一、实验目的:
在DataWorks业务流程开发过程。一个业务流程通常是由很多个数据同步、数据开发节点组成的。这很多个业务节点的上下游节点的连接通过执行顺序先后进行连接,系统自动就行上下游解析。这里主要用于测试在一个业务流程过程中根据业务需求进行节点连接之后自动解析上下游是否会发生错误。
二、实验步骤:
1、创建一个业务流程
2、创建一个start节点
3、创建五个数据同步节点
4、创建五个数据开发节点
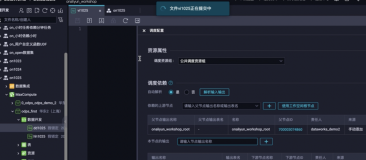
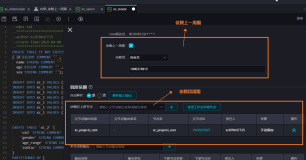
5、根据业务需求进行节点上下文连线,如下图所示:
6、配置start节点的上游为工作空间根节点,点击提交
7、检查每个节点的上下游节点通过连接之后自动解析的结果和业务需求是否一致。
业务需求:
(1)start节点:
工作空间根节点--->start节点--->LogHub(数据同步)、MaxCompute(数据同步)、Hadoop(数据同步)、DataHub(数据同步)、Kafka(数据同步)、Dandu(数据开发)
(2)Hadoop(数据同步)
start--->Hadoop(数据同步)--->hadoopp(数据开发)
(3)LogHub(数据同步)
start--->LogHub(数据同步)--->hadoopp(数据开发)
(4)MaxCompute(数据同步)
start--->MaxCompute(数据同步)--->hadoopp(数据开发)
(5)DataHub(数据同步)
start--->DataHub(数据同步)--->loghubb(数据开发)
(6)Kafka(数据同步)
start--->Kafka(数据同步)--->loghubb(数据开发)
(7)Dandu(数据开发)
start--->Dandu(数据开发)--->dandu_jiedian(数据开发)
(8)hadoopp(数据开发)
Hadoop(数据同步)、LogHub(数据同步)、MaxCompute(数据同步)--->hadoopp(数据开发)--->huiju_jiedian(数据开发)
(9)loghubb(数据开发)
DataHub(数据同步)、Kafka(数据同步)--->loghubb(数据开发)--->huiju_jiedian(数据开发)
(10)dandu_jiedian(数据开发)
Dandu(数据开发)--->dandu_jiedian(数据开发)
(11)huiju_jiedian(数据开发)
loghubb(数据开发)、hadoopp(数据开发)--->huiju_jiedian(数据开发)
三、实验结果:
检测自动解析节点上下文依赖和业务需求的依赖关系是一致的。
四、实验总结:
在调度系统中,每一个工作空间中默认会创建一个projectname_root节点作为根节点。如果本节点没有上游节点,可以直接依赖根节点。
依赖属性中配置节点的上游依赖,表示即使当前节点的实例已经到定时时间,也必须等待上游节点的实例运行完毕,才会触发运行。
点击链接加入 MaxCompute开发者社区2群 https://h5.dingtalk.com/invite-page/index.html?bizSource=____source____&corpId=dingb682fb31ec15e09f35c2f4657eb6378f&inviterUid=E3F28CD2308408A8&encodeDeptId=0054DC2B53AFE745
或扫码加入