
作者:如切,悟双,楚哲,晓祥,旭林
引言
天猫精灵(TmallGenie)是阿里巴巴人工智能实验室(Alibaba A.I.Labs)于2017年7月5日发布的AI智能语音终端设备。天猫精灵目前是全球销量第三、中国销量第一的智能音箱品牌。
在天猫精灵业务系统中,大量使用了算法模型。如领域分类模型,意图分类模型,槽填充模型,多轮对话模型等。当前天猫精灵后台有上百个正在使用的算法模型。
在模型服务方面,有两个问题非常重要:
- 首先,为了保证服务能够得到快速响应,模型的 RT 必须尽可能的短。
- 其次,我们希望在硬件资源一定的情况下能够支持更多的 qps 访问,从而降低整体成本。
机器学习PAI是阿里巴巴AI开发平台,为AI开发者提供软硬一体的编程环境和高性能训练与推理引擎框架。
天猫精灵业务 PAI 模型的优化主要通过 AutoAI 接入 PAI Blade 的模型推理优化能力。实践显示,在天猫精灵业务中,结合使用 blade 优化和编译优化,使用 PAI-Blade 优化在最多可节省 86% 的资源,同时将 RT 降低了70%。
关于 PAI-Blade
PAI-Blade 是 阿里巴巴PAI平台针对深度学习模型开发的通用推理优化引擎。目前支持Tensorflow(包括Keras .h5模型),Caffe,及Onnx格式模型。通过这几种主流的模型前端表示,直接或间接涵盖了几乎所有深度学习框架。
Blade推理优化引擎有机融合了包括Blade graph optimizer、TensorRT、PAI-TAO、Blade custom optimizer、Blade int8 (mixed-precision)、Blade Auto-Compression在内的多种优化技术。Blade会首先对模型进行分析,基于对模型的理解对模型的部分或全部应用上述的优化技术,优化过程包括但不限于:
- 通用图优化
- 基于理解的计算图等效变换
- 算子融合
- 对计算图算子丰富的高效实现所进行的组合优化
- JIT编译
- 基于模板及历史数据实现的半自动或自动codegen
- 启发式的Auto-Tuning
- 模型压缩、剪裁
- 模型低精度及混合精度量化
- 模型低精度量化前提下的精度恢复技术
所有的优化技术均面向通用性设计,可以应用在不同的业务场景中。Blade的每一步优化过程都对数值结果的准确性进行了验证,确保输出的优化结果不会对模型本来的精度或指标产生非预期的影响。
Blade推理优化引擎近期有机融合了PAI-TAO编译优化的技术,可以对模型中长尾的一些算子进行自动融合编译为后端的高效实现,可以进一步扩大Blade的优化覆盖面及提升模型推理性能。
接入方案
AutoAI 是 AILabs 内模型训练、部署、发布、灰度的一体化平台。我们在 AutoAI 实现模型推理优化功能的接入。
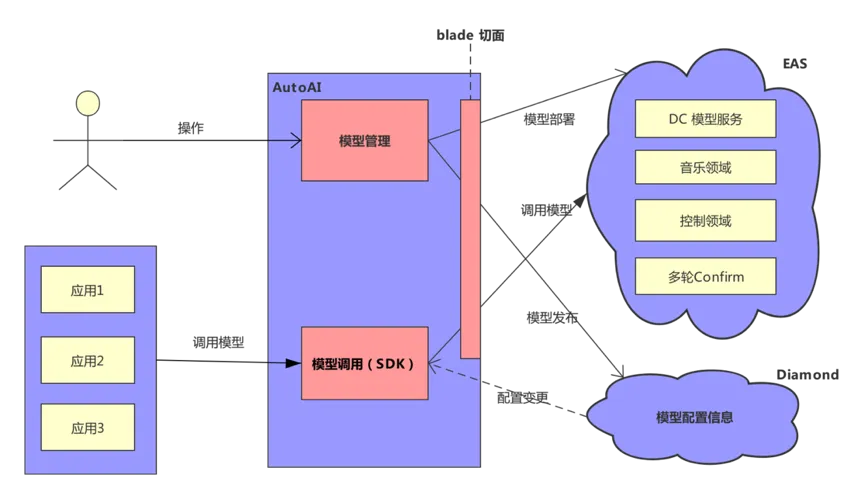
AutoAI 在线部分主要分为模型管理和调用 SDK。
- 模型管理: 用户通过模型管理进行模型的部署、发布操作。将模型部署到 EAS 服务,并将配置信息发布到 Diamond。
- 模型调用 SDK: 调用模型的应用通过 autoai 提供的模型调用 sdk 访问模型服务。模型管理同 sdk 通过共享 diamond 配置数据实现协同。模型更新后,diamond 配置信息同步更新。这些更新会同步给集成了 sdk 的应用。应用调用模型服务时使用对应的配置信息访问已发布的模型。
- blade 切面:blade 模型同普通 eas 模型在部署和发布的时候执行的动作都不相同。使用 blade 方式部署和发布的模型,调用的时候需要使用 blade-sdk,一般的 eas 模型调用的时候使用 eas-sdk。因此,我们使用 blade 切面来控制模型的部署、发布和调用。部署的时候,通过 blade 切面,根据配置是否是blade 模型进行部署。发布的时候,blade 模型指定特定的 processor 写入到 diamond。调用的时候,根据是否是 blade 模型,决定通过哪个模型访问客户端访问模型。
应用场景
我们在多个场景都使用 Blade 对模型进行推理优化。部分模型进行过定制优化,部分模型集成了 blade 已有的优化能力。
模型1
模型1 是一个 ASR 模型,整个模型架构采用encoder-decoder结构,其性能的消耗主要是在decoder上。
我们对比了有无blade,有无编译优化时的性能。相关配置:
- instance = 1
- gpu=1
- cpu = 16
测试结果如下:
|
qps |
rt |
无优化 |
10 |
600ms |
blade 优化 |
70 |
280ms |
blade +编译优化 |
70 |
180ms |
模型2
介绍
该模型使用BERT进行二分类,其中pre-train模型为google提供的中文bert模型,进行分类的句对分别为user query以及在answer库中召回的answer,如“天猫精灵早上好”和“你也早上好”。模型的返回值为0-1之间的连续值,返回值越大,表示qury和answer之间的问答对应关系越强。
测试
测试结果如下:
batchsize |
rt-baseline(毫秒) |
rt-blade(毫秒) |
1 |
62 |
22 |
10 |
73 |
39 |
20 |
87 |
58 |
50 |
130 |
95 |
100 |
201 |
160 |
模型3
介绍
该模型用于天猫精灵NLU时的领域分类。
输入是用户的query及词典数据,输出是领域类别标签。该模型也是基于 Transformer 结构的。
压测:
资源配置:1GPU, 4CPU
参数配置:batch_timeout=5, batch_queue_size=256
配置 |
是否blade |
应用客户端结果 |
模型服务端结果 |
workers=2,batch_size=8 |
否 |
qps:420, rt:38.82 |
qps:490, rt:30 |
workers=1,batch_size=8 |
否 |
qps:480, rt:33.5 |
qps:570, rt:24 |
workers=1,batch_size=12 |
否 |
qps:436, rt:36 |
qps:522, rt:27 |
workers=1,batch_size=16 |
否 |
qps:409, rt:38 |
qps:500, rt:29 |
workers=2,batch_size=8 |
是 |
qps:448, rt:37 |
qps:530, rt:28 |
workers=1,batch_size=8 |
是 |
qps:585, rt:28.6 |
qps:620, rt:19.5 |
workers=1,batch_size=12 |
是 |
qps:475, rt:33 |
qps:564, rt:23 |
workers=1,batch_size=16 |
是 |
qps:477, rt:33.5 |
qps:556, rt:23.5 |
模型4
介绍:
该模型是个语义匹配模型,输入是两段文本,输出是相关性分数。
测试:
资源配置:1GPU, 1CPU
参数配置: max_batch_timeout=5, max_queue_size=256
batch size |
非blade耗时 |
blade耗时 |
10 |
22.61ms |
21.73ms |
20 |
45.67ms |
42.49ms |
30 |
66.31ms |
60.53ms |
总结
为了提升天猫精灵业务的用户体验,需要对模型推理进行优化。我们主要接入了 PAI Blade 的模型优化能力,通过 AutoAI 接入 blade 模型的部署发布以及调用过程。从效果上看,接入 blade 最高可以降低 rt 70% 以上。在未经过定制优化的场景,blade 也可以减少至少 10% 到 20% 左右的 rt。


