强化学习的主要目的是研究并解决机器人智能体贯序决策问题。尽管我不喜欢直接把定义硬邦邦、冷冰冰地扔出来让大家被动接受,可还是免不了要在这里猛然给出“贯序决策”这么专业的词汇。不过马上,我们就通过例子把这个词汇给大家解释清楚~本文选自《白话强化学习与PyTorch》一书。

既然大家要么是程序员,要么正走在程序员养成的路上,要么正看着其他人走在程序员养成的路上,那么,按照程序员的思维来理解强化学习将会更加顺畅。
把“贯序决策”翻译成“白话”就是:强化学习希望机器人或者智能体在一个环境中,随着“时间的流逝”,不断地自我学习,并最终在这个环境中学到一套最为合理的行为策略。
在这样一个完整的题设下,机器人应该尽可能在没有人干预的情况下,不断根据周围的环境变化学会并判断“在什么情况下怎么做才最好”,从而一步一步完成一个完整的任务。这样一系列针对不同情形的最合理的行为组合逻辑,才是一个完整的策略,而非一个简单而孤立的行为。

没错,这就是强化学习要研究并解决的问题。我想,可能已经有一些爱动脑筋的读者在心中暗暗反驳我了:这类问题一定要用强化学习来解决吗?我怎么觉得不用强化学习也能解决呢?
既然产生了这样一个争议,那我们先不去想是否一定要用人工智能这么“高大上”的工具来解决这类问题,而去想想自己以前有没有处理过类似的问题。如果一时想不起来,也没关系,请跟我看一个例子。

为了简化问题,假设我所在城市的道路是横平竖直的,各街区的边长相等。
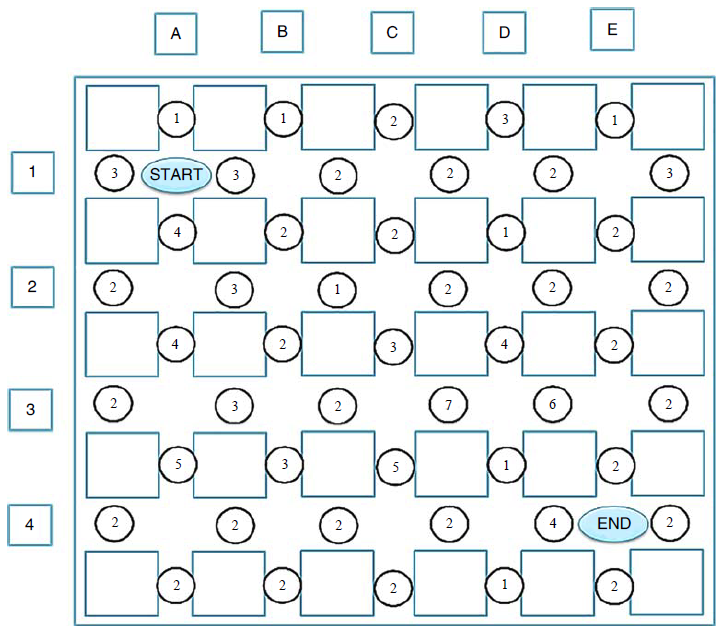
导航问题
外侧的边框表示城墙,车辆无法通过。中间的方块表示街区,街区和街区之间就是道路。为了称呼方便,我们用英文字母A~E 来标记纵向的道路,用数字1~4 来标记横向的道路,并约定A 大街和1 大街交汇处的坐标为A1(也就是START 处)。圆圈中的数字表示我们用GPS 或者其他手段测算出来的当前道路的拥堵程度,1 表示通畅,9 表示拥堵,也可以具象地将圆圈中的数字理解为通过某段道路需要1 分钟到9 分钟不等——总之,怎么理解简单怎么来。
现在,我准备从START处去往END 处,我需要一个“智能”的软件为我导航。这个问题难吗?如果你接触过与数据结构相关的课程,那么你一定会觉得这是一个非常简单的问题——就是图论里的图遍历问题或者树遍历问题。
该导航软件预设不会给出走回头路的方案(以免进入死循环)。以START 处为起点,我可以向上、下、左、右各走一个街区的距离:向左和向上走会到达城墙,不能再走;向右走到B1 处,有三条路可以走;向下走到A2 处,还有三条路可以走。所以,如果把这个问题当作一个树遍历问题,树的前两层应该非常容易构建出来。
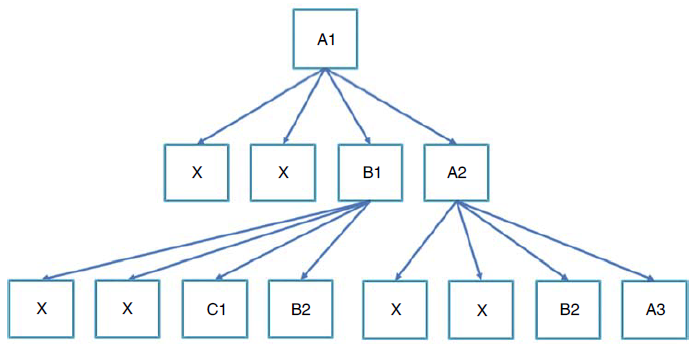
地图树遍历
上图中:X 表示走回头路或者“撞墙”,这样的路是不能走的,其下面的树结构也就不存在了;A1、B1 等交汇位置的节点则表示该处可以前往,并标注了该处之后的走法。这样一层一层往下标,最多能标出多少层呢?不清楚,要仔细算算才能知道。但可以确定的是,只需要8 层就可以完成从START 处(A1)到END 处(E4)的行进,而且走法不止一种。
任意列举几条路线:
A1→B1→C1→D1→E1→E2→E3→E4
A1→B1→C1→D1→D2→D3→D4→E4
A1→B1→C1→C2→C3→C4→D3→E4
……
我们不仅可以把这些路线一一列举出来,还可以把经过每条路线所花费的时间算出来(对一条路线的时间成本做一下简单的加法运算就可以了)。以路线A1→B1→C1→D1→E1→E2→E3→E4 为例,时间成本为 3 + 2+2+2 + 2 + 2+2 = 15,也就是说,从START 处(A1)到END 处(E4),走这条路线需要15 分钟。
如果想找到最短的路径,只要遍历路线,计算每条路线的成本,把成本最低(或者说耗时最短)的路线挑出来就可以了。这个思路再简单不过,可以保证在当前状态下是最优解——只要不出现走到半路突然发生交通事故,使得原本通畅的道路变得拥堵,或者原本拥堵的情况突然得到缓解。

第一,我们很容易用一种“智能”的方法得出这种问题的最优解,并向用户推荐这个最优解。之所以说它“智能”,是因为它确实自动实现了路程规划和推荐,挑选的是成本最低的路径。但是,在这个过程中,我没有用到任何机器学习的知识,也没有遇到任何需要通过样本学习来生成模型、确定待定系数的问题。我只用计算机专业本科一年级所学的一些基础知识就已经获解了,完全没有用到人工智能的方法——好意思叫“智能”吗?
第二,这是不是一个贯序决策问题呢?是或者不是,这也是一个问题。我想,可能会有两方面的意见。
认为这不是贯序决策问题的读者,会觉得这里面根本没有决策问题,而是纯粹的树遍历问题——非常不聪明,非常不智能,这哪里这是什么贯序决策问题!
树遍历
认为这是贯序决策问题的读者会觉得:从起点前往终点,中途在任何一个可以选择路径的位置都进行了判断,而且每次都选择沿着最好的路线前进——是的,“最好”,没有“之一”——在每个环节都进行了选择,这难道不是贯序决策问题吗?
两方的意见,我觉得都有道理。我不是一个喜欢咬文嚼字的人,也不想拿着什么金科玉律去说教。问题就摆在这里,我们要考虑的是:用什么样的方法解决问题才是合理的。
这个导航问题,在我看来,还真可以算作贯序决策问题。第一,它“够贯序”,因为它是由一系列决策判断组合而成的一个完整的行车路径策略;第二,它“有决策”,因为在每个十字路口都有很多选择,我需要充分的理由来决定要走哪一边。这两点是事实,对不对?
或许有些读者很失望——为什么要讲这么简单的例子?我只是希望大家能通过一个简单的例子明白一个道理:数学问题不一定非要通过极为艰深的算法和技术来解决,很多时候就是“小药治大病”,如果能用简单的方法解决问题,确实没有必要摆弄那些复杂的算法。反之,为了解决一个简单的问题而引入一大堆复杂的问题,在我看来,不是一种值得提倡的思考和处理方式。在解决具体的落地问题时,要尽可能选择复杂度可控、难度低、理论成熟的方法。像上文中这么特殊的贯序决策问题,在一定的限制条件下就会“退化”成搜索问题或遍历问题。所以,别犹豫,我们本来就应该用简单的方法去解决简单的问题。
结论已经很清晰了,刚刚这个问题就是一个贯序决策问题,只不过它是一个特例。那么,更为普适的贯序决策场景是什么样的呢?这个问题好,我们不妨想想看。
如果街区不是只有A~E 这5 条纵向的大道和1~4 这4 条横向的大道呢?如果有100 条横向的大道和100 条纵向的大道,这棵遍历树会有多“高”呢?应该最少要走198 条路才能到达,也就是一棵199 层的遍历树——这是非常可怕的!甚至,在很多场景中,我们很可能无法估算具体的层数。除此之外,如果我们不清楚每条路的拥堵情况,该怎么办呢?如果我们不能明确量化通过每条路预计需要多少分钟,该怎么办呢?
通过一系列科学的方法,对这类普适性问题进行体系性的求解方式和方法的归纳,才是这么多强化学习算法要解决的核心问题。


本书以“平民”的起点,从“零”开始介绍深度学习的技术与技巧,让读者有良好的带入感和亲近感,并通过逐层铺垫,把学习曲线拉平,使得没有学过微积分等高级理论的程序员朋友一样能够读得懂、学得会。同时,本书配合漫画插图来调节阅读气氛,并在每个原理讲解的部分都提供了对比和实例说明,相信每位读者都能有轻松、愉悦的阅读体验。

![强化学习从基础到进阶–案例与实践[11]:AlphaStar论文解读、监督学习、强化学习、模仿学习、多智能体学习、消融实验](https://ucc.alicdn.com/fnj5anauszhew_20230630_23c6ebb7a44c4507999e9d704e5eaee4.png?x-oss-process=image/resize,h_160,m_lfit)