
玩大数据的第一件事情是将数据上传到MaxCompute,那么数据是通过哪些途径进入MaxCompute中的呢?
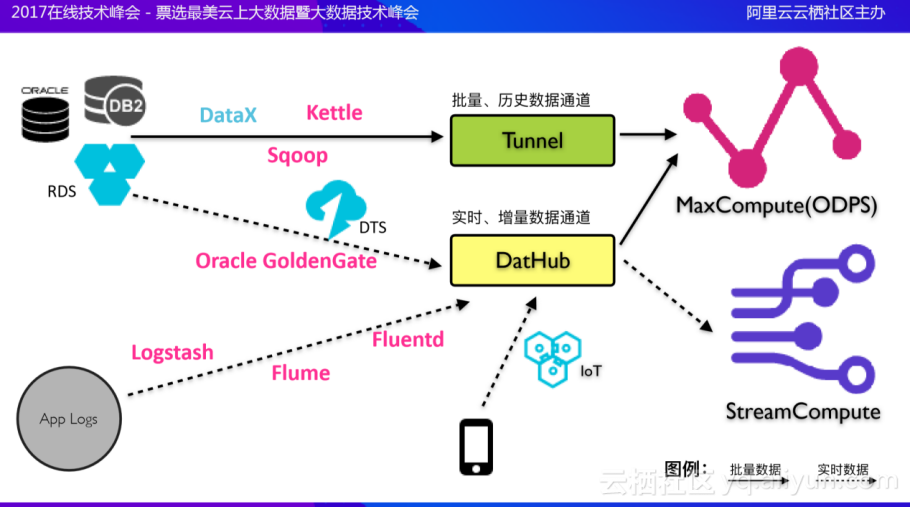
如上图所示,MaxCompute/StreamCompute是提供给用户用来计算大数据的平台,一般来说,它们本身不直接产生实际的业务数据,业务数据是来自于数据库RDS、APP Logs以及IOT等终端设备,两者之间需要桥梁进行连接。
从上图中间可以看到:数据可以通过Tunnel组件进入MaxCompute,Tunnel是一个非常注意吞吐量同时又尽可能追求数据严格一致的输入输出接口;在这条通道上再往前延伸,还有开源软件Sqoop、Kettle以及阿里巴巴自研的开源软件DataX。事实上,在公司内部所有数据的传输、导入到MaxCompute或者说最后计算完的结果再回流到数据库中,这种对前台数据库冲击不大的情况都在使用DataX。为了实时传输数据,满足流计算的诉求,阿里云提供了DatHub组件,它是一个偏重于实时的增量数据通道,在此基础上,对于ECS上的文本日志支持了业界著名的Logstash、Flume、Fluentd三个开源软件。
如何将数据库中的数据拖进MaxCompute中呢?首先能想到的方法是在数据库中执行select语句,将结果集通过Tunnel写入MaxCompute,这是一个容易上手又方便容错的方式。但这种方式对于数据量较大并且需要长期运行的情况不一定非常合适。一方面在阿里的实践过程中发现执行Select语句会对数据库产生查询压力,当数据量非常庞大时,可能会导致前台业务因为数据库增大而产生响应能力上的降低;其次执行SQL语句会碰到各种各样的情况,例如想用时间过滤前一天的增量,但是在时间字段上因为历史原因没有索引,这在专有云案例中经常发生。对于这种情况,我们尝试解析MySQL的binlog,将其binlog以一种流式的方式源源不断地、实时地传递到DatHub上,然后该数据再通过DatHub再写入MaxCompute,在MaxCompute上再进行数据的合并等操作,还原出前一天的增量数据。
目前,在公共云,DatHub和官方的数据传输产品DTS已经打通,能够无缝完成RDS上的数据库实时变更增量并写入DatHub中,进一步Push到MaxCompute中;另一方面,所有进入DatHub的实时数据都可以被流计算无缝使用,做一些时效性更好的计算作业。
数据上云核心问题

数据上云的核心问题包括四点:
(1)数据要能上传,它主要面临两个痛点包:一是前台存储多样化,包括RDBMS、NoSQL、Logs等,每多一种类型,需要对应地识别其协议,解析Schema,甚至是无Schema的类型还需要按照业务逻辑转变成二维表的格式;二是传输需求多变,例如在传输的过程中需要将字符串转变成ID,将图片变成URL地址等,很难将其抽象成一个标准的模型。
阿里云为应对该问题,提供了Tunnel和DataHub的官方API和SDK作为兜底,保障了在阿里云生态工具跟不上的情况下,开发者依旧有方法将数据上传到云端。
(2)数据的高效传输,数据传输中最典型的问题就是带宽,尤其是长途传输,长途带宽上的稍微波动都对传输效率起到很大的影响;第二个问题是数据库Dump开销大,影响到核心业务的运转。
传输问题对应的解决方案一是尽量规避长途传输、长途带宽对效率的影响,在Tunnel通道中,支持压缩协议,可以在客户端进行压缩,然后再大包提交,进而提升吞吐量;第二点采用DTS这类基于增量日志的实时上传方式,拉长传输时间,并且支持断点续传,降低某特定时刻对带宽的需求。
(3)数据的正确性,首先MaxCompute是一个强Schema的数据库,从Oralce到MaxCompute传导数据时,在字段类型的映射上或浮点数的操作上一定会存在精度误差,那么精度误差如何处理?第二点是正确性无法避开的Timeout重传导致的数据重复。
Tunnel提供两阶段提交的功能,先Write后Commit,提供了数据严格一致的可能性;相反地,DataHub流式传输无法实现两阶段提交,这是由于要考虑效率和吞吐量导致。
(4)安全是使用云计算必须面临的问题,数据存储是否可靠以及会不会第三方被嗅探。
MaxCompute采用pangu的三副本存储,本身提供了非常高的可靠性。另一方面,MaxCompute默认不同用户之间的数据完全隔离, 并且在传输过程中全部采用HTTPS协议,使得数据被第三方嗅探到的可能降到最低。
下面来具体看一下Tunnel和DataHub。
批量、历史数据通道Tunnel

Tunnel是针对历史数据的批量数据通道,它的典型特征是支持大包传输,Write&Commit两阶段提交,最大可能性保证数据一致。用户可以使用ODPSCMD命令对数据进行上传、下载等操作。
Datax是阿里开源的一款工具,可以适配常见的数据源,包括关系数据库、文本文件等,这是一款单机的软件,适用于中小数据量的传输。使用Datax传输数据到ODPS时,在ECS机器或一台物理机器上部署好DataX,此机器要能够同时连通数据源与MaxCompute(原ODPS)服务。Sqoop可以并行起多个任务导出数据,相比Datax可以取得更好的性能。
实时、增量数据通道DataHub
DataHub是实时、增量数据通道,目的是为支持流计算和实时数据。在编程友好性上,DataHub要优于Tunnel,解决了Tunnel的小包效率问题,并且能够容忍少量的数据重复。

DataHub摒弃了两阶段提交的方式,使用时不停地写入数据即可,技术特征是面向高吞吐,因此在DataHub上并没有提供严格一致的语义支持;在阿里集团内部,DataHub每天有数百TB数据压缩后写入,PB级别的数据消费。消费的数据之所以是写入数据的数倍是因为一份数据会被多方使用,例如一份数据进入MaxCompute进行离线加工,另一份甚至多份用于实时处理,给用户提供更实时的数据。
在DataHub通道上,要尽可能保障数据低延迟,目前,理论上数据库中的用户订单可以做到毫秒级流入流计算或MaxCompute中;在阿里的实际生产经验中,为了平衡延时和吞吐,在绝大数情况下,前台订单流入后端计算平台的总时间在1s-2s左右,但这种时效性已经能够满足绝大多数业务需求。
DataHub和流计算产品紧密结合,可以在流计算中非常方便的重复使用多份数据;DataHub是基于Topic/Shard(s)模型,每个主题(Topic)的数据流吞吐能力可以动态扩展和减少,最高可达到每主题256000 Records/s的吞吐量。
源头数据库到DataHub数据库之间可以通过DTS、Oracle GoldenGate连接;App Logs到DataHub之间可以通过Logstash、Fluentd等开源软件连接。
MaxCompute生态思路
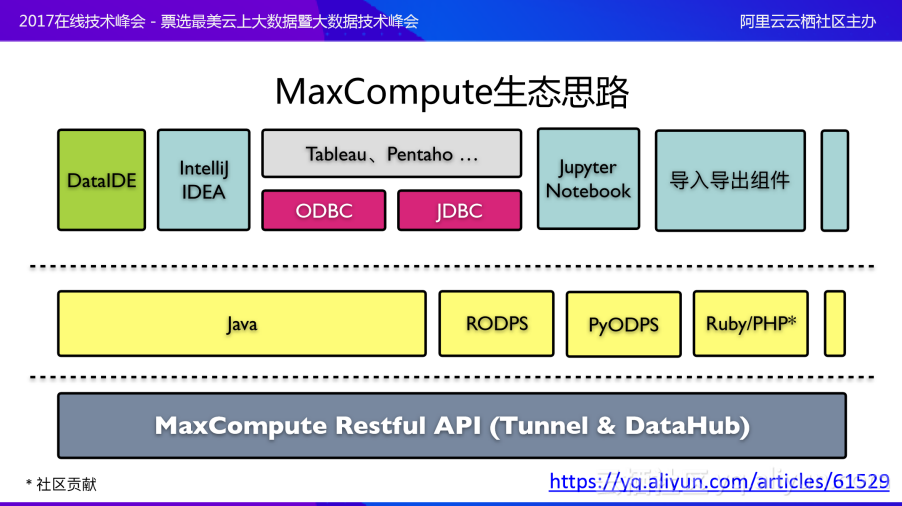
上述提到的数据上传是整个MacCompute生态的一部分,MaxCompute整体思路如上图所示:最底层是MaxCompute Restful API(Tunnel&DataHub);在中间层(黄色部分)提供了Java、RODPS、PyODPS、Ruby/PHP(社区贡献)等语言的SDK,这两层是兜底方案,当上层提供的组件无法满足需求时,开发者依旧有方式将数据传到计算平台上;最上层是生态的思路,包括官方大数据DataIDE、IntelliJ IDEA Plugin(MaxCompute Studio)、Jupyter Notebook、导入导出模块等。
RODPS

RODPS提供了一种桥接的方式,使得可以在R语言环境中无缝的使用MaxCompute(原ODPS)里面的数据、计算资源,类似于开源社区的RHive和Rhadoop的功能;R语言开发者可以在R语言中直接执行MaxCompute SQL,并将结果集转换为Rdata.frame,便于进一步研究。RODPS很适合在MaxCompute中预先完成计算,缩小结果集再进行单机分析的场景。
未来RODPS将致力于将本地算法和数据处理运作在分布式系统上面,致力于让用户无缝迁移R社区的开源包,提供类似于sparkR那样的强大的能力。
PyODPS

PyODPS 是ODPS的Python版本的SDK, 它提供了对MaxCompute对象的基本操作,在Python中运行MaxCompute SQL语句的需求促进了PyODPS的出现;与RODPS类似,在Python中也可以做MaxCompute DataFrame,甚至MaxCompute结果的DataFrame还可以和Pandas DataFrame进行Join操作;除此之外,通过PyODPS还为开发者提供了基于第三方软件(如Jupyter Notebook)连接到MaxCompute中进行交互式数据分析的能力。
