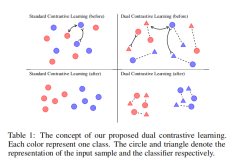
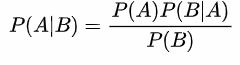Situation
2016年,A市对30000+市民进行了年收入统计,收入>=50K的人数7000+,<=50K的人数20000+。
为了提高税收,需要分析两种收入群体的特征,分析员抽取了“职业、年龄、性别、出生地、教育程度”等属性,更进一步分析哪些职业收入高,哪个年龄段收入高等等,为来年税收做预测。
问题来了:2017年2月,A市人口增加了20000+,对这个群体年收入做预测。
朴素贝叶斯
分类算法有很多种,今天讲朴素贝叶斯的原理和Java实现。
朴素贝叶斯分类的正式定义如下:
-
设为一个待分类样本x,而每个a为x的一个特征属性。
-
分类集合。
-
计算分类样本x的分类概率。
-
求样本x的分类概率max。




要解决上面提到的问题,对新的人口样本做年收入预测,一般的步骤如下(适合入门的同学):
- 历史样本准备。
- 训练,输出模型。
- 测试,输出测试结果。
- 评估,评估测试结果,预测模型是否足够准确。
- 应用。
接下来上代码:
样本
public class Sample {
//分类
private String label;
//属性
private List<Attribute> attributes;
public Sample(String label, List<Attribute> attributes) {
this.label = label;
this.attributes = attributes;
}
public Integer getId() {
return hashCode();
}
public String getLabel() {
return label;
}
public List<Attribute> getAttributes() {
return attributes;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Sample sample = (Sample) o;
if (!attributes.equals(sample.attributes)) return false;
if (!label.equals(sample.label)) return false;
return true;
}
@Override
public int hashCode() {
int result = label.hashCode();
result = 31 * result + attributes.hashCode();
return result;
}
}属性
public class Attribute {
private String field;
private String value;
public Attribute(String field, String value) {
this.field = field;
this.value = value;
}
public String getField() {
return field;
}
public String getValue() {
return value;
}
}训练
- train
/**
* 训练
*/
public void train() {
calClassesPrior();
calFeatureClassPrior();
}- 分类的先验概率
/**
* 计算分类先验概率
*/
private synchronized void calClassesPrior() {
for (Sample sample : trainingDataSet) {
String label = sample.getLabel();
Double labelCount = classCount.get(label);
if (labelCount == null) {
classCount.put(label, 1.0);
} else {
classCount.put(label, ++labelCount);
}
}
Double total = new Double(trainingDataSet.size());
for (Map.Entry<String, Double> entry : classCount.entrySet()) {
Double prob = entry.getValue() / total.doubleValue();
classPrior.put(entry.getKey(), prob);
}
}- 特征在各分类的先验概率
/**
* 计算feature class的先验概率
*/
private synchronized void calFeatureClassPrior() {
Map<String, Double> featureClassCounts = new HashMap<String, Double>();
for (Sample sample : trainingDataSet) {
String label = sample.getLabel();
for (Attribute attribute : sample.getAttributes()) {
String attName = attribute.getField();
String attValue = attribute.getValue();
//feature class key
String fc = String.format(FEATURE_CLASS_FORMAT, attName, attValue, label);
Double fcCount = featureClassCounts.get(fc);
if (fcCount == null) {
featureClassCounts.put(fc, 1.0);
} else {
featureClassCounts.put(fc, ++fcCount);
}
}
}
//输出模型
for (Map.Entry<String, Double> entry : featureClassCounts.entrySet()) {
String label = entry.getKey().split("_")[2];
Double prob = (entry.getValue() / classCount.get(label)) * getClassPrior(label);
featureClassProb.put(entry.getKey(), prob);
System.out.printf("f|c: %s, fc count: %f, class count: %f , P(f|c): %.12f \n", entry.getKey(), entry.getValue(), classCount.get(label), featureClassProb.get(entry.getKey()));
}
}- 属性特征分类概率
f|c: a8_ 2635_ <=50K, fc count: 11.000000, class count: 24720.000000 , P(f|c): 0.000337827462
f|c: a10_ 63_ <=50K, fc count: 7.000000, class count: 24720.000000 , P(f|c): 0.000214981112
f|c: a9_ 1668_ <=50K, fc count: 4.000000, class count: 24720.000000 , P(f|c): 0.000122846350
f|c: a8_ 7896_ >50K, fc count: 3.000000, class count: 7841.000000 , P(f|c): 0.000092134762
f|c: a9_ 2489_ <=50K, fc count: 1.000000, class count: 24720.000000 , P(f|c): 0.000030711587
f|c: a10_ 65_ >50K, fc count: 104.000000, class count: 7841.000000 , P(f|c): 0.003194005098
f|c: a10_ 74_ <=50K, fc count: 1.000000, class count: 24720.000000 , P(f|c): 0.000030711587
f|c: a8_ 4865_ <=50K, fc count: 17.000000, class count: 24720.000000 , P(f|c): 0.000522096987
f|c: a10_ 7_ >50K, fc count: 4.000000, class count: 7841.000000 , P(f|c): 0.000122846350
f|c: a10_ 70_ >50K, fc count: 106.000000, class count: 7841.000000 , P(f|c): 0.003255428273
f|c: a11_ Yugoslavia_ <=50K, fc count: 10.000000, class count: 24720.000000 , P(f|c): 0.000307115875
f|c: a9_ 1902_ <=50K, fc count: 13.000000, class count: 24720.000000 , P(f|c): 0.000399250637
f|c: a2_ 2_ <=50K, fc count: 162.000000, class count: 24720.000000 , P(f|c): 0.004975277172
f|c: a10_ 30_ <=50K, fc count: 1066.000000, class count: 24720.000000 , P(f|c): 0.032738552256
f|c: a8_ 3674_ <=50K, fc count: 14.000000, class count: 24720.000000 , P(f|c): 0.000429962225
f|c: a8_ 34095_ <=50K, fc count: 5.000000, class count: 24720.000000 , P(f|c): 0.000153557937
f|c: a10_ 13_ >50K, fc count: 2.000000, class count: 7841.000000 , P(f|c): 0.000061423175
f|c: a11_ Thailand_ >50K, fc count: 3.000000, class count: 7841.000000 , P(f|c): 0.000092134762
f|c: a10_ 41_ <=50K, fc count: 29.000000, class count: 24720.000000 , P(f|c): 0.000890636037 分类
/**
* 分类
*
* @param sample
* @return
*/
public String classify(Sample sample) {
String clazz = "";
Double clazzProb = 0.0;
for (Map.Entry<String, Double> classProb : classPrior.entrySet()) {
String label = classProb.getKey();
Double prob = classProb.getValue();
for (Attribute attribute : sample.getAttributes()) {
prob *= getFeatureProb(attribute.getField(), attribute.getValue(), label);
}
if (prob > clazzProb) {
clazz = label;
clazzProb = prob;
}
}
System.out.printf("probability: %.12f ,class pre: %s, class fact: %s \n", clazzProb, clazz, sample.getLabel());
return clazz;
}测试
抽样100条测试数据进行分类
probability: 0.000001088450 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000000053 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000918274 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000000002 ,class pre: >50K, class fact: >50K.
probability: 0.000000016812 ,class pre: <=50K, class fact: >50K.
probability: 0.000000002483 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000003344 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000012379 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000485467 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000262052 ,class pre: <=50K, class fact: <=50K.
probability: 0.000000000024 ,class pre: <=50K, class fact: >50K.
probability: 0.000005353829 ,class pre: <=50K, class fact: <=50K.
probability: 0.000004912284 ,class pre: <=50K, class fact: >50K.
total: 100 correct: 84gitlab源码
内网:gitlab/我的域账号/algorithm
后记
2017年,A市对40000+市民进行了居住满意度调研,衣食住行,结果市民对环境很不满意。
问题:改善环境对税收的收益。