一.简述
Apache HBase是基于Apache Hadoop的面向列的NoSQL数据库,是Google的BigTable的开源实现。HBase是一个针对半结构化数据的开源的、多版本的、可伸缩的、高可靠的、高性能的、分布式的和面向列的动态模式数据库。
Apache Hadoop是一个高容错、高延时的分布式文件系统和高并发的批处理系统,不适用于提供实时计算,而 HBase 是可以提供实时计算的分布式数据库,数据被保存在 HDFS (分布式文件系统)上,由 HDFS 保证其高容错性。
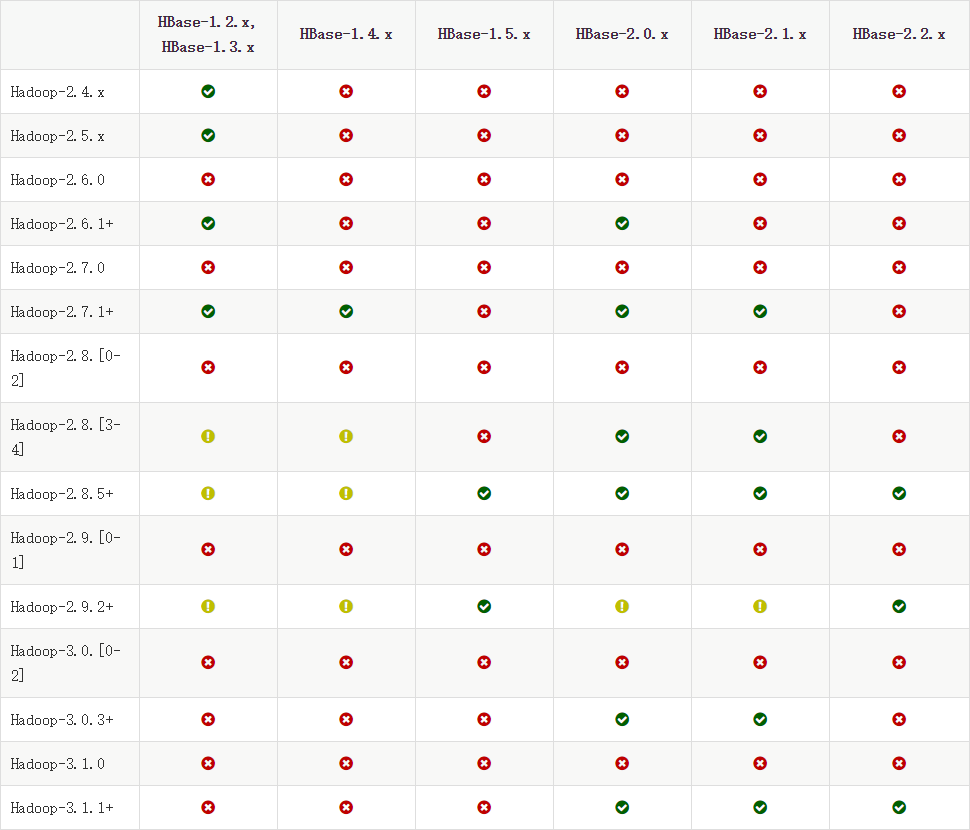
HBase与Hadoop适配
数据模型
hbase在表里存储数据使用的是四维坐标系统,依次是:行健,列族,列限定符和时间版本。 hbase按照时间戳降序排列各时间版本,其他映射建按照升序排序
- 表(Table): HBase采用表来组织数据,表由许多行和列组成,列划分为多个列族
- 行(Row): 在表里面,每一行代表着一个数据对象。每一行都是由一个行键(Row Key)和一个或者多个列组成的。行键是行的唯一标识,行键并没有什么特定的数据类型,以二进制的字节来存储,按字母顺序排序
- 列(Column): 列由列族(Column Family)和列限定符(Column Qualifier)联合标识,由“:”进行间隔,如 family:qualifiero
- 列族(Column Family): 定义 HBase 表的时候需要提前设置好列族,表中所有的列都需要组织在列族里面。列族一旦确定后,就不能轻易修改,因为它会影响到 HBase 真实的物理存储结构,但是列族中的列限定符及其对应的值可以动态增删
- 列限定符(Column Qualifier): 列族中的数据通过列限定符来进行映射。列限定符不需要事先定义,也不需要在不同行之间保持一致。列限定符没有特定的数据类型,以二进制字节来存储
- 单元(Cell): 行键、列族和列限定符一起标识一个单元,存储在单元里的数据称为单元数据,没有特定的数据类型,以二进制字节来存储
- 时间戳(Timestamp): 默认情况下,每一个单元中的数据插入时都会用时间戳来进行版本标识
RegionServer拆分原理
RegionServer在拆分前后通知Master,更新.META;RegionServer会保留有关执行状态的内存日记,以便发生错误时启用回滚
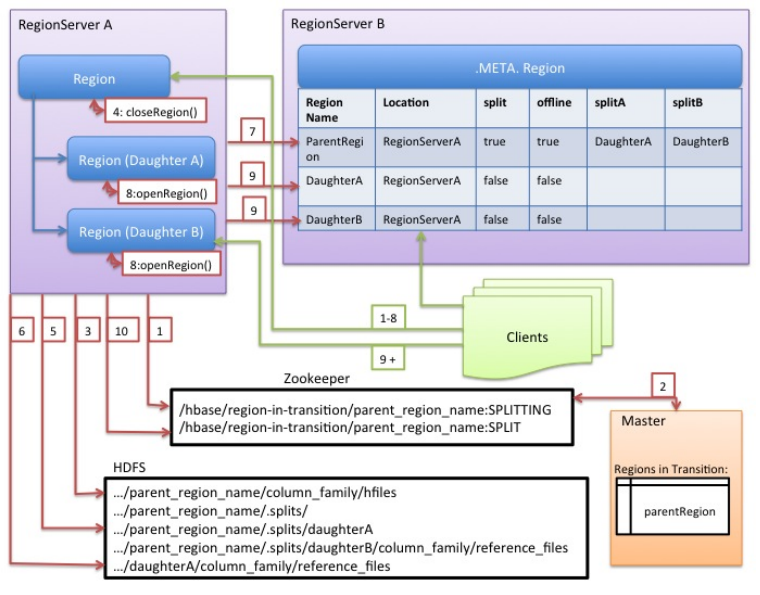
- RegionServer在本地决定拆分region,并准备拆分。RegionServer获取表上的共享读锁,以防止在拆分过程中修改模式。然后它在zookeeper在下/hbase/region-in-transition/region-name创建一个znode,并将znode的状态设置为SPLITTING
- Master监控znode,因为它有一个父region-in-transitionznode 的观察者
- RegionServer在HDFS中的父级region目录下创建名为.splits的子目录
- RegionServer关闭父region,并在其本地数据结构中将该region标记为脱机。此时,将发送到父region的客户端请求NotServingRegionException
- RegionServer在.splits目录下为子region A和B创建region目录,并创建必要的数据结构。然后它会分割存储文件,因为它会在父region中为每个存储文件创建两个参考文件
- RegionServer在HDFS中创建实际的region目录,并移动每个子项的参考文件
- RegionServer向.META表发送Put请求,在.META表中将父级设置为脱机,并添加子region信息
- RegionServer并行打开子region A和B
- RegionServer将子region A和B,以及托管region信息添加到.META表中
- RegionServer将/hbase/region-in-transition/region-name目录下,ZooKeeper的znode更新为state SPLIT
- 拆分完成后,.META表和HDFS仍将包含对父region的引用,当子region中的压缩重写数据文件时,将删除这些引用;Master的垃圾收集任务定期检查子region是否仍引用父region的文件
Regions层次结构
|- Table ———————— [HBase 表]
|- Region ———————— [HBase 表的 Regions]
|- Store ———————— [存储 Region 的每个 ColumnFamily]
|- MemStore ———————— [存储 Store 的每个 MemStore]
|- StoreFile ———————— [存储 Store 的每个 StoreFile]
|- Block ———————— [存储 StoreFile中的每个 Block]Region的状态转换
HBase在 hbase:meta 中管理着每个Region的状态,而hbase:meta在Zookeeper中持久存在
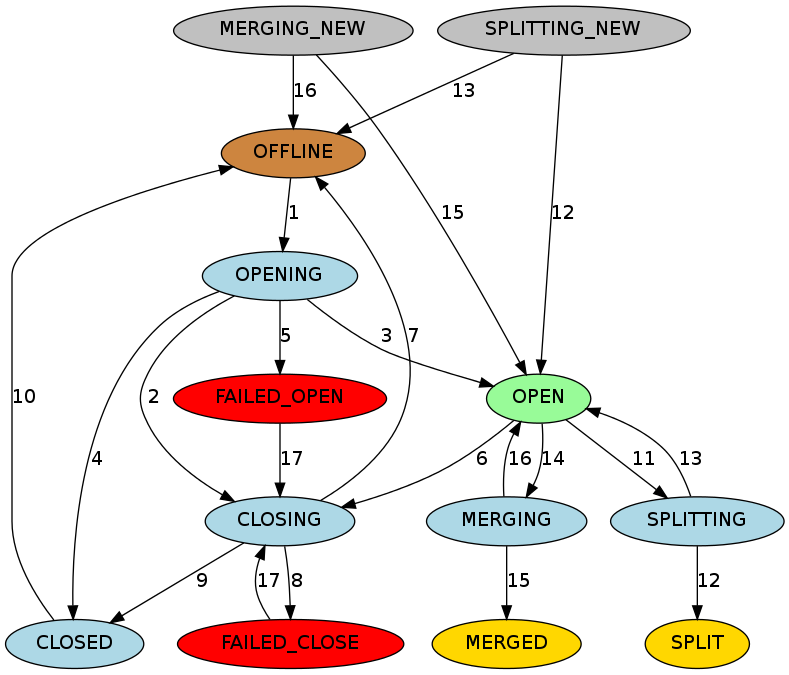
- OFFLINE : Region处于脱机状态且未打开
- OPENING : Region正在被开放
- OPEN : Region已打开且RegionServer已通知Master
- FAILED_OPEN : RegionServer无法打开Region
- CLOSING : Region正处于关闭状态
- CLOSED : RegionServer已关闭Region并通知Master
- FAILED_CLOSE : RegionServer无法关闭Region
- SPLITTING : RegionServer通知Master该Region正在拆分
- SPLIT : RegionServer通知Master该Region已完成拆分
- SPLITTING_NEW : Region是由正在进行的拆分创建
- MERGING : RegionServer通知Master该Region正在与另一个Region合并
- MERGED : RegionServer通知Master该Region已合并
- MERGING_NEW : 该Region是由2个Region合并而成
二.常用命令
Ⅰ).查询服务器状态
statusⅡ).查询版本号
versionⅢ).namespace
namespace命名空间指对一组表的逻辑分组,类似RDBMS中的database; HBase系统默认定义了两个缺省的namespace
hbase:系统内建表,包括namespace和meta表
default:用户建表时未指定namespace的表都创建在此
a).创建namespace
create_namespace 'namespace_name'b).删除namespace
drop_namespace 'namespace_name'c).查看namespace
describe_namespace 'namespace_name'd).列出所有namespace
list_namespacee).namespace下创建表
create 'namespace_name:table_name', 'ColumnFamily_name'f).列出所有namespace
list_namespaceⅣ).table
a).列出所有table
listb).创建table
create 'table_name', 'ColumnFamily_name'c).禁用table
disable 'table_name'd).查看table是否被禁用
is_disabled 'table_name'e).启用table
enable 'table_name'f).查看table是否启用table
is_enable 'table_name'g).查看table描述和修改
describe 'table_name'h).修改table属性
alter 'table_name', NAME => 'ColumnFamily_name', VERSIONS => 3i).插入数据
put 'table_name','row1','ColumnFamily_name:column_name','value'j).get读取数据
describe 'table_name'k).查看table描述和修改
## 读取指定行
get 'table_name','row1'
## 读取指定列
get 'table_name','ColumnFamily_name:column_name'l).scan扫描数据
scan 'table_name'm).统计数据
count 'table_name'n).清空table数据
此命令将禁止、删除、重新创建一个表
truncate 'table_name'o).删除table
## 禁用table
disable 'table_name'
## 删除table
drop 'table_name'
drop_all 'table_name*'p).删除指定列族
alter 'table_name',{NAME=>'ColumnFamily_name',METHOD=>'delete'}q).删除指定行
delete 'table_name','row1','ColumnFamily_name:column_name'Ⅴ).导入导出数据
## 导入数据
hbase org.apache.hadoop.hbase.mapreduce.Driver import table_name /hdfspath
hbase org.apache.hadoop.hbase.mapreduce.Import table_name /hdfspath
## 导出数据
### 1.导出数据到HDFS
hbase org.apache.hadoop.hbase.mapreduce.Export -D mapred.output.compress=true table_name /hdfspath
hbase org.apache.hadoop.hbase.mapreduce.Driver export table_name /hdfspath
-D mapred.output.compress=true 输出压缩
-D mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec 压缩方式
-D mapred.output.compression.type=BLOCK 按块压缩
-D hbase.mapreduce.scan.column.family=<familyName> 列簇
-D hbase.mapreduce.include.deleted.rows=true
-D hbase.mapreduce.scan.row.start=<ROWSTART> 开始rowkey
-D hbase.mapreduce.scan.row.stop=<ROWSTOP> 终止rowkey
-Dhbase.client.scanner.caching=100 客户端缓存条数
-Dmapred.map.tasks.speculative.execution=false
-Dmapred.reduce.tasks.speculative.execution=false
-Dhbase.export.scanner.batch=10 批次大小
### 2.过滤导出数据
echo "scan 'namespace_name:table_name',{COLUMNS => 'ColumnFamily_name:column_name',ROWPREFIXFILTER => '****',FILTER=>\"SingleColumnValueFilter('ColumnFamily_name','column_name',=,'regexstring:null')\"}" | hbase shell > export_file_name.txt## CopyTable是Hbase提供的一个数据同步工具,可用于同步表的部分或全部数据。CopyTable通过运行一个map-reduce任务从源表读出数据再写入到目标表
hbase org.apache.hadoop.hbase.mapreduce.CopyTable -Dhbase.client.scanner.caching=200 -Dmapreduce.local.map.tasks.maximum=16 -Dmapred.map.tasks.speculative.execution=false --peer.adr=hostname:2181/hbase table_name## distcp是Hadoop提供的用于复制HDFS文件的工具,可用于同步HBase数据
## 1.停止写入数据
## 2.数据copy到目标集群
hadoop distcp source_hdfs_file_path distination_hdfs_file_path
## 3.目标集群执行
hbase hbck -fixAssignments -fixMeta## HBase snapshot对region-server影响很小的情况下创建快照、然后复制到目标集群
## 1.源表上创建snapshot
hbase snapshot create -n snapshort_table_name -t table_name
## 2.snapshot拷贝到目标集群的HDFS
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot snapshort_table_name -copy-from snapshort_hdfs_path -copy-to distination_hdfs_pathⅥ).权限管理
a).分配权限
## 语法 : grant <user> <permissions> <table> <column family> <column qualifier> 参数后面用逗号分隔
## READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')
grant 'user_name','RWC','table_name'b).查看权限
## 语法:user_permission <table>
user_permission 'table_name'