本场视频链接:https://developer.aliyun.com/live/1547?spm=a2c6h.12873581.0.0.71671566iIzpz5&groupCode=apachespark
本场PPT资料:https://www.slidestalk.com/AliSpark/201960935
EMR E-Learning平台
EMR E-Learning平台基于的是大数据和AI技术,通过算法基于历史数据来构建机器学习模型,从而进行训练与预测。目前机器学习被广泛应用到很多领域,如人脸识别、自然语言处理、推荐系统、计算机视觉等。近年来,大数据以及计算能力的提升,使得AI技术有了突飞猛进的发展。
机器学习中重要的三要素是算法、数据和算力。而EMR本身是一个大数据平台,平台之上拥有多种数据,比如传统的数据仓库数据、图像数据;EMR有很强的调度能力,可以很好地吊调度GPU和CPU资源;其结合机器学习算法,就可以成为一个比较好的AI平台。
典型的AI开发流程如下图所示:首先是数据收集,手机、路由器或者日志数据进入大数据框架Data Lake;然后是数据处理,收集到的数据需要通过传统的大数据ETL或特征工程进行处理;其次是模型训练,经过特征工程或ETL处理后的数据会进行模型的训练;最后对训练模型进行评估和部署;模型预测的结果会再输入到大数据平台进行处理分析,整个过程循环往复。
下图展示了AI开发的流程,左侧是单机或者集群,主要进行AI训练和评估,包含数据存储;右侧是大数据存储,主要进行大数据处理,如特征工程等,同时可以利用左侧传输的机器学习模型进行预测。
AI开发的现状主要有以下两点:
• 两套集群运维复杂:从图中可以看出,AI开发涉及的两套集群是分离的,需要单独维护,运维成本复杂,容易出错。
• 训练效率较低:左右两侧集群需要大量数据传输和模型传输,带来较高的端到端训练的延迟。
EMR作为统一的大数据平台,包含了很多特性。最底层基础设施层,其支持GPU和CPU机器;数据存储层包括HDFS和阿里云OSS;数据接入层包括Kafka和Flume;资源调度层计算引擎包括 YARN、K8S和Zookeeper;计算引擎最核心的是E-learning平台,基于目前比较火的开源系统Spark,这里的Spark用的是jindo Spark,是EMR团队基于Spark改造和优化而推出的适用于AI场景下的版本,除此之外,还有PAI TensorFlow on Spark;最后是计算分析层,提供了数据分析、特征工程、AI训练以及Notebook的功能,方便用户来使用。
EMR平台的特性主要有以下几点:
• 统一的资源管理与调度:支持CPU、Mem和GPU的细粒度的资源调度和分配,支持YARN和K8S的资源调度框架;
• 多种框架支持:包括TensorFlow、MXNet和Caffe等;
• Spark通用的数据处理框架:提供Data Source API来方便各类数据源的读取,MLlib pipeline广泛用于特征工程;
• Spark+深度学习框架:Spark和深度学习框架的集成支持,包括高效的Spark和TensorFlow之间的数据传输,Spark资源调度模型支持分布式深度学习训练;
• 资源监控与报警:EMR APM系统提供完善的应用程序和集群监控多种报警方式;
• 易用性:Jupyter notebook以及Python多环境部署支持,端到端机器学习训练流程等。
EMR E-Learning集成了PAI TensorFlow,其支持对深度学习的优化和对大规模稀疏场景的优化。
TensorFlow on Spark
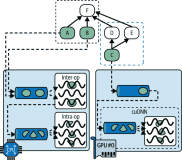
经过市场调研发现,大多数的客户在深度学习之前的数据ETL和特征工程阶段使用的都是开源计算框架Spark,之后的阶段广泛使用的是TensorFlow,因此就有了将TensorFlow和Spark有机结合的目标。TensorFlow on Spark主要包含了下图中的六个具体设计目标。
TensorFlow on Spark从最底层来讲实际上是PySpark应用框架级别的封装。框架中实现的主要功能包括:首先调度用户特征工程任务,然后再调度深度学习TensorFlow任务,除此之外还需要将特征工程的数据高效快速地传输给底层的PAI TensorFlow Runtime进行深度学习和机器学习的训练。由于Spark目前不支资源的异构调度,假如客户运行的是分布式TensorFlow, 就需要同时运行两个任务(Ps任务和Worker任务),根据客户需求的资源来产生不同的Spark executor,Ps任务和Worker任务通过Zookeeper来进行服务注册。框架启动后会将用户写的特征工程任务调度到executor中执行,执行后框架会将数据传输给底层的PAI TensorFlow Runtime进行训练,训练结束后会将数据保存到Data Lake中,方便后期的模型发布。
在机器学习和深度学习中,数据交互是可以提升效率的点,因此在数据交互部分,TensorFlow on Spark做了一系列优化。具体来讲采用了Apache Arrow进行高速数据传输,将训练数据直接喂给API TensorFlow Runtime,从而加速整个训练流程。
TensorFlow on Spark的容错机制如下图所示:最底层依赖TensorFlow的Checkpoints机制,用户需要定时的将训练模型Chenpoint到Data Lake中。当重新启动一个TensorFlow的时候,会读取最近的Checkpoint进行训练。容错机制会根据模式不同有不同的处理方式,针对分布式任务,会启动Ps和Worker任务,两个任务直接存在daemon进程,监控对应任务运行情况;对于MPI任务,通过Spark Barrier Execution机制进行容错,如果一个task失败,会标记失败并重启所有task,重新配置所有环境变量;TF任务负责读取最近的Checkpoint。
TensorFlow on Spark的功能和易用性主要体现在以下几点:
• 部署环境多样:支持指定conda,打包python运行时virtual env 支持指定docker
• TensorFlow 架构支持:支持分布式TensorFlow原生PS架构和分布式Horovod MPI架构
• TensorFlow API支持:支持分布式TensorFlow Estimator高阶API和分布式TensorFlow Session 低阶API
• 快速支持各种框架接入:可以根据客户需求加入新的AI框架,如MXNet
EMR客户有很多来自于互联网公司,广告和推送的业务场景比较常见,下图是一个比较典型的广告推送业务场景。整个流程是EMR客户通过Kafka将日志数据实时推送到Data Lake中,TensorFlow on Spark负责的是上半部分流程,其中可以通过Spark的工具如SparkSQL、MLlib等对实时数据和离线数据进行ETL和特征工程,数据训练好之后可以通过TensorFlow 框架高效地喂给PAI TensorFlow Runtime进行大规模训练和优化,然后将模型存储到Data Lake中。
在API层面,TensorFlow on Spark提供了一个基类,该基类中包含了三个方法需要用户去实现:pre_train、shutdown和train。pre_train是用户需要做的数据读取、ETL和特征工程等任务,返回的是Spark的DataFrame对象;shutdown方法实现用户长连接资源的释放;train方法是用户之前在TensorFlow中实现的代码,如模型、优化器、优化算子的选择。最后通过pl_submit命令来提交TensorFlow on Spark的任务。
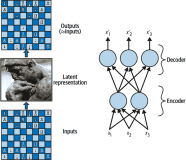
下图是推荐系统FM的样例,FM是一个比较常见的推荐算法,具体场景是给电影评分,根据客户对之前电影评分、电影类型和发布时间为用户推荐潜在的电影。左侧是一个特征工程,用户可以使用Spark data source API读取电影和评分信息,原生支持Spark所有操作,如join、ETL处理等;右侧是TensorFlow,进行模型、优化器的选择。目前整个系统的代码已经开源到Github。
最后总结一下,EMR E-Learning 平台将大数据处理、深度学习、机器学习、数据湖、GPUs功能特性紧密的结合,提供一站式大数据与机器学习平台;TensorFlow on Spark 提供了高效的数据交互流程以及完备的机器学习训练流程,将Spark与TensorFlow结合,借助 PAI TensorFlow,助力用户加速训练;目前E-Learning平台在公有云服务不同的客户,成功案例,CPU集群规模超过1000,GPU集群规模超过100。
阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区数个Spark技术同学每日在线答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!