对于复杂sql且关联表较多的情况,数据倾斜是很常见的问题,几乎可以说不倾斜才是少见情况,而在不能改变原始数据(不能采用多阶段分段聚合),不能改变spark源码的情况下,除了调整各种参数,可操作的空间并不多。
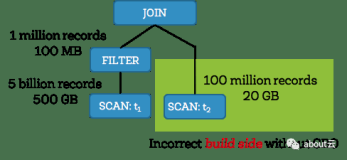
对于表之间的join操作,一般来说我们都知道有map join和reduce join两种情况。因为reduce端会按map输出的key的分布处理相应的数据,在数据倾斜的情况下就会造成单个task压力过大,拖累整个job时间,甚至OOM等诸多问题。而如果能在map端完成join,就会极大的减小reduce端的压力,提升并行度。
map端的join适用于在join的表比较小的情况,另外如字典表这种的与其他表join时,因为本身数据就很少,势必会造成数据严重的倾斜,因而这种情况下使用map端的join就再适合不过。在sparksql中,并没有直接提供如map join之类的关键字,但是也不是没有办法,spark提供了broadhashjoin。要注意的是单纯设置broadcastjoin的大小并没有效果,看下面这个例子,这是一张大表和一个字典表的join,可以看到,两张表的处理是一样的,join在reduce端,从实际的运行情况看,也如预料的一样,倾斜严重。
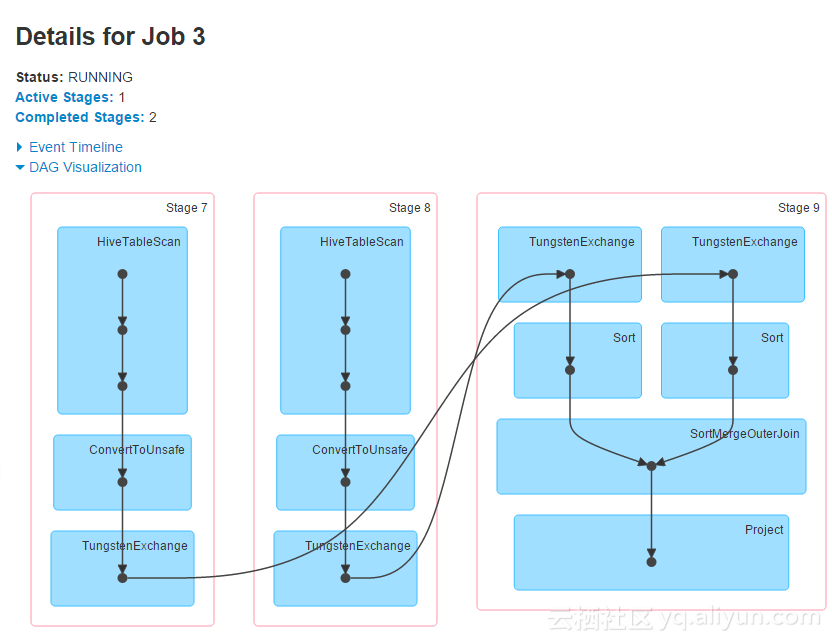
我的项目里使用的是hivecontext,就是spark on hive,因而实现map join的方式就是讲小表进行cache,然后再做查询,看下优化后的执行计划,变成一个stage了,实际的运行时间也提升明显。原来的sql不需要修改,只需要对小表执行
CACHE TABLE xx as select * from xx