前言
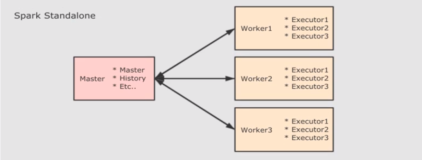
Cassandra是一款去中心化的分布式数据库。一份数据会分布在多个对等的节点上,即有多个副本。我们需要定期的对多个副本检查,看是否有不一致的情况。比如因为磁盘损坏,可能会导致副本丢失,这样同一份数据的多个副本就会出现不一致。
nodetool repair
Cassandra提供的nodetool中提供了repair这个工具,可以用来日常巡检数据的一致性。或者当修修改了keysapce 副本配置时,也需要运行此工具。
可以通过nodetool help 'repair'查看命令帮助,如下:
NAME
nodetool repair - Repair one or more tables
SYNOPSIS
nodetool [(-h <host> | --host <host>)] [(-p <port> | --port <port>)]
[(-pw <password> | --password <password>)]
[(-pwf <passwordFilePath> | --password-file <passwordFilePath>)]
[(-u <username> | --username <username>)] repair
[(-dc <specific_dc> | --in-dc <specific_dc>)...]
[(-dcpar | --dc-parallel)] [(-et <end_token> | --end-token <end_token>)]
[(-full | --full)]
[(-hosts <specific_host> | --in-hosts <specific_host>)...]
[(-j <job_threads> | --job-threads <job_threads>)]
[(-local | --in-local-dc)] [(-pl | --pull)]
[(-pr | --partitioner-range)] [(-seq | --sequential)]
[(-st <start_token> | --start-token <start_token>)] [(-tr | --trace)]
[--] [<keyspace> <tables>...]
OPTIONS
-dc <specific_dc>, --in-dc <specific_dc>
Use -dc to repair specific datacenters
-dcpar, --dc-parallel
Use -dcpar to repair data centers in parallel.
-et <end_token>, --end-token <end_token>
Use -et to specify a token at which repair range ends
-full, --full
Use -full to issue a full repair.
-h <host>, --host <host>
Node hostname or ip address
-hosts <specific_host>, --in-hosts <specific_host>
Use -hosts to repair specific hosts
-j <job_threads>, --job-threads <job_threads>
Number of threads to run repair jobs. Usually this means number of
CFs to repair concurrently. WARNING: increasing this puts more load
on repairing nodes, so be careful. (default: 1, max: 4)
-local, --in-local-dc
Use -local to only repair against nodes in the same datacenter
-p <port>, --port <port>
Remote jmx agent port number
-pl, --pull
Use --pull to perform a one way repair where data is only streamed
from a remote node to this node.
-pr, --partitioner-range
Use -pr to repair only the first range returned by the partitioner
-pw <password>, --password <password>
Remote jmx agent password
-pwf <passwordFilePath>, --password-file <passwordFilePath>
Path to the JMX password file
-seq, --sequential
Use -seq to carry out a sequential repair
-st <start_token>, --start-token <start_token>
Use -st to specify a token at which the repair range starts
-tr, --trace
Use -tr to trace the repair. Traces are logged to
system_traces.events.
-u <username>, --username <username>
Remote jmx agent username
--
This option can be used to separate command-line options from the
list of argument, (useful when arguments might be mistaken for
command-line options
[<keyspace> <tables>...]
The keyspace followed by one or many tables主要用法说明
nodetool repair mykeyspace mytable 检查并修复特定表
常用参数:-j <job_threads>, --job-threads <job_threads>
后台并行运行的RepairSession个数,一个RepairSession对应一组节点以及节点共同维护的分区。这个谨慎调整,会增加集群负载。
-full, --full
全量检查并修复,2.2之后的版本引入增量修复功能(increment repair),默认都是走增量。增量修复会把已经repair过的数据从sstable里分离出来,分成2个sstable,一个是检修过的,一个是包含未检修数据(这个过程叫AntiCompaction)。这样下次运行repair只会检查没有修复过的那个sstable,减少磁盘带宽和建立MerkleTree开销,避免影响在线服务(repair过程是会读取数据并建立MerkleTree,然后在某一节点上对比不同节点上各自维护的副本的MerkleTree)。
-st <start_token>, --start-token <start_token>-et <end_token>, --end-token <end_token>
自定义token范围,也就是分区(range)范围。比如(100,1000] 表示只检查一致性hash环上从100到1000这个区间段内分区段数据。默认无需指定,会检修运行repair命令的当前节点上所有token。指定了这个参数,相当于做一个subrange repair,会跳过AntiCompaction。一如果想避免AntiCompaction的影响,可以自己计算好token范围,自己做多个subrange repair。
-pr, --partitioner-range
只检修主要的range。主要range是什么?比如一行数据被hash到某个range,也就是对应了某个token(此token假设由节点A负责)。然后因为keyspace是多副本的,会根据keyspace配置的ReplicationStrategy,再选出多个token负责(这些token是不同节点维护的)存放副本。那么这个range对于节点A而言就是主要range。
此参数不做subrange repair才有效
-dc <specific_dc>, --in-dc <specific_dc>
检修只会涉及到指定dc中的节点
-hosts <specific_host>, --in-hosts <specific_host>
检修只会涉及到指定主机列表中的节点
写在最后
为了营造一个开放的Cassandra技术交流环境,社区建立了微信公众号和钉钉群。为广大用户提供专业的技术分享及问答,定期开展专家技术直播,欢迎大家加入。另云Cassandra免费火爆公测中,欢迎试用:https://www.aliyun.com/product/cds