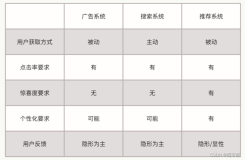
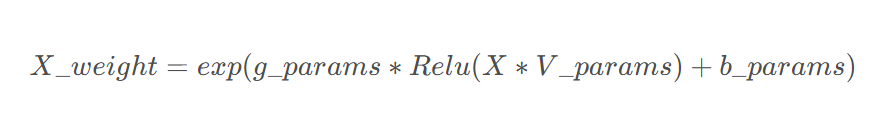小叽导读:推荐系统如果“佛系”,用户就无法用更短时间找到想要的“宝贝”。为了提升用户的使用感受,提升推荐点击效率,推荐系统不能“佛系”。利用用户行为挖掘用户潜在兴趣已经成为推荐系统和在线广告预估系统中重要的环节。从2016年开始,阿里精准定向广告团队就开始在用户兴趣提取方向做了很多工作,并取得了一定进展。本篇论文已被 KDD 2019 收录,建议大家收藏阅读。
作者 | 皮琪、卞维杰、周国睿、朱小强、盖坤
背景
阿里精准定向广告团队最开始观测到用户存在多样的兴趣,在面对具体商品时只有部分兴趣会影响用户行为,于是提出了DIN[1]网络。为了提取用户抽象的兴趣表达,并捕捉到用户兴趣演化信息,我们提出DIEN[2]模型。无论是DIN还是DIEN受到在线系统的性能压力,用户行为长度只利用了50。更多丰富的行为数据能提供更多的信息,但同时也会给在线带来更大的压力。于是我们从算法和系统co-design视角提出了解决方案。
在算法端,我们借鉴了Memory Network的思路,提出了新一代CTR预估模型MIMN (Multi-channel user InterestMemory Network) 。MIMN阅读用户的超长行为序列,从中提取和归纳用户的多样化兴趣,并沉淀到记忆网络中。在系统端,我们单独设计了一个独立UIC模块来负责用户兴趣计算。让用户兴趣计算和广告请求解耦。UIC+MIMN框架在阿里巴巴精准定向展示广告场景取得显著效果。
基于历史行为数据挖掘用户潜在兴趣,已经成为CTR预估建模的重要部分。兴趣建模领域不断涌现出新的算法,他们在离线的实验环境下验证了有效性,但是大部分的方法都面临实际工业落地的巨大挑战。工业界大部分服务都是实时响应,例如点击率预估服务,就面临着高并发的请求,且需要在极短的时间内完成响应。在面对较长的用户行为序列数据时,现有兴趣建模算法的在线推理模块均面临延时和存储等方面的压力。
当前工业界主流的CTR预估技术能够建模的用户序列长度普遍在100以内。但在阿里电商场景下,用户的行为非常丰富,用户仅60天的平均行为长度就超过了1000,这些数据蕴含了非常丰富的信息。我们统计出不同天数用户平均行为长度,同时实验不同长度用户行为引入CTR预估模型的离线表现,如图一。我们采用简单的DNN模型利用1000长度用户行为信息相比100长度,能够带来0.6%AUC的提升。其中0.6%离线提升对在线业务有重大意义。

为了解决上述挑战,本文从算法和系统co-design的角度设计了全新的建模方案。
算法端:我们借鉴了Memory Network的思路,提出了新一代CTR预估模型MIMN (Multi-channel user InterestMemory Network) 。MIMN阅读用户的超长行为序列,从中提取和归纳用户的多样化兴趣,并沉淀到记忆网络中。此外,MIMN设计了内存利用正则,可以有效地提高记忆存储的利用率;同时MIMN引入了兴趣归纳结构,可以捕捉用户不同兴趣轨道的演化;
系统端:我们单独设计了一个独立UIC模块来负责用户兴趣计算。UIC模块的更新计算由用户实时的新增行为触发,与广告点击率预估计算异步进行。
本文提出的MIMN+UIC的co-design解决方案打破了行为序列长度对用户兴趣建模技术的瓶颈制约。在阿里巴巴的展示广告场景,我们实现了对1000以上的超长用户行为序列建模,该技术已经实际部署到生产系统,取得了显著的在线效果提升。
系统端——实时CTR预估系统
图二(A)展示了当前阿里巴巴展示广告业务的实时预估系统框架。CTR预估系统需要在严格时间限制下,返回候选集预估点击概率。

在工业界电商推荐领域,用户行为贡献了大量存储,在我们系统中90%存储都为用户行为。引入较长的用户行为序列会占用更多存储空间。推荐系统为能够保持低耗时高吞吐,用户行为数据会存储在分布式存储系统(例如阿里的TAIR)。但这样的分布式存储系统很昂贵,难以承受海量数据。如果继续采用序列建模的思路,超长用户行为数据会带来更大挑战。我们利用DIEN模型结构对1000长度用户行为进行建模,在500QPS下耗时200ms,这对阿里巴巴展示广告场景业务难以接受。因此直接利用现有的系统和模型来建模长期用户行为序列的方案不可行。
为解决上述挑战,在系统部分我们设计了一个独立的UIC模块来处理用户兴趣计算。图二(B)引入了UIC模块,重新设计了RTP系统。图二(A)和图二(B)的不同在于用户兴趣计算部分。在图二(B)中,UIC服务提供用户最新的兴趣状态表达。其中用户的兴趣状态随新增的行为发生变化,而与点击率预估请求解耦。因此用户的兴趣推断计算可以在实时计算点击率前完成。所以UIC模块对于CTR预估打分服务是不耗时的。
算法端—多轨道用户兴趣记忆网络
长序列数据建模是众所周知的算法难题。由于简单RNNS网络(RNN,GRU,LSTM) 难以建模较长的序列数据,于是Attention 结构被引入进来增强长序列数据的表达。但是在实际计算的时候,RNN+Attention的结构需要存储所有的历史行为数据,会给在线系统带来很大的存储压力。
我们借鉴了NTM的memory建模思路提出了MIMN模型。得益于memory结构的精巧性,MIMN模型可以增量化运行,它实现在UIC模块中,对在线实时服务是友好的。尽管UIC存储了抽象的向量来代替原始用户行为,但是考虑到存储压力,memory的大小是有限的。因此,我们设计了内存利用正则,可以有效地提高记忆存储的利用率;同时引入了兴趣归纳结构,可以捕捉用户不同兴趣轨道的演化。
为了有效提高memory利用率,我们提出memory utilization regularization,希望约束不同memoryslot中的写入方差。 表示从1到t时刻的写入权重和。其中
表示从1到t时刻的写入权重和。其中 表示的是在c时刻改写后的写入权重。
表示的是在c时刻改写后的写入权重。

改写权重的计算方式如下:



M表示slot的数量, 能够减少不同memory slot利用率的方差。
能够减少不同memory slot利用率的方差。
NTM算法memory通常用来存储原始数据信息,遗失了对于更高阶的信息的捕捉。为了能更好捕捉用户兴趣,MIMN设计了Memory Induction Unit (MIU)来捕捉用户兴趣演化。MIU中将每个memory slot视为一个用户兴趣轨道。在t时刻MIU选择K个兴趣轨道进行演化,每个轨道采用GRU结构来进行演化计算。

其中 是原始兴趣memory的记录,
是原始兴趣memory的记录, 是行为embedding向量不同于利用attention的结构来捕捉用户表达,MIMN不需要利用广告来捕捉相关用户兴趣,而是利用额外的memory来存储和挖掘用户多样兴趣。基于memory模型框架能对于用户兴趣进行增量更新,使得对序列行为建模长度无限制。
是行为embedding向量不同于利用attention的结构来捕捉用户表达,MIMN不需要利用广告来捕捉相关用户兴趣,而是利用额外的memory来存储和挖掘用户多样兴趣。基于memory模型框架能对于用户兴趣进行增量更新,使得对序列行为建模长度无限制。
MIMN的在线实现如图三,MIU和NTM部分的计算在UIC server中实现。当有新的用户行为到达后UIC会增量计算用户兴趣,并将其更新到TAIR。广告请求到达后,会从TAIR中直接取出用户兴趣表达用于CTR预估计算。

实验
我们在Amazon(书籍类)和淘宝公开数据集以及阿里妈妈精准展示广告的生产数据集上进行了详细的实验,验证了UIC&MIMN co-design的有效性。用到的数据规模如下:

公开数据集实验:
我们在亚马逊数据集中书籍类目进行实验,训练集和测试集按照user随机划分(即测试集的user不会出现在训练集中)。将user写过的review按照时间进行排序,使用前T-1次的review来预测T次Review是否会发生。淘宝数据集也是相同处理方式,采用前T-1次点击来预测用户T次点击。实验结果如下:

对于所有的模型,我们都是采用Adam的优化方式,初始学习率为0.001. embedding的dim设置为16。
生产数据集实验:

生产数据集我们使用49天的广告展示和点击样本作为训练集,接下来一天作为测试集。除了MIMN,其他则使用用户前14天历史行为作为序列建模输入。MIMN采用用户前60天行为数据并做了1000长度截断。
在生产数据集上,我们只和当前生产最好的模型DIEN对比,离线能够提升1%。
生产化:
我们将MIMN&UIC架构部署到阿里巴巴展示广告业务中,相比于我们生产环境最好的模型DIEN 在线CTR提升7.5%,RPM提升6%。得益于UI架构使得复杂的MIMN算法结构得以上线,在线吞吐和耗时的性能相比DIEN都有提升。如图四:

除此之外,我们模型上线的过程遇到了很多困难并将其总结成经验。
UIC server和RTPserver模型参数同步问题
MIMN算法是由两部分组成,一部分是用户兴趣提取,一部分是CTR预估,在线计算会涉及到UIC 和RTP两组服务。因此会存在模型参数同步的问题,在表三中我们做了相关实验,证明UIC和RTP server 模型参数相差一天,对于模型离线效果无影响。我们系统是采用增量训练的方式,每小时就会更新模型参数,会大幅降低参数不一致风险。
大促数据影响
电商场景经常存在大促,比如最出名的双十一促销。在这样的情况下,数据的分布和用户行为与平时存在很大的差异。我们对比了引入促销时期用户行为刻画用户兴趣。从表三里可以看出,离线效果有0.2%的下降。
初始化策略
尽管UIC可以增量计算用户行为,但是累计用户长时间行为会耗时严重。于是我们设置了一个初始化机制。将模型学习到的用户120天行为的兴趣表达导出,放入TAIR作为初始化。
回滚机制
为了防止线上出现故障,例如行为数据被污染,带来的在线效果问题。我们设置了断点保存机制,将每天零点的用户兴趣状态导出到离线存储。出现故障后,加载最近的离线存储。
论文原文下载地址:
https://arxiv.org/abs/1905.09248
参考资料:
[1]Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 1059-1068.
下载地址:https://arxiv.org/abs/1706.06978
[2]Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. In Proceedings of the 33nd AAAI Conference on Artificial Intelligence. Honolulu, USA.
下载地址:https://arxiv.org/abs/1809.03672