保留七天,我们允许用户自定义备份的周期和时间。基于我们的Sharding备份恢复的实现,阿里云建议sharding用户根据业务行为自定义设置balancer的运行时间窗口。最好设定在业务的低峰期,比如在夜晚,这样可以保证白天的大部分时间的都是可以恢复的。当然后续阿里云也会提供一个可恢复的时间点的选择,让用户可以直接在控制台上看到具体哪些时间点是可以恢复的。





