作者:周克勇,花名一锤,阿里巴巴计算平台事业部EMR团队技术专家,大数据领域技术爱好者,对Spark有浓厚兴趣和一定的了解,目前主要专注于EMR产品中开源计算引擎的优化工作。
背景介绍
SparkSQL的优越性能背后有两大技术支柱:Optimizer和Runtime。前者致力于寻找最优的执行计划,后者则致力于把既定的执行计划尽可能快地执行出来。Runtime的多种优化可概括为两个层面:
1. 全局优化。从提升全局资源利用率、消除数据倾斜、降低IO等角度做优化,包括自适应执行(Adaptive Execution), Shuffle Removal等。
2. 局部优化。优化具体的Task的执行效率,主要依赖Codegen技术,具体包括Expression级别和WholeStage级别的Codegen。
本文介绍Spark Codegen的技术原理。
Case Study
本节通过两个具体case介绍Codegen的做法。
Expression级别
考虑下面的表达式计算:x + (1 + 2),用scala代码表达如下:
Add(Attribute(x), Add(Literal(1), Literal(2)))语法树如下:
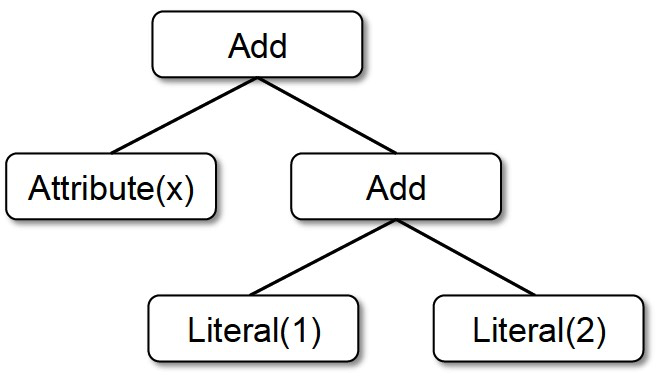
递归求值这棵语法树的常规代码如下:
tree.transformUp {
case Attribute(idx) => Literal(row.getValue(idx))
case Add(Literal(c1),Literal(c2)) => Literal(c1+c2)
case Literal(c) => Literal(c)
}执行上述代码需要做很多类型匹配、虚函数调用、对象创建等额外逻辑,这些overhead远超对表达式求值本身。
为了消除这些overhead,Spark Codegen直接拼成求值表达式的java代码并进行即时编译。具体分为三个步骤:
1. 代码生成。根据语法树生成java代码,封装在wrapper类中:
... // class wrapper
row.getValue(idx) + (1 + 2)
... // class wrapper2. 即时编译。使用Janino框架把生成代码编译成class文件。
3. 加载执行。最后加载并执行。
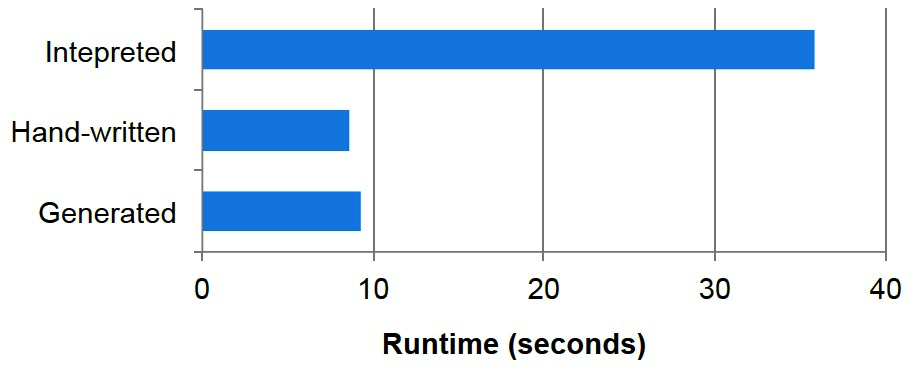
优化前后性能有数量级的提升。
WholeStage级别
考虑如下的sql语句:
select count(*) from store_sales
where ss_item_sk=1000;生成的物理执行计划如下:
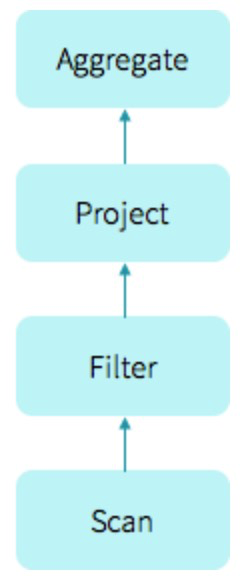
执行该计划的常规做法是使用火山模型(vocano model),每个Operator都继承了Iterator接口,其next()方法首先驱动上游执行拿到输入,然后执行自己的逻辑。代码示例如下:
class Agg extends Iterator[Row] {
def doAgg() {
while (child.hasNext()) {
val row = child.next();
// do aggregation
...
}
}
def next(): Row {
if (!doneAgg) {
doAgg();
}
return aggIter.next();
}
}
class Filter extends Iterator[Row] {
def next(): Row {
var current = child.next()
while (current != null && !predicate(current)) {
current = child.next()
}
return current;
}
}从上述代码可知,火山模型会有大量类型转换和虚函数调用。虚函数调用会导致CPU分支预测失败,从而导致严重的性能回退。
为了消除这些overhead,Spark WholestageCodegen会为该物理计划生成类型确定的java代码,然后类似Expression的做法即时编译和加载执行。本例生成的java代码示例如下(非真实代码,真实代码片段见后文):
var count = 0
for (ss_item_sk in store_sales) {
if (ss_item_sk == 1000) {
count += 1
}
}优化前后性能提升数据如下:

Spark Codegen框架
Spark Codegen框架有三个核心组成部分
1. 核心接口/类
2. CodegenContext
3. Produce-Consume Pattern
接下来详细介绍。
接口/类
四个核心接口:
1. CodegenSupport(接口)
实现该接口的Operator可以将自己的逻辑拼成java代码。重要方法:
produce() // 输出本节点产出Row的java代码
consume() // 输出本节点消费上游节点输入的Row的java代码实现类包括但不限于: ProjectExec, FilterExec, HashAggregateExec, SortMergeJoinExec。
2. WholeStageCodegenExec(类)
CodegenSupport的实现类之一,Stage内部所有相邻的实现CodegenSupport接口的Operator的融合,产出的代码把所有被融合的Operator的执行逻辑封装到一个Wrapper类中,该Wrapper类作为Janino即时compile的入参。
3. InputAdapter(类)
CodegenSupport的实现类之一,胶水类,用来连接WholeStageCodegenExec节点和未实现CodegenSupport的上游节点。
4. BufferedRowIterator(接口)
WholeStageCodegenExec生成的java代码的父类,重要方法:
public InternalRow next() // 返回下一条Row
public void append(InternalRow row) // append一条RowCodegenContext
管理生成代码的核心类。主要涵盖以下功能:
1.命名管理。保证同一Scope内无变量名冲突。
2.变量管理。维护类变量,判断变量类型(应该声明为独立变量还是压缩到类型数组中),维护变量初始化逻辑等。
3.方法管理。维护类方法。
4.内部类管理。维护内部类。
5.相同表达式管理。维护相同子表达式,避免重复计算。
6.size管理。避免方法、类size过大,避免类变量数过多,进行比较拆分。如把表达式块拆分成多个函数;把函数、变量定义拆分到多个内部类。
7.依赖管理。维护该类依赖的外部对象,如Broadcast对象、工具对象、度量对象等。
8.通用模板管理。提供通用代码模板,如genComp, nullSafeExec等。
Produce-Consume Pattern
相邻Operator通过Produce-Consume模式生成代码。
Produce生成整体处理的框架代码,例如aggregation生成的代码框架如下:
if (!initialized) {
# create a hash map, then build the aggregation hash map
# call child.produce()
initialized = true;
}
while (hashmap.hasNext()) {
row = hashmap.next();
# build the aggregation results
# create variables for results
# call consume(), which will call parent.doConsume()
if (shouldStop()) return;
}Consume生成当前节点处理上游输入的Row的逻辑。如Filter生成代码如下:
# code to evaluate the predicate expression, result is isNull1 and value2
if (!isNull1 && value2) {
# call consume(), which will call parent.doConsume()
}下图比较清晰地展示了WholestageCodegen生成java代码的call graph:

Case Study的示例,生成的真实代码如下:
== Subtree 1 / 2 ==
*(2) HashAggregate(keys=[], functions=[count(1)], output=[count(1)#326L])
+- Exchange SinglePartition
+- *(1) HashAggregate(keys=[], functions=[partial_count(1)], output=[count#329L])
+- *(1) Project
+- *(1) Filter (isnotnull(ss_item_sk#13L) && (ss_item_sk#13L = 1000))
+- *(1) FileScan parquet [ss_item_sk#13L] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/home/admin/zhoukeyong/workspace/tpc/tpcds/data/parquet/10/store_sales/par..., PartitionFilters: [], PushedFilters: [IsNotNull(ss_item_sk), EqualTo(ss_item_sk,1000)], ReadSchema: struct<ss_item_sk:bigint>
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage2(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=2
/* 006 */ final class GeneratedIteratorForCodegenStage2 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean agg_initAgg_0;
/* 010 */ private boolean agg_bufIsNull_0;
/* 011 */ private long agg_bufValue_0;
/* 012 */ private scala.collection.Iterator inputadapter_input_0;
/* 013 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] agg_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[1];
/* 014 */
/* 015 */ public GeneratedIteratorForCodegenStage2(Object[] references) {
/* 016 */ this.references = references;
/* 017 */ }
/* 018 */
/* 019 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 020 */ partitionIndex = index;
/* 021 */ this.inputs = inputs;
/* 022 */
/* 023 */ inputadapter_input_0 = inputs[0];
/* 024 */ agg_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 025 */
/* 026 */ }
/* 027 */
/* 028 */ private void agg_doAggregateWithoutKey_0() throws java.io.IOException {
/* 029 */ // initialize aggregation buffer
/* 030 */ agg_bufIsNull_0 = false;
/* 031 */ agg_bufValue_0 = 0L;
/* 032 */
/* 033 */ while (inputadapter_input_0.hasNext() && !stopEarly()) {
/* 034 */ InternalRow inputadapter_row_0 = (InternalRow) inputadapter_input_0.next();
/* 035 */ long inputadapter_value_0 = inputadapter_row_0.getLong(0);
/* 036 */
/* 037 */ agg_doConsume_0(inputadapter_row_0, inputadapter_value_0);
/* 038 */ if (shouldStop()) return;
/* 039 */ }
/* 040 */
/* 041 */ }
/* 042 */
/* 043 */ private void agg_doConsume_0(InternalRow inputadapter_row_0, long agg_expr_0_0) throws java.io.IOException {
/* 044 */ // do aggregate
/* 045 */ // common sub-expressions
/* 046 */
/* 047 */ // evaluate aggregate function
/* 048 */ long agg_value_3 = -1L;
/* 049 */ agg_value_3 = agg_bufValue_0 + agg_expr_0_0;
/* 050 */ // update aggregation buffer
/* 051 */ agg_bufIsNull_0 = false;
/* 052 */ agg_bufValue_0 = agg_value_3;
/* 053 */
/* 054 */ }
/* 055 */
/* 056 */ protected void processNext() throws java.io.IOException {
/* 057 */ while (!agg_initAgg_0) {
/* 058 */ agg_initAgg_0 = true;
/* 059 */ long agg_beforeAgg_0 = System.nanoTime();
/* 060 */ agg_doAggregateWithoutKey_0();
/* 061 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* aggTime */).add((System.nanoTime() - agg_beforeAgg_0) / 1000000);
/* 062 */
/* 063 */ // output the result
/* 064 */
/* 065 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
/* 066 */ agg_mutableStateArray_0[0].reset();
/* 067 */
/* 068 */ agg_mutableStateArray_0[0].zeroOutNullBytes();
/* 069 */
/* 070 */ agg_mutableStateArray_0[0].write(0, agg_bufValue_0);
/* 071 */ append((agg_mutableStateArray_0[0].getRow()));
/* 072 */ }
/* 073 */ }
/* 074 */
/* 075 */ }
== Subtree 2 / 2 ==
*(1) HashAggregate(keys=[], functions=[partial_count(1)], output=[count#329L])
+- *(1) Project
+- *(1) Filter (isnotnull(ss_item_sk#13L) && (ss_item_sk#13L = 1000))
+- *(1) FileScan parquet [ss_item_sk#13L] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/home/admin/zhoukeyong/workspace/tpc/tpcds/data/parquet/10/store_sales/par..., PartitionFilters: [], PushedFilters: [IsNotNull(ss_item_sk), EqualTo(ss_item_sk,1000)], ReadSchema: struct<ss_item_sk:bigint>
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean agg_initAgg_0;
/* 010 */ private boolean agg_bufIsNull_0;
/* 011 */ private long agg_bufValue_0;
/* 012 */ private long scan_scanTime_0;
/* 013 */ private boolean outputMetaColumns;
/* 014 */ private int scan_batchIdx_0;
/* 015 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] scan_mutableStateArray_3 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[3];
/* 016 */ private org.apache.spark.sql.vectorized.ColumnarBatch[] scan_mutableStateArray_1 = new org.apache.spark.sql.vectorized.ColumnarBatch[1];
/* 017 */ private scala.collection.Iterator[] scan_mutableStateArray_0 = new scala.collection.Iterator[1];
/* 018 */ private org.apache.spark.sql.execution.vectorized.OffHeapColumnVector[] scan_mutableStateArray_2 = new org.apache.spark.sql.execution.vectorized.OffHeapColumnVector[1];
/* 019 */
/* 020 */ public GeneratedIteratorForCodegenStage1(Object[] references) {
/* 021 */ this.references = references;
/* 022 */ }
/* 023 */
/* 024 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 025 */ partitionIndex = index;
/* 026 */ this.inputs = inputs;
/* 027 */
/* 028 */ scan_mutableStateArray_0[0] = inputs[0];
/* 029 */ outputMetaColumns = false;
/* 030 */ scan_mutableStateArray_3[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 031 */ scan_mutableStateArray_3[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 032 */ scan_mutableStateArray_3[2] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 033 */
/* 034 */ }
/* 035 */
/* 036 */ private void agg_doAggregateWithoutKey_0() throws java.io.IOException {
/* 037 */ // initialize aggregation buffer
/* 038 */ agg_bufIsNull_0 = false;
/* 039 */ agg_bufValue_0 = 0L;
/* 040 */
/* 041 */ if (scan_mutableStateArray_1[0] == null) {
/* 042 */ scan_nextBatch_0();
/* 043 */ }
/* 044 */ while (scan_mutableStateArray_1[0] != null) {
/* 045 */ int scan_numRows_0 = scan_mutableStateArray_1[0].numRows();
/* 046 */ int scan_localEnd_0 = scan_numRows_0 - scan_batchIdx_0;
/* 047 */ for (int scan_localIdx_0 = 0; scan_localIdx_0 < scan_localEnd_0; scan_localIdx_0++) {
/* 048 */ int scan_rowIdx_0 = scan_batchIdx_0 + scan_localIdx_0;
/* 049 */ if (!scan_mutableStateArray_1[0].validAt(scan_rowIdx_0)) { continue; }
/* 050 */ do {
/* 051 */ boolean scan_isNull_0 = scan_mutableStateArray_2[0].isNullAt(scan_rowIdx_0);
/* 052 */ long scan_value_0 = scan_isNull_0 ? -1L : (scan_mutableStateArray_2[0].getLong(scan_rowIdx_0));
/* 053 */
/* 054 */ if (!(!scan_isNull_0)) continue;
/* 055 */
/* 056 */ boolean filter_value_2 = false;
/* 057 */ filter_value_2 = scan_value_0 == 1000L;
/* 058 */ if (!filter_value_2) continue;
/* 059 */
/* 060 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[2] /* numOutputRows */).add(1);
/* 061 */
/* 062 */ agg_doConsume_0();
/* 063 */
/* 064 */ } while(false);
/* 065 */ // shouldStop check is eliminated
/* 066 */ }
/* 067 */ scan_batchIdx_0 = scan_numRows_0;
/* 068 */ scan_mutableStateArray_1[0] = null;
/* 069 */ scan_nextBatch_0();
/* 070 */ }
/* 071 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* scanTime */).add(scan_scanTime_0 / (1000 * 1000));
/* 072 */ scan_scanTime_0 = 0;
/* 073 */
/* 074 */ }
/* 075 */
/* 076 */ private void scan_nextBatch_0() throws java.io.IOException {
/* 077 */ long getBatchStart = System.nanoTime();
/* 078 */ if (scan_mutableStateArray_0[0].hasNext()) {
/* 079 */ scan_mutableStateArray_1[0] = (org.apache.spark.sql.vectorized.ColumnarBatch)scan_mutableStateArray_0[0].next();
/* 080 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(scan_mutableStateArray_1[0].numRows());
/* 081 */ scan_batchIdx_0 = 0;
/* 082 */ scan_mutableStateArray_2[0] = (org.apache.spark.sql.execution.vectorized.OffHeapColumnVector) (outputMetaColumns ?
/* 083 */ scan_mutableStateArray_1[0].column(0, true) : scan_mutableStateArray_1[0].column(0));
/* 084 */
/* 085 */ }
/* 086 */ scan_scanTime_0 += System.nanoTime() - getBatchStart;
/* 087 */ }
/* 088 */
/* 089 */ private void agg_doConsume_0() throws java.io.IOException {
/* 090 */ // do aggregate
/* 091 */ // common sub-expressions
/* 092 */
/* 093 */ // evaluate aggregate function
/* 094 */ long agg_value_1 = -1L;
/* 095 */ agg_value_1 = agg_bufValue_0 + 1L;
/* 096 */ // update aggregation buffer
/* 097 */ agg_bufIsNull_0 = false;
/* 098 */ agg_bufValue_0 = agg_value_1;
/* 099 */
/* 100 */ }
/* 101 */
/* 102 */ protected void processNext() throws java.io.IOException {
/* 103 */ while (!agg_initAgg_0) {
/* 104 */ agg_initAgg_0 = true;
/* 105 */ long agg_beforeAgg_0 = System.nanoTime();
/* 106 */ agg_doAggregateWithoutKey_0();
/* 107 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[4] /* aggTime */).add((System.nanoTime() - agg_beforeAgg_0) / 1000000);
/* 108 */
/* 109 */ // output the result
/* 110 */
/* 111 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[3] /* numOutputRows */).add(1);
/* 112 */ scan_mutableStateArray_3[2].reset();
/* 113 */
/* 114 */ scan_mutableStateArray_3[2].zeroOutNullBytes();
/* 115 */
/* 116 */ scan_mutableStateArray_3[2].write(0, agg_bufValue_0);
/* 117 */ append((scan_mutableStateArray_3[2].getRow()));
/* 118 */ }
/* 119 */ }
/* 120 */
/* 121 */ }阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区数个Spark技术同学每日在线答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!