2019年,国际语音交流协会INTERSPEECH第20届年会将于9月15日至19日在奥地利格拉茨举行。Interspeech是世界上规模最大,最全面的顶级语音领域会议,近2000名一线业界和学界人士将会参与包括主题演讲,Tutorial,论文讲解和主会展览等活动,本次阿里论文有8篇入选,本文为Shiliang Zhang, Ming Lei, Zhijie Yan的论文《Investigation of Transformer based Spelling Correction Model for CTC-based End-to-End Mandarin Speech Recognition》
点击下载论文
文章解读
基于CTC(Connectionist Temporal Classification)的端到端语音识别系统,通常需要联合语言模型进行解码。对于中文,由于存在大量的同音字,所以联合语言模型进行解码显的更为重要。因为很多同音字的替换错误只靠声学模型是没法区分的,需要通过语言模型引入语义信息进行辅助区分。但是目前CTC声学模型通过联合N-gram语言模型进行解码。从而导致很多同音替换错误依旧没法解码。针对这个问题我们提出了一个基于Transformer的后处理纠错模型,可以有效的纠正大量识别的替换错误。在一个2万小时中文数据库上的实验表明,通过引入纠错模型,我们可以获得3.41%的字错误率,相比于基线的CTC系统可以获得相对22.9%的性能提升。

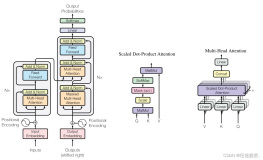
如图1,我们提出的方法包含3个模块:listener,decoder,speller。其中Listener是一个基于CTC训练准则优化的声学模型,实现从声学特征到建模单元序列(中文音节,字符等)的映射。Decoder是一个解码器,我们探索了不同的解码方法:Greedy Search(不采用语言模型);WFST search(采用语言模型)。特别的我们提出新颖的N-best数据扩展方法,得到识别结果的候选列表,用于训练候选的Speller。Speller是基于Transformer的翻译纠错模型,输入是带错的识别结果,预测目标是正确的标注。

图 1. 基线识别系统和添加了Speller的识别系统在不同测试集上的性能对比
如图1,我们对比了基线识别系统和添加了Speller的识别系统在13个测试集上的性能。通过添加speller可以获得明显的性能提升。如图2,则是一些识别例子的分析,我们可以发现,通过纠错模型可以有效纠正一些同音字的替换错误。

文章摘要
**Connectionist Temporal Classification (CTC) based end-to-end speech recognition system usually need to incorporate an external language model by using WFST-based decoding in order to achieve promising results. This is more essential to Mandarin speech recognition since it owns a special phenomenon, namely homophone, which causes a lot of substitution errors. The linguistic information introduced by language model is somehow helpful to distinguish these substitution errors. In this work, we propose a transformer based spelling correction model to automatically correct errors, especially the substitution errors, made by CTC-based Mandarin speech recognition system. Specifically, we investigate to use the recognition results generated by CTC-based systems as input and the ground-truth transcriptions as output to train a transformer with encoder-decoder architecture, which is much similar to machine translation. Experimental results in a 20,000 hours Mandarin speech recognition task show that the proposed spelling correction model can achieve a CER of 3.41%, which results in 22.9% and 53.2% relative improvement compared to the baseline CTC-based systems decoded with and without language model, respectively.
Index Terms: speech recognition, spelling correction, CTC,
End-to-End, Transformer
阿里云开发者社区整理