标签
PostgreSQL , 10.0 , 间接索引 , 第二索引
背景
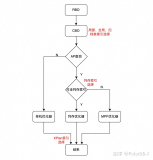
我们知道,PostgreSQL的MVCC是多版本来实现的,当更新数据时,产生新的版本。
那么如果新版本不在同一个数据块的时候,索引也要随之变化,当新版本在同一个堆表的块里面时,则发生HOT UPDATE,不需要变更没有发生值改变的索引。
但是HOT总不能覆盖100%的更新,所以还是有索引更新的可能存在。
为了解决这个问题,PostgreSQL 10.0引入了第二索引(间接索引)的概念,即在PK或者UK之上,构建其他索引。
那么只要UK或者PK的值不变,其他索引都不需要变更。
间接索引的好处,不言而喻,可以减少表的DML带来的索引变更。
间接索引的缺陷,通过间接索引查询堆表数据时,需要扫描两个索引(间接索引,以及第一索引),还需要扫描堆表定位数据。
详情
I propose we introduce the concept of "indirect indexes". I have a toy
implementation and before I go further with it, I'd like this assembly's
input on the general direction.
Indirect indexes are similar to regular indexes, except that instead of
carrying a heap TID as payload, they carry the value of the table's
primary key. Because this is laid out on top of existing index support
code, values indexed by the PK can only be six bytes long (the length of
ItemPointerData); in other words, 281,474,976,710,656 rows are
supported, which should be sufficient for most use cases.[1]
A new flag is added to the index AM routine, indicating whether it can
support indirect indexes. Initially, only the b-tree AM would support
indirect indexes, but I plan to develop support for GIN indirect soon
afterwards, which seems most valuable.
To create an indirect index, the command
CREATE INDIRECT INDEX
is used. Currently this always uses the defined primary key index[2].
Implementation-wise, to find a value using an indirect index that index
is scanned first; this produces a PK value, which can be used to scan
the primary key index, the result of which is returned.
There are two big advantages to indirect indexes, both of which are
related to UPDATE's "write amplification":
1. UPDATE is faster. Indirect indexes on column that are not modified
by the update do not need to be updated.
2. HOT can be used more frequently. Columns indexed only by indirect
indexes do not need to be considered for whether an update needs to
be non-HOT, so this further limits "write amplification".
The biggest downside is that in order to find out a heap tuple using the
index we need to descend two indexes (the indirect and the PK) instead
of one, so it's slower. For many use cases the tradeoff is justified.
I measured the benefits with the current prototype implementation. In
two separate schemas, I created a pgbench_accounts table, with 12
"filler" columns, and indexed them all; one schema used regular indexes,
the other used indirect indexes. Filled them both to the equivalent of
scale 50, which results in a table of some 2171 MB; the 12 indexes are
282 MB each, and the PK index is 107 MB). I then ran a pgbench with a
custom script that update a random one of those columns and leave the
others alone on both schemas (not simultaneously). I ran 100k updates
for each case, 5 times:
method │ TPS: min / avg (stddev) / max │ Duration: min / avg / max │ avg_wal
──────────┼───────────────────────────────────┼─────────────────────────────────────────┼─────────
direct │ 601.2 / 1029.9 ( 371.9) / 1520.9 │ 00:01:05.76 / 00:01:48.58 / 00:02:46.39 │ 4841 MB
indirect │ 2165.1 / 3081.6 ( 574.8) / 3616.4 │ 00:00:27.66 / 00:00:33.56 / 00:00:46.2 │ 1194 MB
(2 rows)
This is a pretty small test (not long enough for autovacuum to trigger
decently) but I think this should be compelling enough to present the
case.
Please discuss.
Implementation notes:
Executor-wise, we could have a distinct IndirectIndexScan node, or we
could just hide the second index scan inside a regular IndexScan. I
think from a cleanliness POV there is no reason to have a separate node;
efficiency wise I think a separate node leads to less branches in the
code. (In my toy patch I actually have the second indexscan hidden
inside a separate "ibtree" AM; not what I really propose for commit.)
Additionally, executor will have to keep track of the values in the PK
index so that they can be passed down on insertion to each indirect
index.
Planner-wise, I don't think we need to introduce a distinct indirect
index Path. We can just let the cost estimator attach the true cost of
the two scans to a regular index scan path, and the correct executor
node is produced later if that index is chosen.
In relcache we'll need an additional bitmapset of columns indexed by
indirect indexes. This is used so that heap_update can return an output
bitmapset of such columns that were not modified (this is computed by
HeapSatisfiesHOTandKeyUpdate). The executor uses this to know when to
skip updating each indirect index.
Vacuuming presents an additional challenge: in order to remove index
items from an indirect index, it's critical to scan the PK index first
and collect the PK values that are being removed. Then scan the
indirect index and remove any items that match the PK items removed.
This is a bit problematic because of the additional memory needed to
store the array of PK values. I haven't implemented this yet.
Items I haven't thought about yet:
* UNIQUE INDIRECT? I think these should work, but require some
tinkering.
* Deferred unique indexes? See unique_key_recheck.
* CREATE INDEX CONCURRENTLY.
[1] Eventually we can expand this to allow for "normal" datatypes, say
bigint, but that's likely to require a much bigger patch in order to
change IndexTuple to support it. I would defer that project to a later
time.
[2] It is possible to extend the grammar to allow other UNIQUE indexes
to be used, if they are on top of NOT NULL columns. This would allow to
extend existing production databases with a new column. A proposed
syntax is
CREATE INDIRECT INDEX idx ON tab (a, b, c)
REFERENCES some_unique_index
[optional WHERE clause] ;
which Bison accepts. I propose not to implement this yet. However this
is an important item because it allows existing databases to simply add
an UNIQUE NOT NULL column to their existing big tables to take advantage
of the feature, without requiring a lengthy dump/reload of tables that
currently only have larger keys.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
这个patch的讨论,详见邮件组,本文末尾URL。
PostgreSQL社区的作风非常严谨,一个patch可能在邮件组中讨论几个月甚至几年,根据大家的意见反复的修正,patch合并到master已经非常成熟,所以PostgreSQL的稳定性也是远近闻名的。
参考
https://commitfest.postgresql.org/13/874/
《为PostgreSQL讨说法 - 浅析《UBER ENGINEERING SWITCHED FROM POSTGRES TO MYSQL》》