
江苏佰腾科技有限公司是一家从事专利信息应用、专利咨询服务的企业,是国内知名的知识产权服务公司,以佰腾网和专利巴巴为网络平台,面向国内外用户提供知识产权、科技创新整体解决方案。2014年起,公司积极推进互联网转型,实施“互联网+专利”计划,开发了国内首家专利电商平台—专利巴巴,通过专利巴巴项目的实施,使公司转型为知识产权领域内的互联网公司,并采用B2B、O2O线上线下相结合的模式为客户提供全方位的、全流程的知识产权一体化服务。
用互联网的思维和技术来改造传统的知识产权行业,在这个过程中,大数据技术的应用是佰腾科技最重要的手段之一, 下面简单代入一下专利的概念。
无处不在的专利
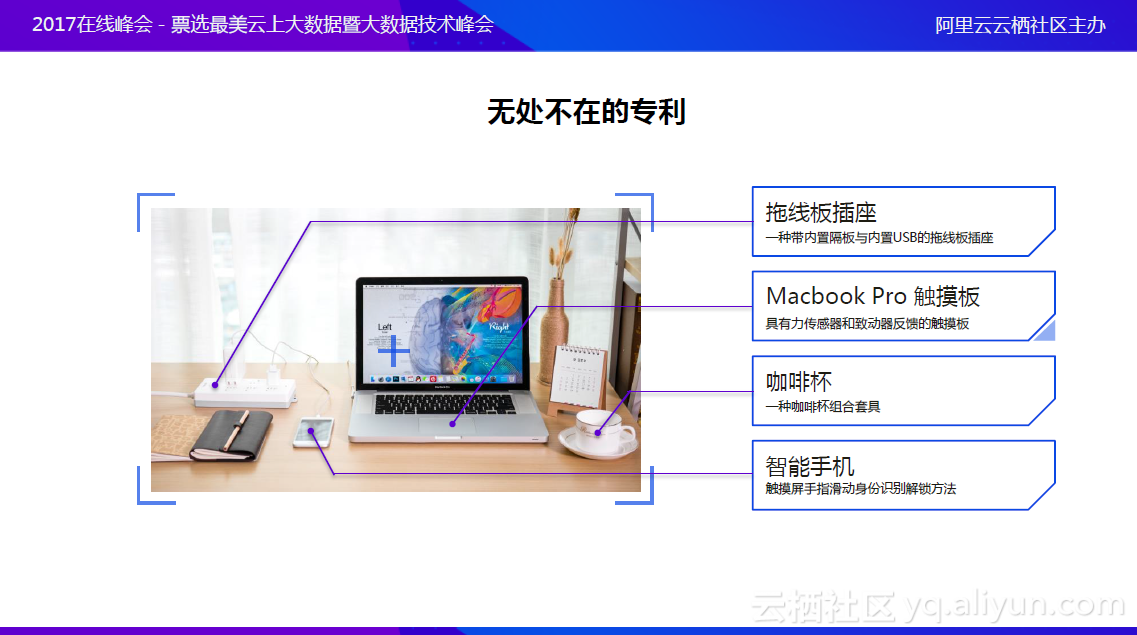
专利技术通过对技术信息的公开换取法律保护,全球绝大多数国家都已经建立了完善的专利机制和法律法规。很多公司争相购买专利,以此获得市场上独占的商业价值,提高自身技术竞争门槛。大公司间专利的竞争尤为激烈,最著名的案例便是苹果三星智能手机世纪之战。苹果公司认为三星推出的一款手机在屏幕等方面进行了抄袭,经判决,美国联邦法院裁定三星侵犯了苹果手机外观专利,需赔偿1.2亿美元。三星不服,并准备于3月29日前提交专门针对“滑动解锁专利”的不利裁决提请复审令,申请将案件移交至最高法院审理。如果被最高法院接受审理,美国联邦上诉法院的裁决将被重新判决,这场长达数年之久的世纪大战至今仍未迎来终结之日。那么,为什么一般人感觉不到专利的存在和价值呢?主要在于专利是非常专业的法律文书,其内容晦涩难懂。虽然现在搜索引擎很普遍,但若想从众多信息数据中找到一篇有价值的专利文献为我们所用,如果没有相应领域的技术知识和专业的检索能力,几乎不可能。与此同时,市场上能提供给大众进行检索的专利信息应用功能非常有限,基本上只能被专业人士所使用。
佰腾专利大数据平台的演化和上云
据悉,全球90%的最新技术通过专利这种方式首次公开,专利的范畴涵盖了全球绝大多数的最新技术。专利是对知识的保护。怎样将保护的最大价值挖掘出来?就需要通过大数据技术的运用,使专利信息应用更简便、更直观,让大众看懂专利,让专利信息变成一种技术知识,让大家学习、了解、研究,从而发现技术创新的Idea,提高创新效率,降低无效创新。
萌芽时期
佰腾在专利信息应用上研究多年,一直致力于解决一个问题:让专利信息应用变得大众化。
佰腾在专利技术创新方面经历了3个阶段:
萌芽时期
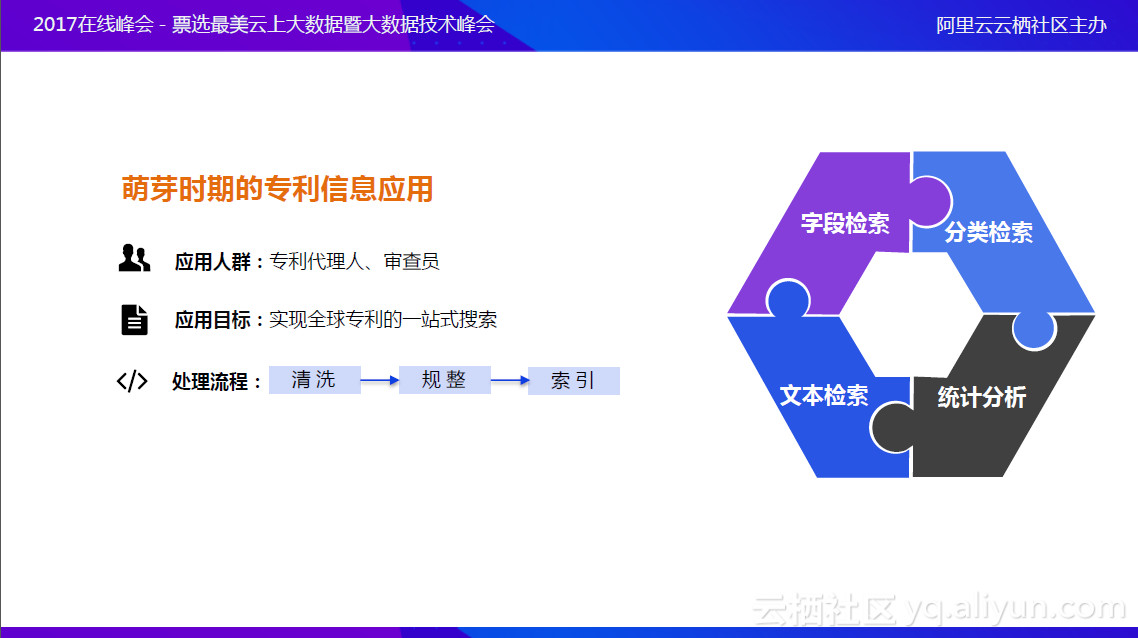
主要的应用目标是实现全球专利的一站式搜索。这个目标非常简单,因为一开始每个国家的专利信息公布,都由相应的主管知识产权的机构负责,要检索专利,必须访问各个国家的专利局网站,专利分布非常散乱;此外,每个国家都是以自己的母语公布专利信息,语言是非常大的障碍,应用专利信息门槛很高。佰腾对大数据进行处理、清洗、规整再索引,最后形成可利用数据。在这个阶段能提供给用户的功能也很简单,如字段检索,分类检索,文本检索,统计分析等。
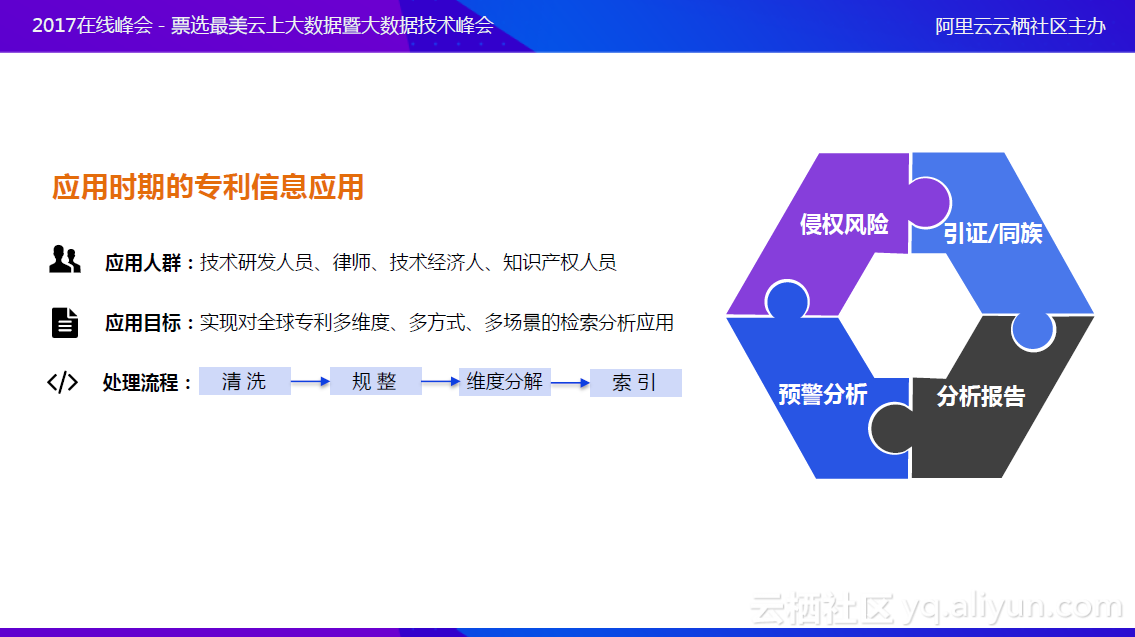
应用时期
随着国内经济的快速发展,越来越多的企业开始投身到国际市场的竞争,首先面临的问题不是国外企业带来的市场压力,而是国外企业已提前准备好的专利大坝。有一个客户曾经参加欧洲的产品展销会,将一台几十万的设备运抵展会现场,准备第二天参展。但在参展的前一天晚上得到消息,当地的知识产权部门要来查处他们专利侵权的问题。虽然不清楚是否真的侵权,但是肯定不是空穴来风。在该国,如果查处了侵犯了当地的知识产权,不仅产品会被扣押,参展人员也要被扣押,在当地接受审判。于是为确保人员不出问题,他们当即坐飞机回国,造成了非常大的损失。
在应用时期,需要关注专利会不会被侵权以及如何应对,这就需要更精确、更全面地检索专利,保证没有漏检。于是佰腾在处理流程中加了一项维度分解,把专利中更深入的信息拆解出来,提供给相应人员进行检索,形成侵权风险检查、预警分析、分析报告等功能。
大数据时期
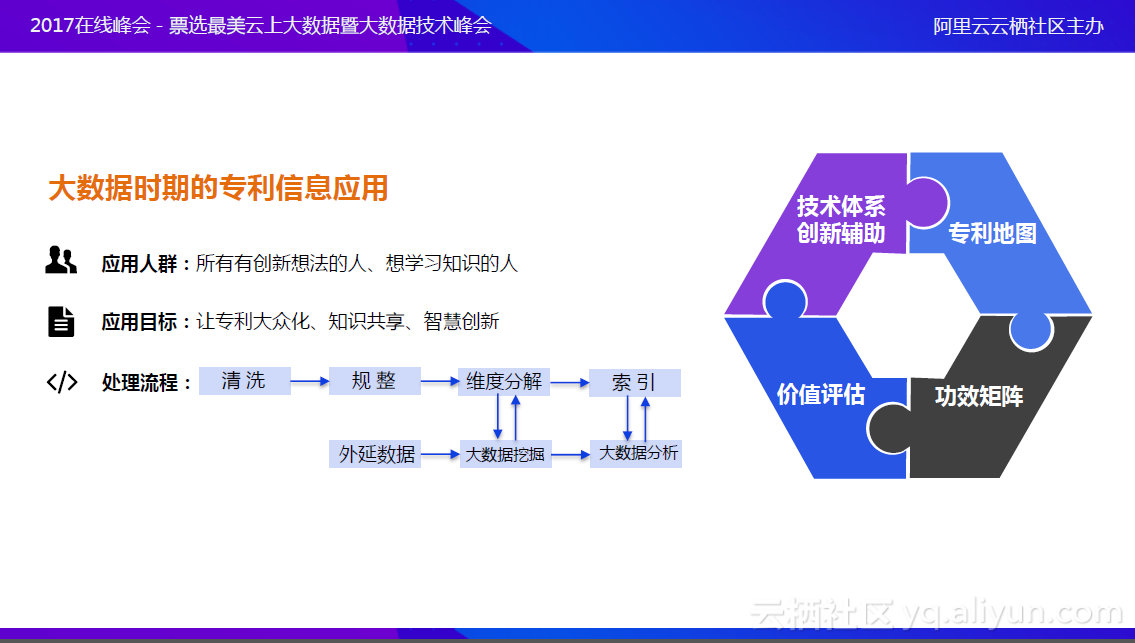
近几年,中国提倡从中国制造往中国创造的方向发展。一些企业,特别是需要出口的企业开始慢慢认识到,不仅要在技术上做突围,同时也要构筑自己的专利壁垒,就一定需要创新。对企业来讲,创新投入的费用非常大,因此要找捷径,要看现在的行业领域里面技术的发展程度。即站在别人的基础上发展自己的技术,这才是创新最高效的办法。于是,找到技术的热点和空白点,这就是专利信息应用的新的课题。在这个基础上,则不能单纯把专利信息的内容简单地拆解出来,还需要帮企业发现技术的热点和空白点,需要通过大数据挖掘、大数据应用进行分析。因此在处理流程中,佰腾增加了大数据挖掘和大数据分析的过程,不仅仅使用专利数据进行数据挖掘,还会更多地引用期刊文献、法律诉讼信息、企业信息,并将其整合。这个阶段,可以给企业提供专利地图、价值评估、技术体系创新辅助、功效矩阵等功能。
现在整个专利大数据的规模,拥有全球1.3亿多条数据,每一条数据挖掘出200多项数据点,能够提供给客户可检索分析的数据总量为100亿多条。借助阿里云数加提供的运算能力的支撑,将专利的外延信息纳入到专利相关的数据挖掘内,数据维度点将在未来的两到三年之内成倍增加,可检索分析的数据量或很快超过1万亿条。
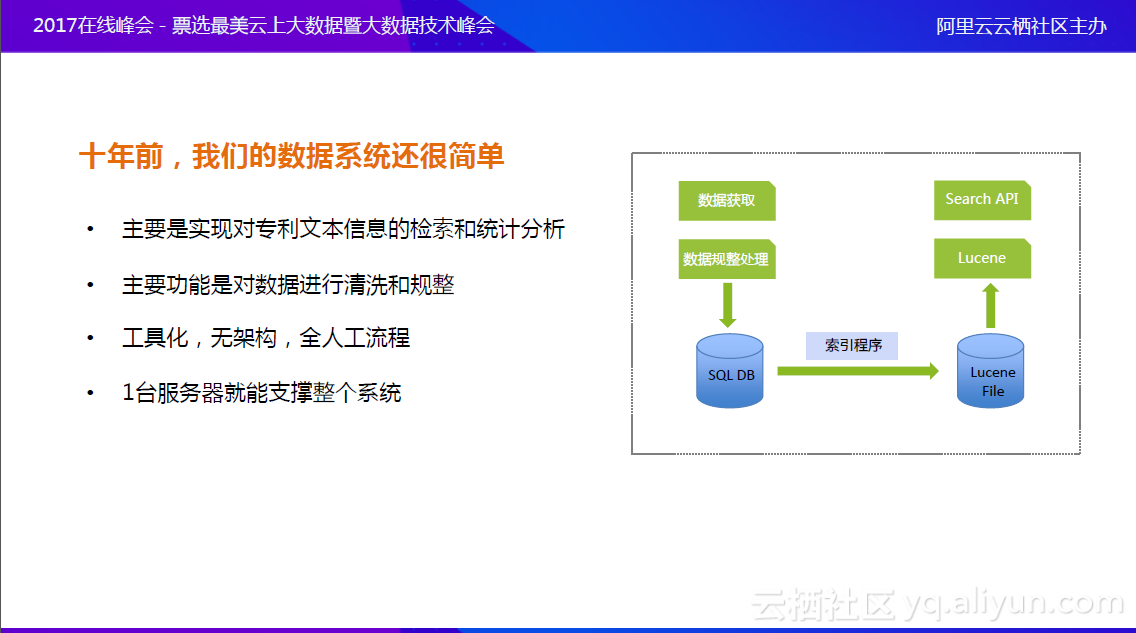
10年前的数据系统,非常简单。萌芽时期整体目标是拿下文本信息,做规整处理,以Lucene为核心,提供相应的Search API,完成相应程序。这是非常简单的提供文本检索的应用,1台服务器就能支撑整个系统。今天,专利大数据的业务已经非常复杂,数据业务场景从个位数增长到十位数,可用数据维度从30多项增加到200多项。佰腾不仅仅提供给用户文本检索功能,还有图像检索、特征检索、关联检索,将它们串起来,产生相应的报告;数据应用的深度也已经加大,数据维度的增加使数据处理量翻了数十倍,数据处理的能力已不再满足周期性的数据更新。一开始能做到每个维度都更新,后来随着数据维度的增加,处理不过来,有一些数据维度则会把更新的周期拉长;除了会遇到数据处理和数据应用瓶颈,还要提防各种“数据流氓”。
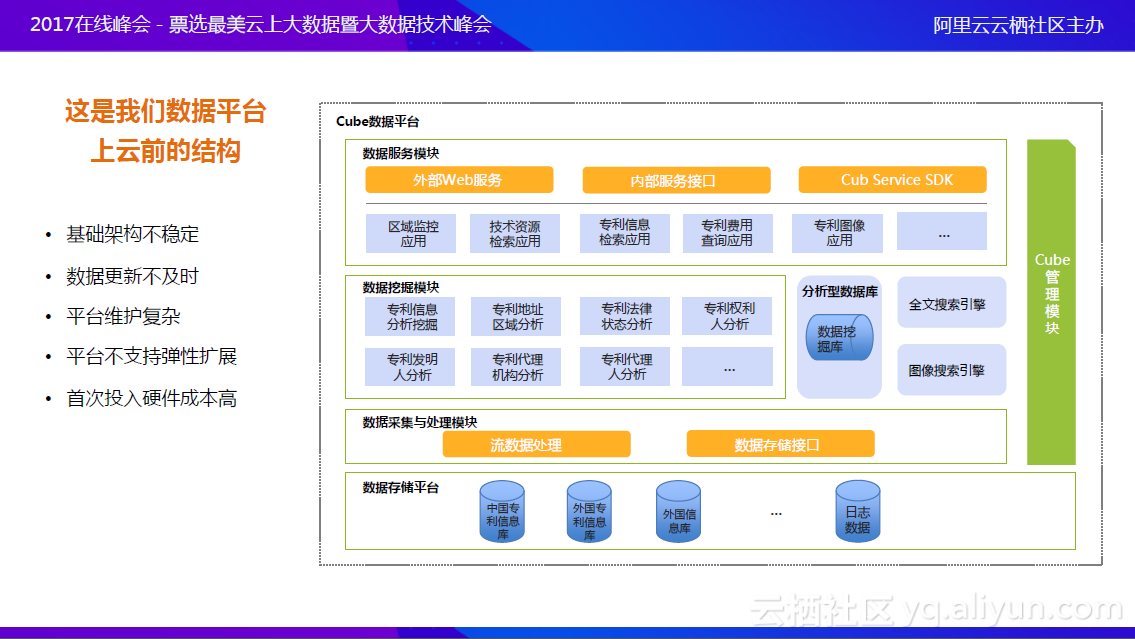
上图所示为数据平台上云前的结构。最上面是业务场景的实现,现在有20多个业务场景,且还在不断增加;中间的数据挖掘模块,是对200多个数据维度点进行挖掘的组件,都要进行大量的维护;最下面是数据库系统。整个这样的平台,投入的费用非常高,自建过百万,每年的维护也差不多十几万,非常大。
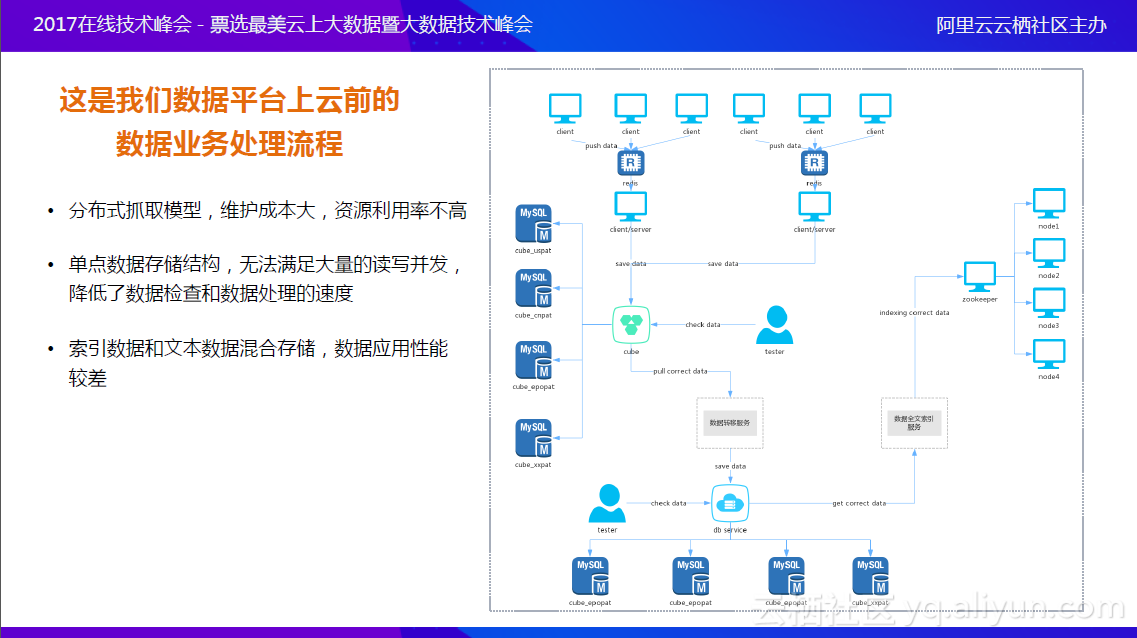
上图是数据平台上云前的业务处理流程,图的最上方是数据获取,获取后左边为原始数据的SQL集群,把原始的专利信息保存下来,检查之后通过下面的数据转移服务,将200多个数据维度点挖掘出来,又通过数据全文的索引服务放到全文索引的数据库。该流程最大的问题是两边的数据库性能瓶颈非常大;另外,索引之中存储了展示的文本信息,所以最右边的Lucene的集群上,数据应用的性能也比较差。
上云要解决的关键问题
上云问题的核心主要是两个方面,一是大数据的处理能力。这里又包括两个方面,(1)上百项数据维度如何高效存储和高效处理?如果这个问题得不到解决,那就没法加快专利信息应用的步伐,没办法满足客户更多的需求;(2)现在的数据维度比较多,处理环节非常多,那么如何实现数据处理流程的自动化编排?二是数据平台的可扩展问题,刚刚架构图中的几十个组件都要维护,每有一个客户需求都需要做组件,那么如何快速支撑各种需求的应用?
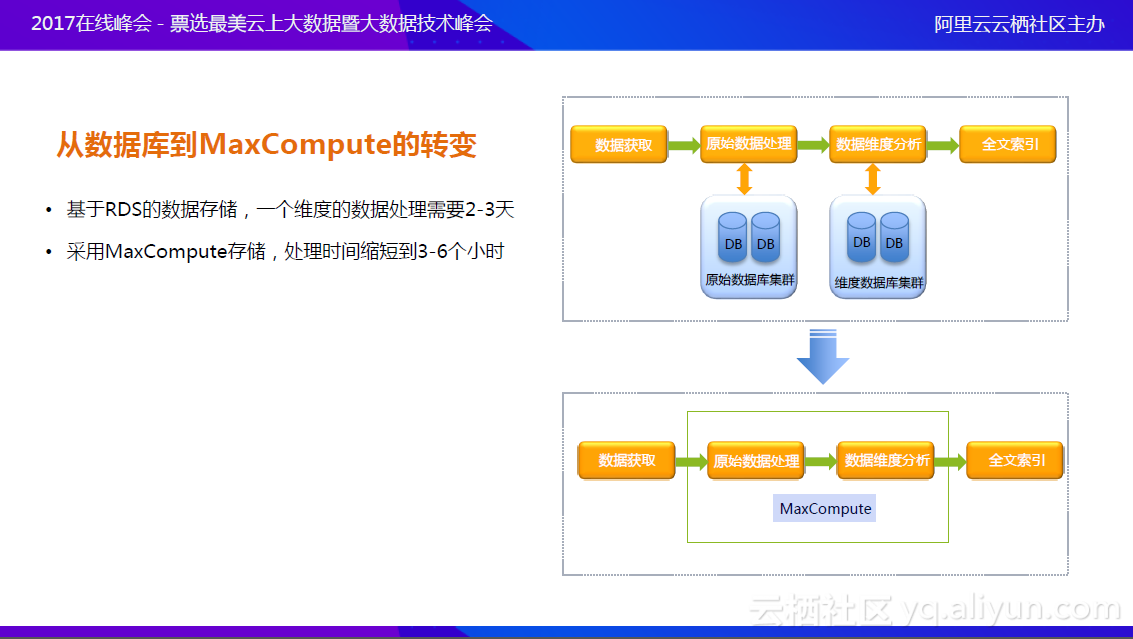
对应的解决方案一方面是使用MaxCompute平台代替数据库。图中的上方是以前的情况,原始数据处理和数据维度分析都使用了数据库集群,现在将这两部分放入了MaxCompute,这样可以大幅提升整个数据存储和处理的效率。数据的测算之前基于RDS的数据存储,一个维度的数据处理需要2-3天,现在处理时间缩短到3-6个小时,整个性能提升非常之大;而且,在大量数据处理时,很多时候是处理到80%的时候才会发现数据处理有问题,若处理时间过长,当发现问题时会一切重新开始,浪费的时间非常长。所以在这个场景下,MaxCompute的性能非常可靠。
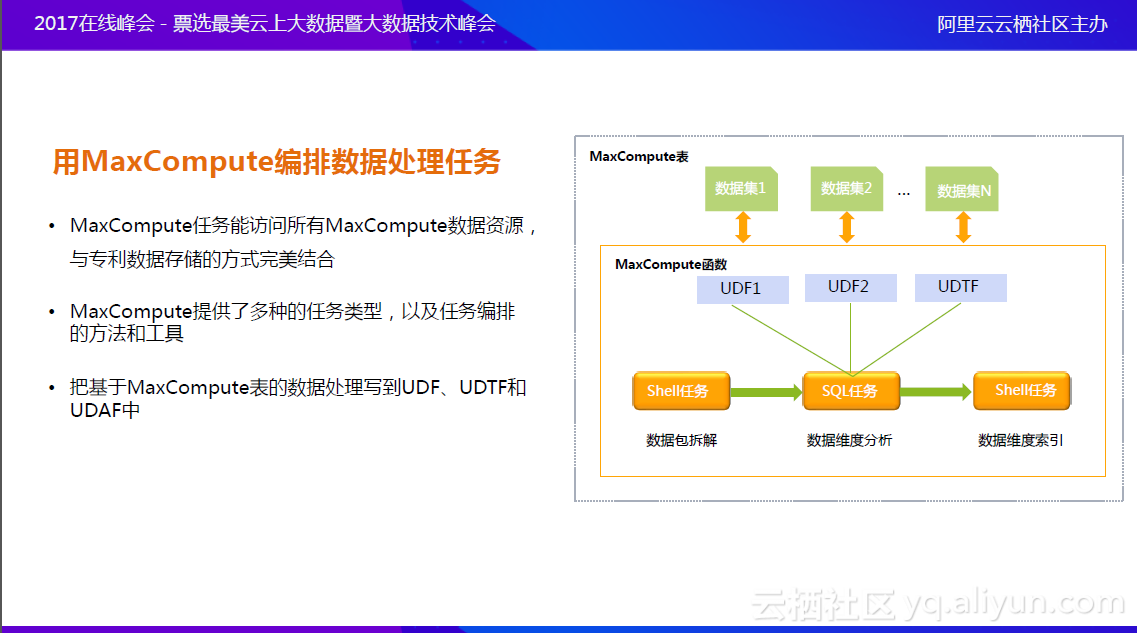
另一个方面,通过使用MaxCompute的任务平台,来编排处理任务。数据都存在MaxCompute表里,因此可以定义MaxCompute函数,访问表里的内容,并进行相应处理。Shell任务对原始数据进行数据包拆解,拆包后把数据放到MaxCompute,然后通过SQL任务对数据维度进行拆解和分析,这时会用到定义的MaxCompute函数,最后还可以调用一个Shell任务,对数据维度索引,供上层应用使用。
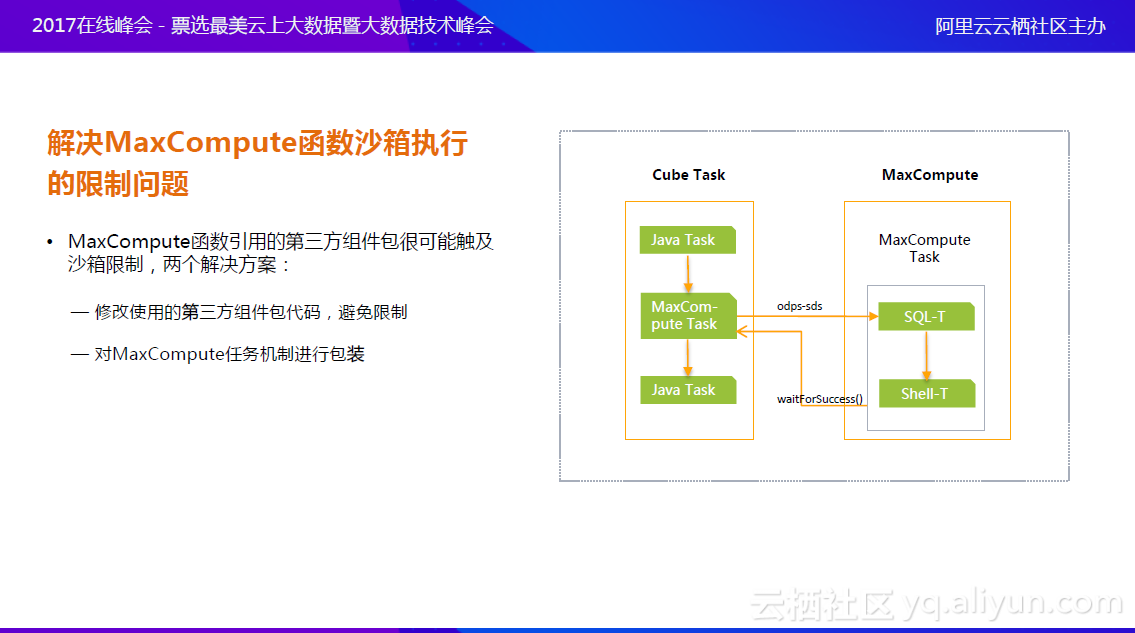
使用MaxCompute平台也会遇到一些问题。因为用户自定义函数在沙箱里运行,有一些安全限制,函数若由自己编写,需要尽量避免这些问题。但难免会引用第三方组件包,就可能会触及沙箱限制。首先可以修改使用的第三方组件包代码,避免限制,但这种解决方案比较有侵入性,所以正在研究另外的方案,即对MaxCompute任务机制进行包装,把会触及到沙箱的代码放到Java的任务里运行,然后通过建立MaxCompute任务,使用MaxCompute提供的SDK,启动MaxCompute的任务实例,等待实例结束后再运行后面的任务。这是正在尝试的新的方案,希望大家一起探讨。
如何满足不断增长和变化的数据应用需求
上述为数据处理能力方面的实践,需要满足不断增长和变化的数据应用需求,主要从三个方面入手:1)平台架构分层化设计;2)数据维度规范化处理,在大数据平台,数据维度是所有问题的核心,也是解决问题的关键;3)数据维度规范化应用。
平台架构分层化设计

如图所示:最下面是数据获取层,负责从数据源拉取数据,检验数据的完整性。比如现在有1亿3千多万条专利数据,每周的更新量很大,要保证每周的数据都要拉取正确。然后需要第二层数据处理层,对原始数据进行数据维度的挖掘。现在200的数据维度,都通过这一层处理,将处理结果放到数据维度数据库,后续再对数据库进行应用上的操作,于是就到了数据应用层,对数据维度进行各类索引以便应用,包括文本索引、图像索引,还有关联索引,用于检索专利间的关系。再往上是数据服务层,负责对外提供统一的数据服务接口,保障服务质量。前面讲到本身要应对数据流氓,对恶意访问的识别和屏蔽也在这一层完成。最后有一个贯穿上下的数据管控层,负责对整个数据平台进行运行监控。这个分层设计主要按照专利大数据的处理流程和职责明确做了设计,核心是数据维度数据库。
数据维度规范化处理
数据维度是专利大数据平台从数据处理挖掘到数据分析应用的分水岭和唯一纽带,也是专利数据中可独立应用的价值单元。我们对于数据维度做了大量的规范性要求,主要是3个方面的规范。1)为每个数据维度明确其应用目标。2)明确数据维度的数据样式规范。比如手机号都是11位,都由数字组成,这就是数据样式规范的一种表现形式。当然在实际的规范定义中会更加复杂。数据样式规范又进一步引申出数据维度的处理规范、应用规范、检测规范。3)数据维度的质量标准。不可能要求每一个维度都百分百达到数据样式规范,比如有些数据达标率达到95%就可以,能满足应用需求即可。
数据维度规范化应用
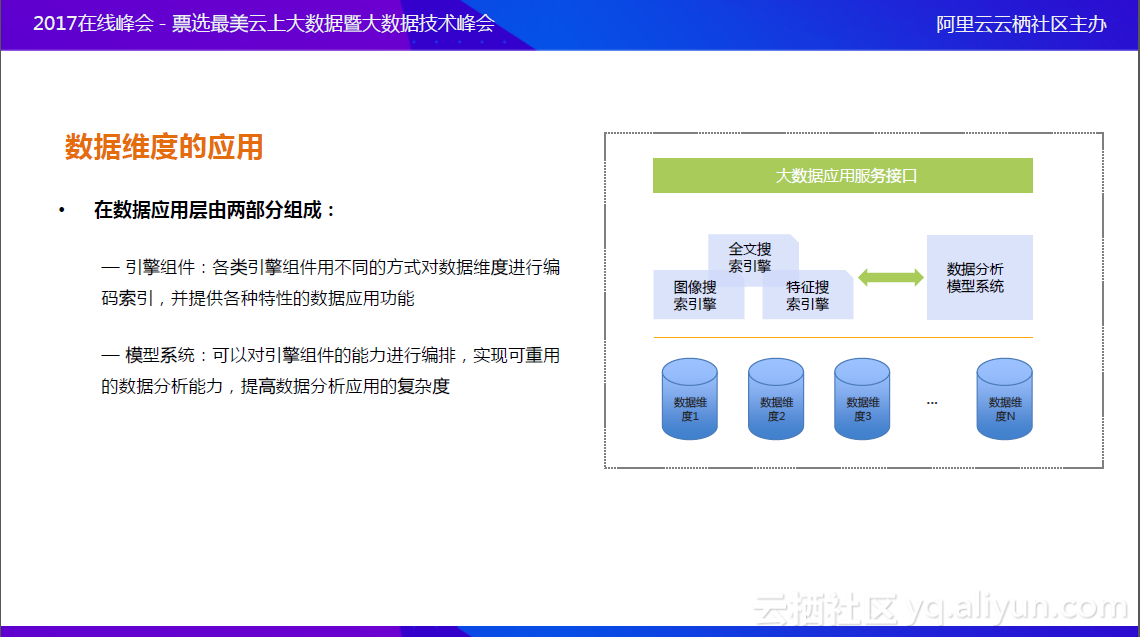
在数据维度规范化的基础之上,就需要对数据维度规范化应用,主要是两方面,一是引擎组件:即各类引擎组件用不同的方式对数据维度进行编码索引,并提供各种特性的数据应用功能,使之开放出来。比如全文搜索引擎可以实现很多数据维度的文本查询、检索,图像搜索引擎可以对图像检索,还有特征搜索引擎等,从而通过上层服务应用的接口,提供给应用系统使用。佰腾内部还在做一个数据分析的模型系统,每个专利信息应用的需求都有其固定的分析模式,延伸开来即为各类数据维度以及对这种数据维度应用的方式进行的编排,有点类似于MaxCompute的任务平台,又不完全一样。该模型可以将专利信息应用的需求做成一个模板,该模板可以复用,从而大大扩展需求深度。数据维度是标准的,应用方式是标准的,能够把能力、数据组装起来,可以对引擎组件的能力进行编排,实现可重用的数据分析能力,提高数据分析应用的复杂度。
基于阿里云的大数据平台技术架构图
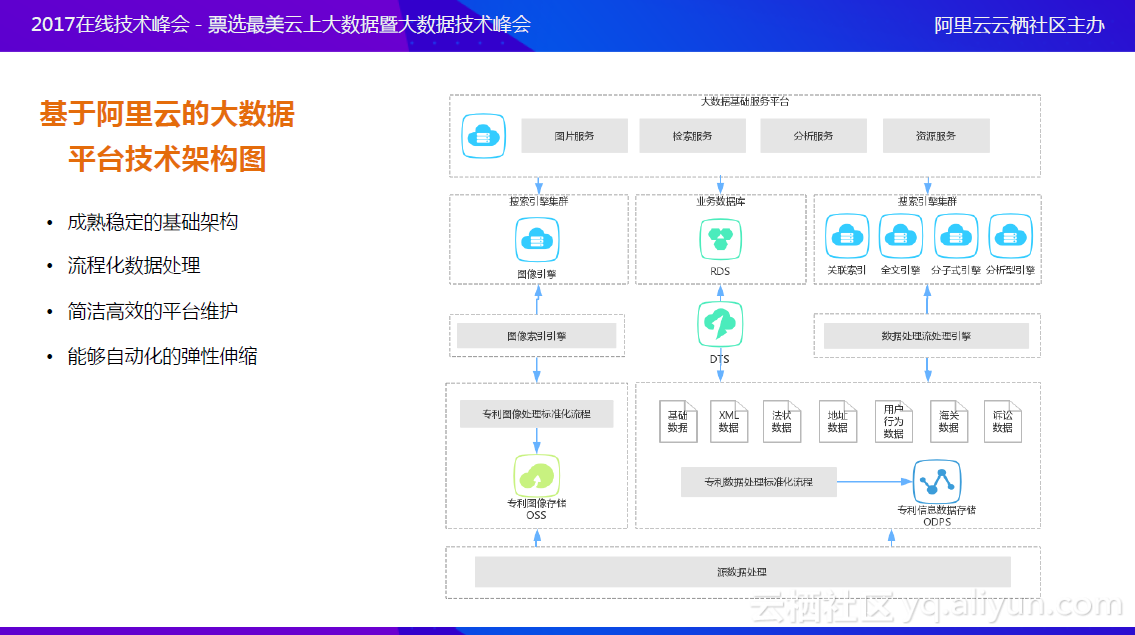
上图是基于阿里云的大数据平台技术架构图,这与上述的平台分层结构设计一致,区别是最左边的图像引擎,和文本处理有些不同,但处理方式差不多。中间有RDS,将用于展示的数据单独拿出来,和索引分开,可以提高大数据应用的效率。
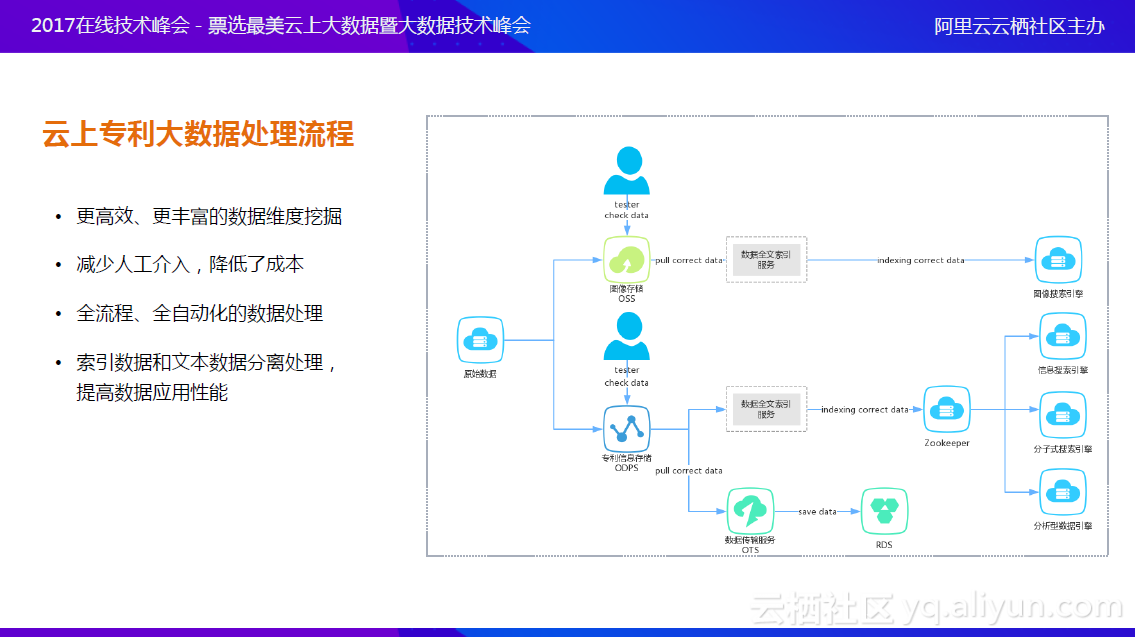
上图是上云之后的大数据处理流程,比之前的流程简单很多。现在图上的流程都实现了自动化编排,一键式处理就可以完全编排,非常高效。
上云之后
现在已经完成了专利大数据平台上云的第一步,接下来,希望进一步提升平台在应对高并发访问和大规模分析运算时的伸缩能力。因为现在用户的访问量非常大,给用户的限制非常大,所以可能会导致性能上的瓶颈,以后会在云上调试。另外,引入更多数加平台的能力,加强数据维度的挖掘和应用能力,主要是机器学习和推荐引擎。
佰腾专利大数据的应用产品
佰腾开发了最新一代的全球专利搜索引擎——专利探索者,专利探索者是以专利信息为核心,通过对海量信息的深度挖掘,借助互联网平台向全球用户提供以专利信息为主的信息检索、信息挖掘、企业级信息应用以及数据信息服务等服务内容的互联网专利信息应用平台。

该平台有四大亮点。1)能对全球专利的印证信息进行关联匹配,找出引用和被引用的关系,便于企业探寻技术发展的轨迹。2)专利价值度是通过对十几个数据维度运算之后得到的价值,保持每周更新,把法律、经济、技术等等方面的信息加入进来,专利价值度的运算可能会由周更变成日更。配以科学的评价标准,最终提供给用户价值度的参考。3)从专利全文中提取图片信息以及对应图片的说明和标注,进一步可视化专利技术点,便于技术研究人员快速理解和研究。4)分析报告建立在大数据运算的基础之上得出,有相应的图表与数据,最终生成一个图文结合的报告。
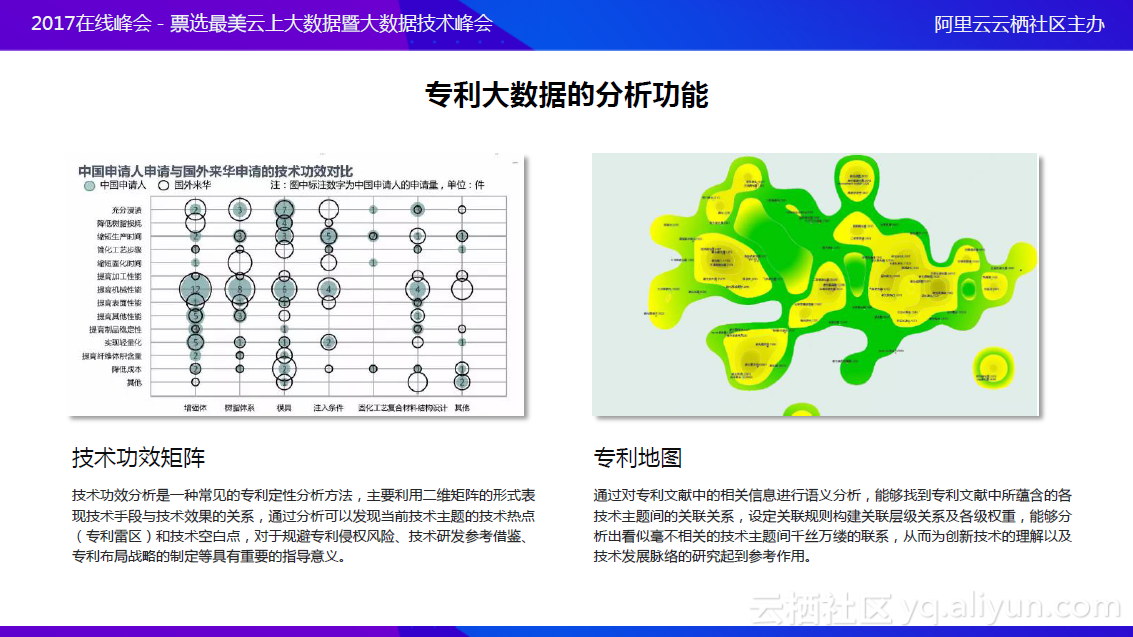
该平台还具有利大数据的分析功能,即大数据时期提供给用户的技术功效矩阵和专利地图,能让企业很方便地发现技术热点和技术空白点,提高企业研发效率;该平台配合专利大数据上云,将在3月21日面向全网公测,欢迎大家提出宝贵意见。
远景

我们团队的远景是做世界级的专利大数据应用平台,来为企业提供创新引擎、知识社交和智慧创新。






