
免费开通大数据服务:https://www.aliyun.com/product/odps
摘要:
目前我国物流业保持较快增长,但还是存在一些问题:物流成本高、效率低,条块分割严重(自营物流、规模小、技术落后、标准不统一)、基础设施相对滞后(物流基础设施之间不衔接、不配套),对订单创建到用户签收整套完整流程缺乏完善的监控和预警手段.
基于建设统一物流平台的基本要求,用户希望打通各大系统,能够跟踪所有订单在物流系统中的流转过程、处理状态等信息,具体如下需求:
1:订单分为5个阶段,订单处理、发运处理、拣货出库、配送和签收
2:每个阶段的状态判定:未处理、一般报警、严重报警、完成
3:超期天数:需要判定基于订单、装运单的超期天数
4:进度:当前阶段的进度百分比
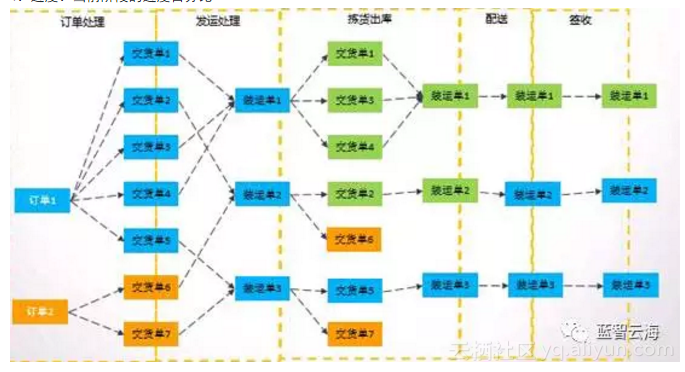
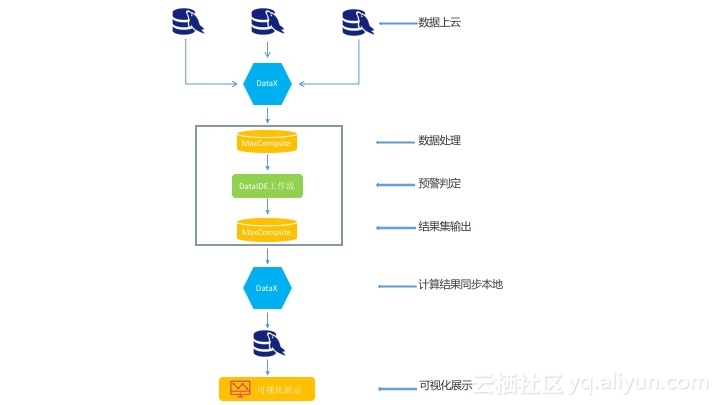
由上图我们能够分析得出此需求可能涉及多个系统的数据整合,其中订单来源于ERP系统,发运处理和拣货出库数据来源SAP系统,而配送签收就需要使用到GPS等外部系统数据。实际场景中订单、交货单、运单分别来自不同的数据库,所以整体工作项包括:
1、首先要进行数据的整合上云
2、利用阿里云大数据计算服务进行数据处理和预警判定产生预警结果
3、将预警结果同步到本地预警数据库中
4、本地搭建订单预警应用使用预警数据库进行可视化展示
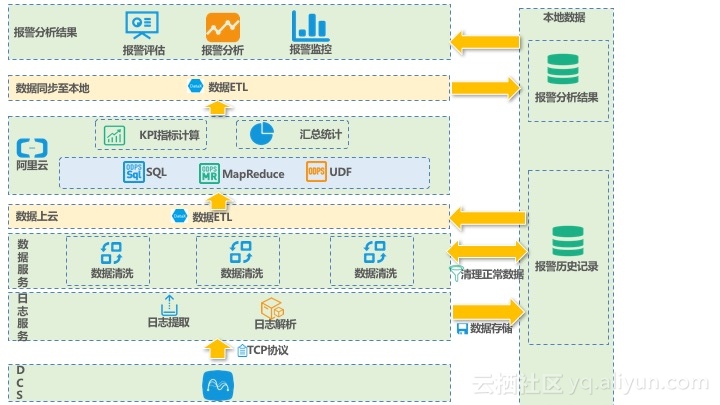
技术架构
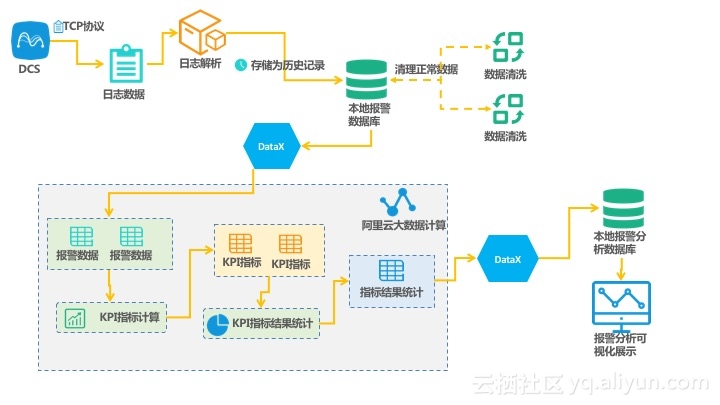
主要处理流程:
开发环境:windows7、Python、Data IDE
工具:DataX、Data IDE、Eclipse
【正文】
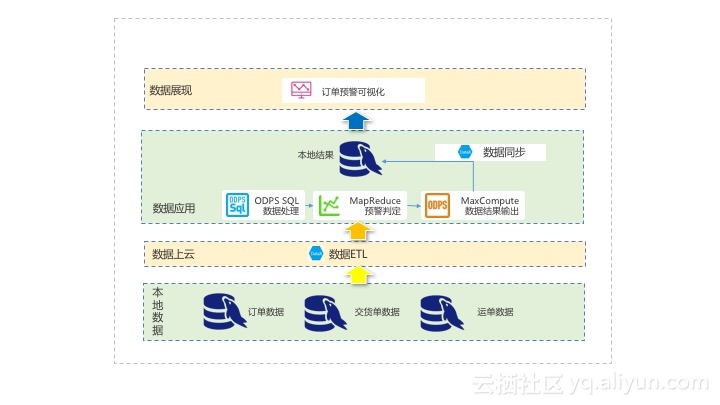
一、数据同步上云
安装Python环境>下载datax客户端>创建项目>创建表>编写json配置文件>同步数据到odps
Python地址:https://www.python.org/downloads/
Datax地址:http://datax-opensource.oss-cn- hangzhou.aliyuncs.com/datax.tar.gz"
1、基于阿里云大数据平台创建数据同步表
1.1.首先您需要阿里云账号并已开通大数据计算服务,如果您已开通大数据计算服务,则直接进入控制台点击“大数据开发套件”进入Data IDE环境。
1.2.点击管理控制台,进入管理控制台页面,点击创建项目,新建MaxCompter项目
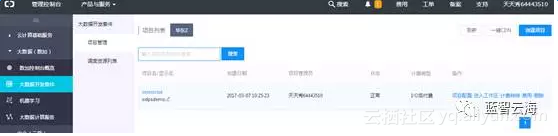
1.3.点击进入工作区,进入到odps工作空间,工具栏点击【新建】,选择新建表
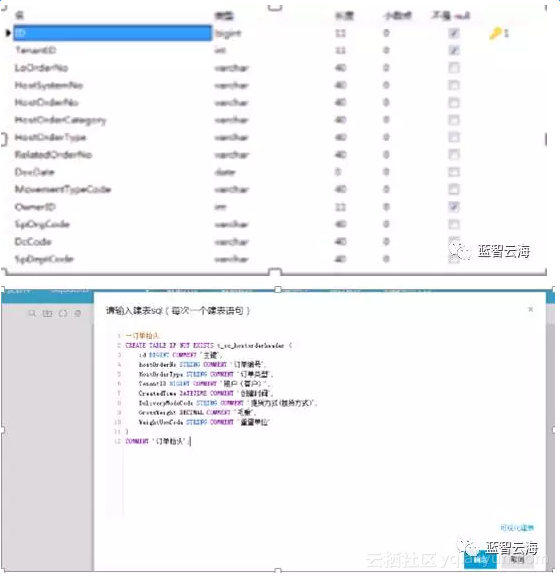
对应本地数据订单抬头表,将需要进行数据处理的字段提出来,新建表sql如下
注:登录阿里云市场点击【我的头像】点击【管理控制台】下的【大数据开发套件】,进入项目管理找到自己新建的项目点击【进入工作区】,在IDE工作环境中标题栏中选择【数据管理】。在左边标题栏下点击【数据表管理】,加载出数据管理页面。找到我【管理的表】,点击查看
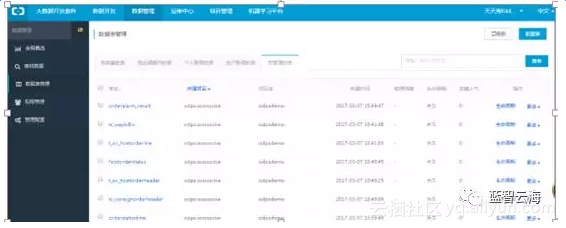
以上就完成了Maxcompute建立项目和建表的工作内容。
2、配置DataX数据同步配置文件
首先需要下载的datax(datax 是不同类型的数据库中间交换数据的工具)
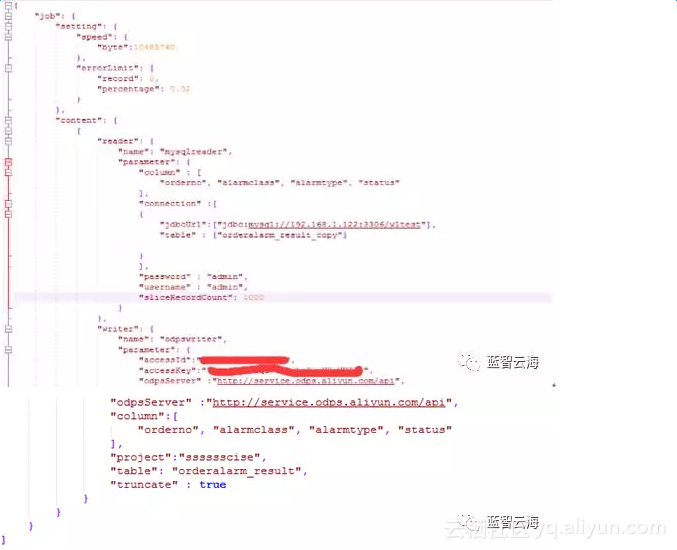
以上配置:MysqlReader通过JDBC连接器连接到远程的Mysql数据库,并根据用户配置的信息生成查询SELECT SQL语句,然后发送到远程Mysql数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。odpsWriter 通过 DataX 框架获取 Reader 生成的协议数据,根据你配置的 writeMode 生成。
打开cmd.exe命令行窗口 输入datax文件地址我的是:D:\programFiles\file2\datax\bin
执行命令 datax.py ..\job\t_oc_hostorderline.json.
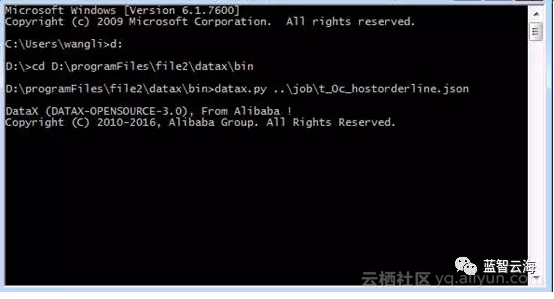
执行成功
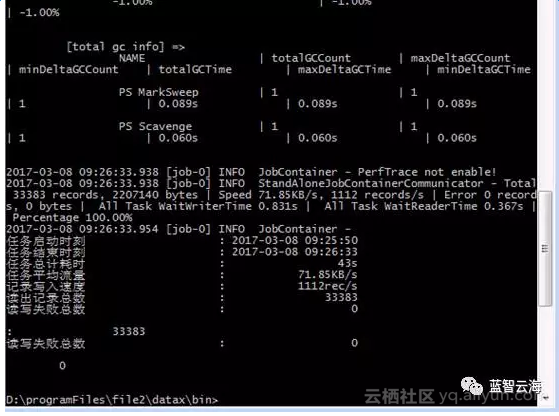
注:datax 在window下乱码异常解决方式:
打开cmd.exe命令行窗口,通过chcp命令改变代码页为65001
chcp 65001
在命令行标题栏上点击右键,选择“属性”->“字体”,将字体修改为True Type字体“Lucida Console”,然后点击确定将属性应用到当前窗口
3、查看云上表数据
登录阿里云市场点击【我的头像】点击【管理控制台】下的【大数据开发套件】,进入项目管理,找到自己新建的项目点击【进入工作区】,在IDE工作环境中标题栏中选择【数据管理】。在左边标题栏下点击【数据表管理】,加载出数据管理页面。找到我【管理的表】,点击查看
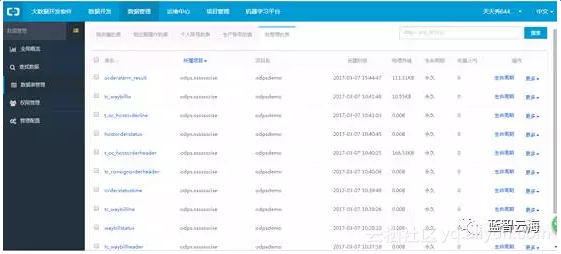
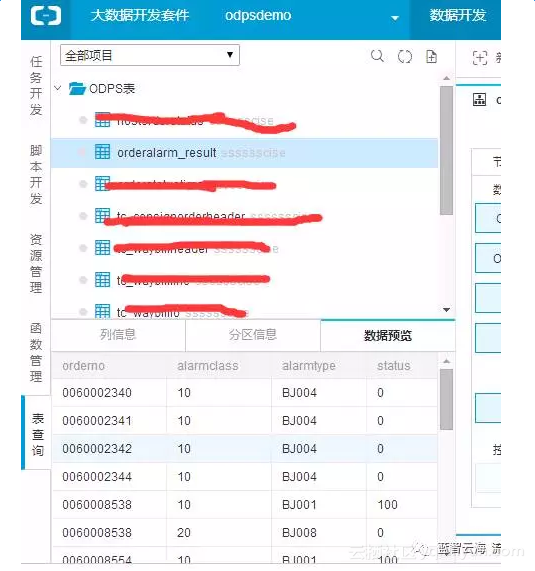
双击【t_oc_hostorderline】进入表的详情页面在表的详情页面点击【数据预览】。下面出现本地数据,说明数据本地同步到odps成功
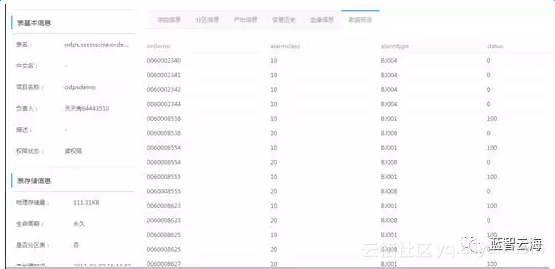
二、数据处理、预警判定、结果集输出
我们使用阿里云Data IDE流程组件中的ODPS_SQL节点来进行数据处理(包括数据集合并、单位统一、数据空值补全等),然后基于阿里云标准开发自定义的MR来进行预警判定,最后将预警结果写入到结果表中,具体操作步骤如下:
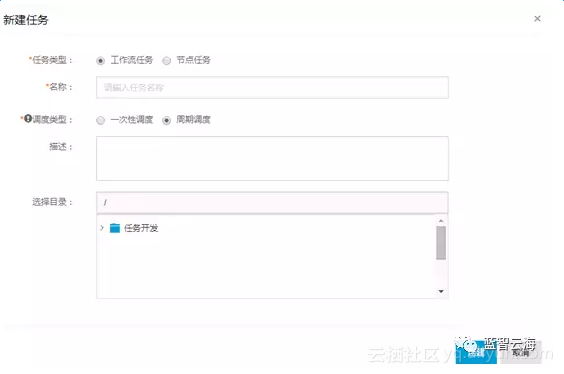
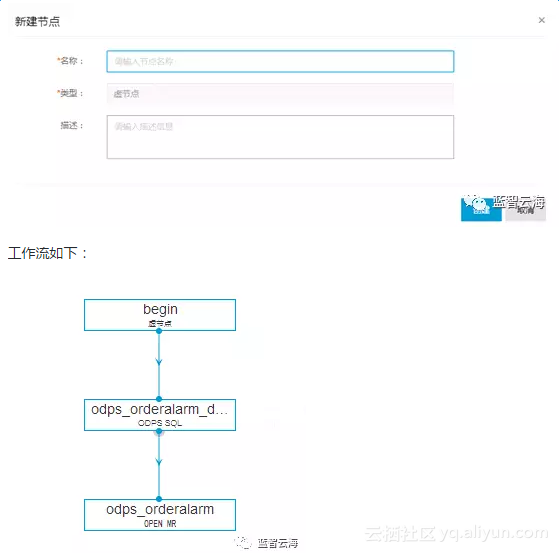
1.建立任务
登录阿里云市场点击【我的头像】点击【管理控制台】下的【大数据开发套件】,进入项目管理找到自己新建的项目点击【进入工作区】,在工具栏点击【新建】,选择新建
选择工作流任务,周期调度
2.获取订单信息,交货单信息,运单信息,根据订单号组装成预警判定所需要的订单预警对象,根据订单号分组组装成完整的预警数据对象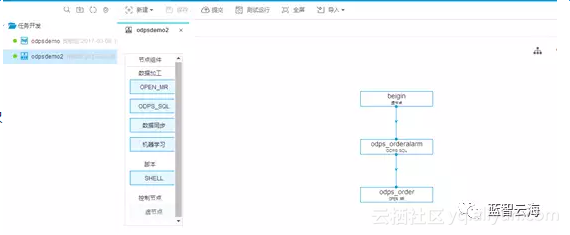
3.选择节点组件的虚节拖拽连接完整的处理流程
ODPS_SQL节点,以SQL语句来进行多表数据的合并、空数据补全、单位统一等处理
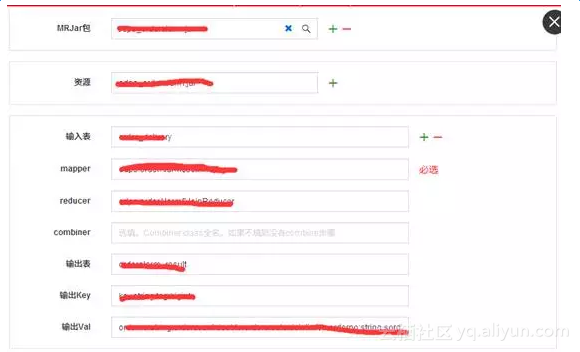
OPEN MR节点,使用JAVA语言开发的自定义预警MapReduce程序(打包为jar上传到平台使用)
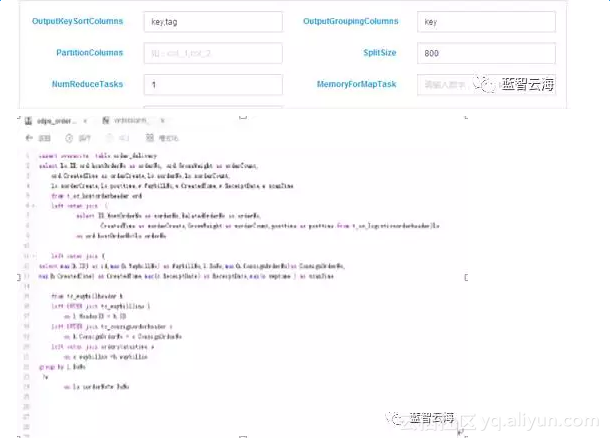
以上流程开发完毕后即可点击"测试"按钮,测试运行整个流程任务,也可设置任务为周期任务设置任务定时启动的时间,这样任务就可以按照设定周期性的定时执行。
以上流程中,在ODPS SQL进行数据处理之后,结果作为MapReduce输入表,以订单号作为key,订单预警对象作为value,分发给不同的Reduce进行规制判定,将满足预警条件的结果写入MaxCompute结果表【orderalarm_result】中
三、计算结果同步到本地
通过以上流程任务的运行,已经产生了我们需要的预警结果数据,但用户不希望将预警结果数据放在云端使用,用户想将结果数据能够放在本地MySQL或其它数据库中,基于本地搭建预警应用使用本地数据库中的数据进行可视化展示。
基于以上用户需求,我们只基于云平台产生了预警结果数据,接下来我们还需要将云端的数据同步到本地。
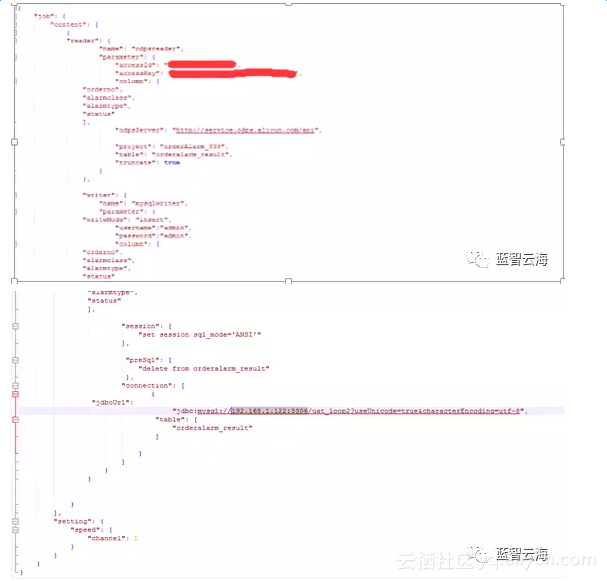
(我们使用DataX工具设置job任务将大数据平台结果表中的数据同步到本地预警平台数据库的预警结果表中)
1、新建配置文件
t_oc_hostorderline2.json,job文件内容如下
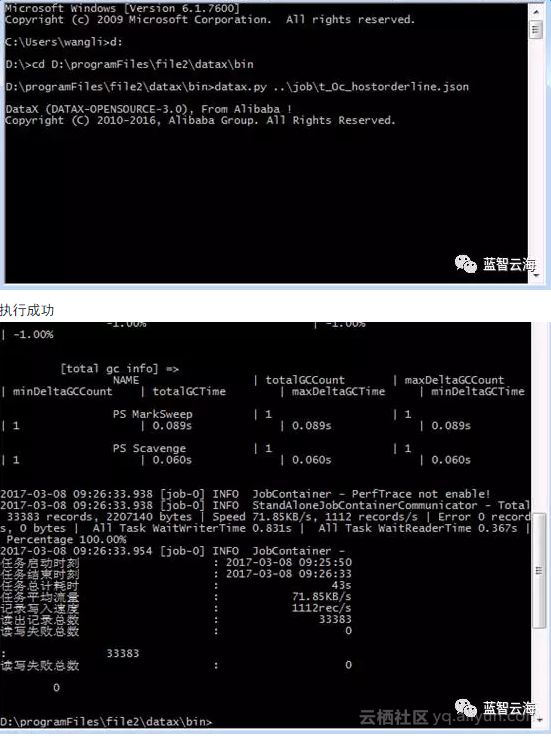
打开cmd.exe命令行窗口 输入datax文件地址我的是:D:\programFiles\file2\datax\bin
执行命令 datax.py ..\job\result.json.
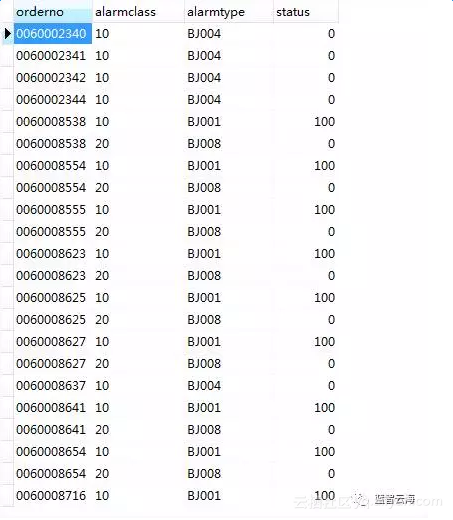
3、查看本地数据库
四、可视化展示
将云上预警结果数据同步到本地数据库以后,用户即可基于本地环境搭建预警应用,使用本地数据库中的数据来进行可视化展示。
1、建立ssm项目添加订单预警
2、展示页面
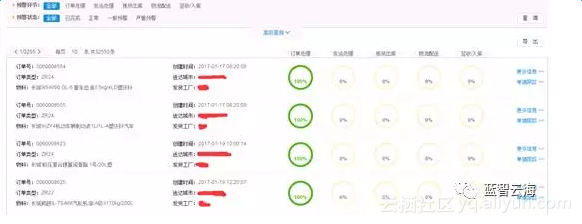
以上基于阿里云MaxCompute平台通过:数据上云、大数据计算、云上数据同步到本地、本地可视化展示 四大步来讲解如何实现物流订单的预警与跟踪。
其主要用到的工具包括:DataX(数据同步/集成工具)、Data IDE(大数据开发套件)、Eclips(Java、MapReduce开发)。
-END-
转自蓝智云海公众号
相关文章



