HIVE优化浅谈
作者:邓力,entobit技术总监,八年大数据从业经历,由一代HADOOP入坑,深耕云计算应用领域,由从事亚马逊EMR和阿里云EMR应用开发逐步转入大数据架构领域,对大数据生态及框架应用有深刻理解。
引言
随着商务/运营同学执行的HQL越来越多,整体HIVE执行效率变低,本文从HIVE切入,分析HQL面临的问题和待优化部分,结合其他大数据框架来解决实际问题。以下内容没有针对业务代码提供优化建议.
常见的HQL
select型
设置hive.fetch.task.conversion=none会以集群模式运行,无论是否有limit。在数据量小时建议使用hive.fetch.task.conversion=more,此时select配合limit以单机执行获取样本数据,执行更快
常见的select配合order by/group by等基本操作不在此赘述
注:
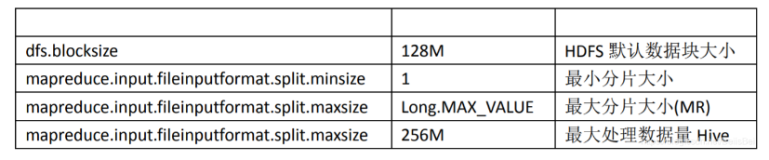
select查询可以通过split.maxsize和split.minsize控制并发MAPPER数量
insert型
分为两种
- insert into
- insert overwrite
配合分区可以达到重写分区或者在分区追加数据的目的。还可以配合动态分区模式插入对应分区
开启动态分区:
// 开启动态分区模式
set hive.exec.dynamic.partition=true;
// 开启动态分区非严格模式(多分区时首分区支持动态分区必要条件,首分区为静态分区可以不设置)
set hive.exec.dynamic.partition.mode=nonstrict;
// 单节点上限
set hive.exec.max.dynamic.partitions.pernode=100;
// 集群上限
set hive.exec.max.dynamic.partitions=1000;开启之后可以利用SQL达到动态插入的目的:
// 根据分区day动态插入数据
insert into table default.test partition(day) select id,day from orginalCTAS
全称CREATE TABLE AS SELECT语句,语法和MYSQL类似,可以指定存储/压缩包等
// 采用parquet存储已准备配合SparkSQL使用
create table default.parquet_test stored as parquet as select * from default.test
// 同时可以指定压缩格式
create table default.parquet_test stored as parquet
TBLPROPERTIES ( 'orc.compress'='SNAPPY')
as select * from default.test
// 指定OSS作为存储(推荐)
create table default.parquet_test stored as parquet location 'oss:xxx:yyy/parquet/test'JOIN优化
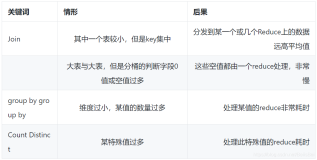
上面提到了常见的不同HQL类型,实际在执行的HQL中更可能变慢的时JOIN部分,以下会根据不同的场景来分析
大表x小表
这里可以利用mapjoin,SparkSQL中也有mapjoin或者使用广播变量能达到同样效果,此处描述HQL
// 开启mapjoin并设定map表大小
set hive.auto.convert.join.noconditionaltask = true;
set hive.auto.convert.join.noconditionaltask.size = 10000000;
// 大表 join 小表
select * from big_table join small_table on big_table.id=small_table.id原理:将小表加载进入节点容器内存中,大表可以直接读取节点容器内存中的数据进行匹配过滤
大表x大表
小表可以放进内存,大表则不行。尽量避免大表x大表的执行需求。如果确认有此需求,可以参考以下方法
-
尝试将大右表自我join成为一张宽表
// 利用右表的唯一属性自我join select id, case when type='food' then 0 else 1 as type_tag,case when sale_type='city' then sales else null as sale_amount from group by id -
尝试先将大表按照主键分桶后join
create table new_left as select * from left_table cluster by id create table new_right as select * from right_table cluster by id select * from new_left join new_right on new_left.id=new_right.id -
根据数据大小量级合理增加reduce数量,reduce不宜设置过大
// hadoop1代 set mapred.reduce.tasks= 200; // hadoop2代 set mapreduce.job.reduces=200; -
利用ORC bloomfilter, 大幅度提高join效率
注:parquet bloomfilter在开发中// 建立orc表 create table default.right_orc stored as orcfile TBLPROPERTIES ('orc.compress'='SNAPPY', 'orc.create.index'='true', 'orc.bloom.filter.columns'='id') as select * from right_table // 使用新表join select * from left_orc join right_orc on left_orc.id=righ_orc.id -
调整内存限制
join时容易造成节点OOM,导致任务失败,可以尝试以下方法:- map阶段OOM,适当增加map阶段内存 set mapreduce.map.memory.mb=3096
- reduce阶段OOM,适当增加reduce阶段内存 set mapreduce.reduce.memory.mb=4096
注: 默认执行引擎为mr,如果是TEZ,参考tez优化部分
- 善用explain/analyze
使用explain和analyze分析HQL语句和表,试图从中找出实际数据中可以优化的部分,这里和数据强关联,需要根据实际数据考量 - 数据预处理。将部分join放入离线计算任务,减少业务join的时间
更多思考
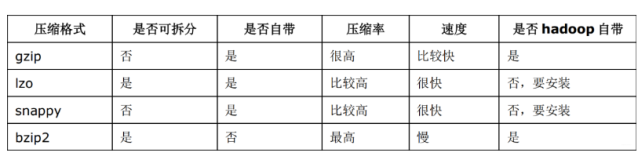
- 文件压缩后仍然很大:可以使用GZIP压缩代替SNAPPY,但是性能比SNAPPY差很多
- HQL队列拥挤:可以参考队列抢占式资源调度策略,对小任务支持更好
- HIVE作为数据仓库/交互式查询的优秀手段之一,是否有更好的计算框架可以替代:EMR SparkSQL可以替代大部分HIVE应用场景,并且3.22版本relational cache带来了极强的性能优化。推荐使用
总结
HIVE本身确实是数据仓库和交互式查询的优秀框架,但随着数据的增多,join的复杂度和性能问题,需要花时间和精力解决性能优化的问题。除了基于HIVE本身优化,还可以接入计算性能更好的框架,SparkSQL relational cache对使用者透明,开发不需要关心底层优化逻辑,可以将更多精力放入业务设计开发中。后续将针对SparkSQL部分提供个人经验供参考。
欢迎对EMR及相关技术感兴趣的同学进钉钉群一起讨论 :)