作者:一皓,骄旸,心彦,张量,Yiping等云栖PPT合作同事
此文内容来自云栖大会人工智能芯片专场,想了解更多情况请观看云栖大会回放
云栖大会回放(9月25日下午人工智能芯片专场)
古往今来,中外各国,兵器种类繁多。中国有“十八般兵器“,还有不少奇门兵器。这是因为兵器有长短,利钝,刚柔,等各种特点,各有利弊,没有一把兵器能集齐所有优势。
所谓“剑走偏锋锋芒露”,是指剑身细长轻盈,所以剑法要以快为主,以攻为主,用剑者讲求身法灵动,招式精奇,以求出奇制胜!
上古三剑 一曰“含光”
视不可见 运之不知其所触
泯然无际 经物而物不觉
前言
2019云栖圆满结束,含光800正式发布,成为了焦点中的焦点。只有少数人有幸参加云栖,现场见证这激动人心的时刻。其他人大都通过媒体报道才了解到相关产品的信息。当我看到各式各样的报道,特别有一些文章充满了误解和偏见的时候,我觉得应该站出来,给大家详细地介绍一下云栖上相关的slides,纠正一些外界错误的解读。同时让阿里同事对我们的含光800NPU有进一步的了解。
下面介绍的内容会限制在slides里原有的内容,其他更多的内容会在时机成熟的时候,做进一步分享。

含光800定位

上面是业务定位的一张PPT,针对业务定位,大家主要的一些疑问:
Q:为什么只做了推理芯片
其实这个问题的答案很简单,大家只要稍微想一下就会理解。
- 首先,随着越来越多的AI应用落地,推理业务量远大于训练业务量。这种趋势在阿里内部更是明显。所以从业务量的角度来说,推理是第一优先级。
- 其次,阿里做AI芯片是从零开始,我们的团队是一个一个从不同的公司陆陆续续招过来的,好多人其实都没做过AI芯片。虽然每一个人都是像平头哥一样战斗力极强,但在人少,时间短的情况下,一定要集中精力做好一个方面。
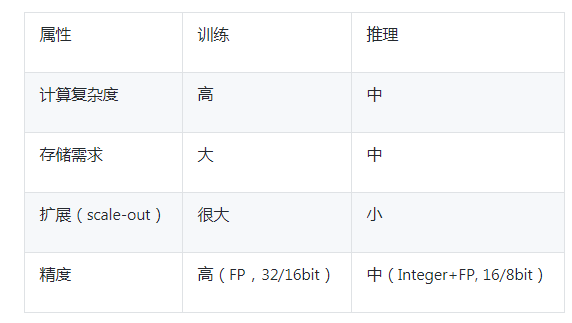
- 再次,从训练和推理的属性/需求做分析 (部分模仿Habana Hot Chip 2019的一些总结),推理可以视为训练的基础和踏脚石。
之前的一篇文章里提到的以色列AI初创公司Habana Labs也是同样的产品路线图策略:先出高性能的推理芯片Goya,然后一年以后才推出训练芯片Gaudi。
Q:计算加速的算法定位
计算芯片从通用变得越来越专用了,这是基于特定领域架构(Domain-Specific Architecture, DSA)的芯片设计趋势。它是和通用计算不同的一种发展方向,
- 一方面在摩尔定律失效的今天,是提高芯片性能一种很好的思路,
- 另一方面,芯片设计越来越成熟,加上DSA架构相对简单,这种思路能够快速地量产和迭代,跟随AI技术的发展。
- 同时,当前人工智能的应用还是比较集中,主要在视觉,搜索,推荐,语音,自然语言等方面。
我们分析阿里集团内部的人工智能应用场景需求,确定了以CNN模型为主做了深度的优化,同时支持一些通用模型,比如RNN类模型等。这是针对特定深度学习算法领域做特别的优化,把相关应用的性价比提高到极致。
Q:为什么要做个大芯片
看到有文章在质疑,为什么含光800做这么大,整合了比较大的本地存储?提出了三个主要的问题:
- 功耗高,不适合云端的超大规模集群的部署;
- 面积大,影响芯片良率,芯片成本高;
- 算力过剩,没什么必要,业务量没那么大,或者系统里其他地方成了瓶颈。
粗看上面的问题是有些道理,但其实我们是考虑了相关因素的。首先,请看下面这张表,我们有多种工作模式来调整适应不用的应用场景,可以通过调频,调压,调整核心的数目等多种方式来达到这个目的。而且大的本地存储看起来一方面是增加了功耗,但同时加少了传输和拷贝的次数对应的功耗。静态功耗相对动态功耗本身就比较小,一加一减之后,实际平均功耗的增加是不明显的。

其实和其他芯片直接对比,含光800面积功耗并不突出。只是大家以传统的观点去看新颖的AI算法架构,对较大的本地存储产生了直观的想法,就是这个芯片肯定特别大。
另外,如上一图中所写,根据阿里集团的主要业务形态,我们选择以数据中心,边缘服务器以及大型终端为目标。这写业务都是急需大量算力的地方。很多的业务方同事都给我们反映,他们业务和算法需要大量的GPU,受制于GPU的算力和高价格,没法铺开业务量,有些业务甚至没办法开展。所以他们急需高性能和高性价比的芯片。
最重要的,这也是我们的最初的目标:做第一!这个世界,人们只会记得第一,少有人会记得第二,就好像人们只能记住世界上第一个登月的人是阿姆斯特朗,谁会记得第二个登月的是谁。虽然他和阿姆斯特朗一起,只差15分钟,成为第二位踏上月球的人类。
Q:为什么没有解码器
翻看相关的应用,我们会发现很多的应用其实是不需要编解码器。而我们含光800的目的是极限地加速深度学习算法,不是做一款功能齐全的芯片,或者整合更多IP的SoC。试想,为了匹配含光800的超大算力,再整合一个超大的编解码器,这个芯片就更是巨无霸了。
当然时间短,整合太多的IP会影响芯片问世的时间了。
其实,市场上有很好的编解码可以和含光800搭配,比如,Intel VCA2。对需要编解码功能的应用场景,可以比较灵活地搭配相适应的算力的两种卡,这样搭配性价比很高,充分发挥两种卡的算力。而对不需要编解码的应用场景,也不用担心浪费了芯片的整合解码器(如果有的话)。
芯片架构
打造一把无双的神兵利器,需要稀世的材料,也需要独特的技能。我们来看看打造“含光”用了些什么材料和技能?!
顶层架构
含光800最顶层的架构图如下:
顶层架构图看起来比较简单,粗看会觉得和其他架构差别不大:
- 多核,核的具体数目可以根据设计情况变化,每个核可以独立工作,包括子模块:
-
- 多个Tensor Array,主要负责卷积,矩阵乘等张量操作(Tensor Operation)。
- 和每个Tensor Array对应,有一块本地存储(Local Memory)保存相关数据
- 一个Vector Engine,负责向量相关的操作
- 一个控制单元(SEQ),负责指令的解码,调度和发射,各种事件同步,以及标量寄存器和运算。
- 一个DMA引擎
- 其他还包括一个命令处理器(CP)和PCIE Gen 4.0.
这些模块的设计暂时不方便详细介绍。我们可以从顶层架构来仔细观察,和其他架构对比,顶层架构的有两个创新点:
- 存储系统:只有一级本地存储,相对其他芯片的L1+L2来说,比较大
- 核间通信(xCORE-COMM)
存储系统
存储系统的创新,是含光800能获得高性能的最大保证。我们都知道深度神经网络是数据密集型计算,参数量大,计算的中间值也量大。怎样设计好数据的存储,传输和输入-计算-输出的流水线工作模式,对最终的性能和效率至关重要。反之,一旦存储系统设计不合理,很容易变成整个芯片和整个应用系统的瓶颈,这种情况下,再多的理论算力(TOPS)都是没有意义的。
如果了解传统CPU/GPU,以及其他新的Ai 芯片,比如华为Davinci架构,前一篇文章分析的Habana Labs的Goya,我们就会发现,这些芯片都是除了各种cache/buffer之外,都是两级或两级以上的片上存储。L1存储是各个核心的本地存储,L2通常是共享存储,有些芯片还有L3的缓存。多级缓存的目的,本身也是希望使用大小比较合适的存储,通过合理的分布式cache和级间调度,消除数据传输的瓶颈,提高算力的效率。

以上面Davinci架构核心为例,存储系统也是经过非常细致地设计:
- 8M L2,保证一定地片上存储,缩短DMA延迟(推理SoC上还有L3,但不一定会被Davinci核心使用)
- 1M L1,接存储转换单元(MTE),输入计算单元前做格式转换
- 双Cube输入缓冲(A,B),交替准备数据,减少MTE延迟
- 累加器缓存(C)
- 输出缓存
特别地,针对神经网路计算输入类型和格式比较多,输出比较单一的特点,达芬奇架构设计了多输入方式,单一输出方式的存储系统。具体的说,数据的输入可以通过L2到L1输入缓冲,也可以直接通过MTE到缓冲A/B,甚至可以到输出缓冲。当然这是由软件根据需要,比如,是否需要MTE转化,前后计算的依赖,最大并行可能等来判断和控制的。输入的输出就比较单一,都是输出到缓冲区再输出的。
根据经验,可以想象华为的软硬件部门一定需要很仔细地调整了相关流程和控制,即使这样,考虑到L1的大小有限(1M),在一些复杂的网络结构和多输入的情况下,估计还是很难做到不成为瓶颈的。有兴趣的话,可以尝试去计算一下核心算力的利用率来看看这个推测。
含光的存储系统,以相对大得多的L1缓冲大小,以及合理的存储布局,加上软件系统的配合,避免了上述的问题。在以后的详细介绍中,我们可以看看相关系统的设计创新点。
核间通信
传统多核系统中,核间基本没有直接通信和数据传输的,通常都是通过调度器/控制器来间接通信,数据也是需要通过L2缓存,同时也需要一致性的保证。整个通信和传输相对不是特别高效,延迟高。
在深度神经网络的计算中,比如卷积,或者矩阵乘等操作,通常参数量都非常大。由于每个核心配备的存储大小有限,所以往往矩阵A*B,需要将矩阵B拆分成多个。比如,可以按照块m*n的大小来份块,也可以按照某一个维度,比如M*N的矩阵,将N分成多份,每份n,这样就变成M*n的小矩阵,每个核心一次完成其中一个小矩阵的运算。
缓存小的时候,B的每个子矩阵M*n需要一个一个依次但又重复地拷贝到缓存中,完成整个一个个的输入A和矩阵B的计算。但是在大容量缓存的时候,子矩阵可以常驻不同核心的缓存,这时可以通过核间通信和数据传输,来完成高效的运算。
这是伴随存储系统创新产生的新的通信和数据传输的创新点。对解决大的模型的存储访问效率非常关键。
架构特性
含光800的架构特性,在下面这张PPT里描述得比较清楚,限于篇幅和时机的原因,这里暂时不展开具体对每一个特性做详细地介绍。

含光800是阿里AI芯片的针对应用领域做优化的处理器架构(DSA)的实践。所以我们通过前期深度调研,结合算法,软件和硬件架构共同设计,产生了上面相关的一些特性。
但是,含光800并不局限在上面这些深度优化的算法,我们通过软件栈的合理转换和编译,将它运用在更多的领域。当然在后续的芯片中,会针对更多,更新的应用模型来加入新的支持。这本身就是DSA架构的一个精髓:领域和算法专用,快速迭代。
架构对比
再回到DSA架构的话题,针对几个不同的芯片架构做一下对比,
- CPU,最通用的计算架构。
- GPU(例如Tesla T4),可以说是一个通用的AI架构,能实现各种的AI算法,计算核心是由tensor core + cuda core一起组成。
- DaVinci架构,我的看法,也是一个比较接近GPU架构,是一个通用的AI架构,由矩阵,向量,标量计算单元组成,或者说是一种,和华为AI应用定位相关,这个核心的应用场景非常广。当然也有华为在CPU,GPU上面的技术积累相关,做一个增量式的开发,加入矩阵/向量计算单元等AI需要的部分。
- Habana Goya,比较偏专用AI推理架构,适用大部分现有的深度学习算法
- 含光800,和Goya比较类似,同时创新的力度更大,软硬件结合更密切。
现在估计大家对什么是打造含光的材料和技能有了一个答案。
软件栈架构
神兵利器一定需要绝世剑法,否则就形如破铜烂铁!
对于“含光”来说,这剑法就是HanGuangAI软件栈。因为在软硬协同的DSA芯片系统中,软件栈的重要性不言而喻。只有依靠他,才能发挥硬件的设计优势,得到优异的系统性能。
我们希望能过通过HanGuangAI,
- 用户能通过主流的深度学习框架无缝使用含光NPU,
- 程序开发者能简单方便的基于NPU做开发,
- 更高效地利用含光NPU,充分发挥它的性能
群雄争霸
深度学习,群雄混战的时代!学习框架就有好几大门派:Tensorflow, Pytorch, MxNet, ...。计算芯片也是遍地开花,传统的CPU,两家独立GPU,还有无数的不同架构的AI芯片...。于是乎,学习框架想更好地支持更多的计算芯片,计算芯片也希望能更好地支持更多的框架!
前端
上一篇文章里提到,各家框架尝试使用多层IR的架构,将硬件无关的部分提炼出来,专注于与特定硬件模型无关的图和数学相关优化。在他们的后端,都支持将他们的中间表示(IR)重定向到不同的硬件后端。
- Pytorch---GLOW,Habana积极参与的一个架构
- Tensorflow---MLIR,开发中,统一和简化Tensorflow里的多种中间IR
- MxNet---NNVM/Relay+TVM,外部应用最广的一个AI栈,不少公司基于这个架构开发
需要注意的是,NNVM+TVM是一个更大范围和目标的架构,前端,希望对接更多的框架模型,后端通过TVM Primitives对接更多的硬件相关的编译器后端。
后端
特别的,我们看看华为MindSpore-TBE架构,当然TBE是既可以用在MindSpore框架,也可以对接到其他框架的后端。

从现在看到的材料看,Ascent AI软件栈是以TVM的为基础,或者说作为参考来设计实现的,增加了上面TBE后端代码生成的部分。这样可以利用很多现成的东西,包括TVM的计算代码,对接更多的框架,实现Ascend AI处理器的支持。
HanGuangAI顶层架构
整体架构来说,HanGuangAI软件栈和Goya的SynapseAI软件栈比较接近。我们没有利用现有的任何一个框架和编译器,而是自己开发了自己的图IR,将其他的模型转化自己的内部图,然后优化和编译。自己也开发了对应的运行是的各种管理来负责设备,核心,存储,批量等深度管理。一个重要的原因是对于我们的DSA芯片来说,这样可以最大限度地发挥硬件的能力。
HanGuangAI软件栈的顶层架构图如下:

整个软件栈从上往下,分别是应用层,框架层,功能层。
- 应用层
所有深度深度学习推理的应用,例如视觉,语音,推荐等上面提到的各种应用场景。这些应用可以基于莫一种支持的深度学习框架,也可以直接掉用HanGuangAI和运行时提供的API。 - 框架层
目前我们支持TensorFlow, MXNet, Caffe,也包括独立的模型格式ONNX。我们提供了一系列的算子库和工具,整合到原始的框架中,使用户能够方便地使用HanGuang API。 - 功能层
HanGuangAI是软件栈核心,根据功能和使用场景,主要分为两部分:
-
- 编译栈:转换框架IR为HanGuang IR,然后离线量化、图优化和编译
- 推理运行时:转换完的NPU模型可以直接调用运行时接口在NPU上进行推理运算。
编译栈
编译栈大致可以分为以下四大部分:
- 转化:将框架模型,转换成HanGuangAI内部的图IR,量化,编译后再转回原始的框架模型IR
- 量化:根据含光800的特性,将float模型量化为INT8/INT16的网络模型
- 优化:图优化,算子融合,多模型优化链接等
- 编译:转换成底层IR,更多的硬件ISA优化,最后根据ISA生成二进制网络
HanGuangAI编译栈的一些特点:
- 混合精度的量化:做到精度和性能的平衡。
- 预先优化编译(AOT),可以做到多级优化,在模型,图,指令各个层次针对NPU做优化。
- 多device的联合编译链接,做到资源的分配优化,充分地利用本地存储以获得更高的吞吐。
这里简单地说三点,里面有太多的细节后面可以单独地由量化,编译等相关技术专家给大家进行介绍。
运行栈
运行栈也大致可以分为以下四个层次:
- 执行引擎:基于框架和HanGuangAI运行时API组织管理设备(device/core)和引擎等
- 执行管理器:执行的资源分配,批量调度,优化
- 用户态驱动:存储的管理,生成硬件command,command buffer调度
- 核心态驱动:内核,任务调度,硬件控制
运行栈的一些特点:
- 多设备,多核心的优化调度
- 推理执行的调度,既保证小batch的低延迟,也保证大batch的高吞吐。
- 高效的存储管理,使数据的输入,运算,输出工作在流处理模式。
这一块也是在持续地优化改进完善中,后续根据大家的兴趣点多做一些介绍。
工具链
我们打造了一些的工具链,包括
- 基于框架的模型量化,编译前端工具Agraph,目前支持Tensorflow, MxNet
- 可以框架和HanguangAI的测试工具栈Kaleido
- 基于Agraph的性能评估工具benchmark tool
- API logger/player
- npusmi,含光800的硬件configure/query/test工具
更多的工具正在开发和计划中。
性能解读
Q:含光800如何获得这么好的性能
我们正在准备更多的性能数据,做正式的披露。鉴于时机不成熟,此处暂不对性能做更详细的解读。下面是官方的介绍:
“含光800性能的突破得益于软硬件的协同创新。芯片架构方面,含光800采用创新的架构,针对深度学习中使用的大量权重参数和张量数据,在支持稀疏压缩与量化处理的基础上,通过独特设计的数据访存与流水线处理技术,大大减低了I/O需求和数据的搬移。NPU同时深度优化了卷积、矩阵乘、向量计算和各种激活函数,通过高有效的硬件资源调度和全并行的数据流处理,把AI运算的性能和能效双双推向极致。
算法方面,阿里巴巴达摩院机器智能实验室过去两年构建了完整的算法体系,涵盖语音智能、语言技术、机器视觉、决策智能等方向,并且取得多个世界领先水平的成果,这些都为平头哥研发芯片提供了帮助。
协同算法和芯片架构的设计理念效果可以说是立竿见影的。例如,功耗是人工智能芯片行业通病,但平头哥的自研架构可大幅减少对内存的访问,在保证极致性能的情况下,把芯片功耗降到最低水平。”

需要稍微解释一下的是,官方PPT上的IPS是在保证含光800在充分地吞吐下的结果。但如果使用AI框架运行时,由于含光NPU太快了,瓶颈变成了框架或者数据往NPU的上传/下载,实际的结果看起来就会查一下。
Q:为什么没有含光的TOPS数据
TOPS是Tera Operations Per Second的缩写,1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作。
AI芯片经常使用TOPS来表达处理器运算能力,但这个运算能力是理想的100%的计算单元利用率下的能力。实际的系统中,性能还有很重要的其他的因素,比如上面说的存储系统,软件系统等。所以不同的芯片系统,实际性能和理论TOPS差距可能各不相同,这是我们为什么你没有特别的提到TOPS的一个重要原因。
Q:是否只是针对Resnet优化了
含光800虽然是领域专用AI芯片,但并不是只局限在图像视频方面的应用,更不会只是针对Resnet做优化。我们的芯片能覆盖阿里的大部分AI应用场景。后期我们会通过论文或其他正式的形式提供更多的应用深度网络的性能数据给大家。
后记
从摩尔定律到算法即芯片的时代慢慢开启!
含光架构基于阿里的AI算法研究和应用,采用了Domain Specific Architecture的理念,尝试和实践了先进的软硬协同的方法。为我们以后的芯片打下了坚实的基础。
本文的介绍比较简单,因为涉及到一些正式流程的问题,细节没有深入的介绍。但通过整体的介绍,读者也应该对含光800的软硬件有了大致的了解。后续继续对硬件架构,HanGuangAI API,如何发挥含光的高性能等做深度介绍。