2019年,国际语音交流协会INTERSPEECH第20届年会将于9月15日至19日在奥地利格拉茨举行。Interspeech是世界上规模最大,最全面的顶级语音领域会议,近2000名一线业界和学界人士将会参与包括主题演讲,Tutorial,论文讲解和主会展览等活动,本次阿里论文有8篇入选,本文为Shiliang Zhang, Yuan Liu, Ming Lei, Bin Ma, Lei Xie的论文《Towards Language-Universal Mandarin-English Speech Recognition》
点击下载论文
文章解读
目前的语音识别系统主要是针对特定语种的识别系统,例如中文语音识别,英文语音识别系统等。对于一个智能交互系统,通常需要部署不同语种的语音识别系统,这个极大增加了系统的存储开销。同时很多时候用户说某个语种是没有先验的,而且存在用户可能会在一句话中使用多个语种。这类问题称之为多语种语音识别和混读语音识别。其中具有代表性的是中英文混读情况。如何训练一个通用的中英文语音识别系统,可以不需要语种先验信息的前提下可以同时识别中文、英文、以及中英文混读是一个研究难点。
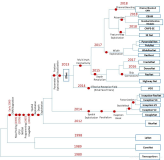
针对这个问题,本次INTERSPEECH论文,我们提出一种新颖的bilingual-AM (acoustic model)。具体的,我们利用大量单一语种的中文数据和英文数据先分别预训练得到一个中文声学模型和英文声学模型。 然后构建了如下图的bilingual-AM:

Bilingual-AM的输出层采用混合建模单元(中文—“字”,英文—“subword”)。声学模型结构采用深度前馈序列记忆神经网络(Deep Feedforward Sequential Memory Network, DFSMN), 优化准则采用CTC(Connectionist Temporal Classification)和 sMBR(state-level Minimum Bayes Risk)。进一步的我们通过将中文和英文n-gram语言模型进行插值得到一个混合的语言模型。
模型验证:我们先基于DFSMN-CTC-sMBR构建了基线的单一语种的语音识别系统,其性能如下图1所示。进一步的我们采用单一语种的中文和英文数据得到一个混合的数据,基于Bilingual-DFSMN-CTC-sMBR训练了中英文识别系统,性能如下图2所示。结果表明我们提出的中英文识别系统,在不需要语种先验信息的情况下,可以同时识别中文和英文,相比于特定语种的中文和英文识别系统,性能基本无损。

图 1. 特定语种的中文和英文识别系统性能。

图 2. 中英文混读识别系统在中文测试集和英文测试集上的性能。
进一步的我们在中英文混读测试集上对比了我们提出的方法和之前普遍采用的方法的性能。如下图3,我们提出的方法相比于基线系统具有明显的性能提升。

图 3. 对比不同的中英文混读系统在混读测试集上的性能。
文章摘要
Multilingual and code switching speech recognition are two challenging tasks that are studied separately in many previous works. In this work, we jointly study multilingual and codeswitching problems, and present a language-universal bilingual system for Mandarin-English speech recognition. Specifically, we propose a novel bilingual acoustic model, which consists of two monolingual system initialized subnets and a shared output layer corresponding to the Character-Subword acoustic modeling units. The bilingual acoustic model is trained using a large Mandarin-English corpus with CTC and sMBR criteria. We find that this model, which is not given any information about language identity, can achieve comparable performance in monolingual Mandarin and English test sets compared to the well-trained language-specific Mandarin and English ASR systems, respectively. More importantly, the proposed bilingual model can automatically learn the language switching. Experimental results on a Mandarin-English code-switching test set show that it can achieve 11.8% and 17.9% relative error reduction on Mandarin and English parts, respectively.
Index Terms: speech recognition, Mandarin-English, codeswitching, bilingual, DFSMN-CTC-sMBR
阿里云开发者社区整理