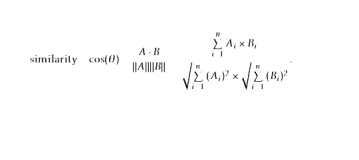小叽导读:13年 Word2vev 横空出世,开启了基于 word embedding pre-trained 的 NLP 技术浪潮,6年过去了,embedding 技术已经成为了 nn4nlp 的标配,从不同层面得到了提升和改进。今天,我们一起回顾 embedding 的理论基础,发现它的技术演进,考察主流 embedding 的技术细节,最后再学习一些实操案例。
从实战角度而言,现在一般把 fastText 作为 word embedding 的首选,如果需要进一步的上下文信息,可以使用 ELMo 等 contextual embeddings。从18年开始,类似 ULMFiT、Bert 这样基于 pre-trained language model 的新范式越来越流行。
Sentence embedding 方面,从15年的 Skip-Thought 到18年的 Quick-Thought,无监督 pre-trained sentence embedding 在工业界越来越多的得到使用。

技术点脑图如下:

Vector Semantics
词语义从语言学角度讲可以细分为不同方面:
- 同义词 (Synonyms): couch/sofa, car/automobile
- 反义词 (Antonyms): long/short, big/little
- 词相似性 (Word Similarity):cat 和 dog 不是同义词,但是它们是相似的。
- 词相关性 (Word Relatedness):词和词之前可以是相关的,但不是相似的。coffee 和 cup 是不相似的,但是它们显然是相关的。
语义域/主题模型(semantic field/topic models LDA): 一些词同属于某个 semantic domain,相互之间有强相关性,restaurant(waiter, menu, plate, food, chef),
house(door, roof, kitchen, family, bed)
语义框架和角色(Semantic Frames and Roles): 一些词同属于某个事件的角色,buy, sell, pay 属于一次购买的不同角色。
上/下位词(hypernym/hyponym):一个词是另一个词的父类叫上位词(hypernym),反之叫下位词(hyponym), vehicle/car, mammal/dog, fruit/mango。
- 情感/情绪/观点/评价词(connotations, emotions, sentiment, opinions):正负向情绪词happy/sad,正反向评价词(great, love)/(terrible, hate)。
一个完美的 Vector Representation 是希望能刻画上面词语义的各个层面,但是显然是不现实的。到目前为止用于表示词语义最成功的模型是 Vector Semantics,它是 word embedding 技术的基础。Vector Semantics 有两部分组成:
- distributional hypothesis(所有语义向量的理论基础):Words that occur in similar contexts tend to have similar meanings,define a word by its distribution in texts。
- defining the meaning of a word w as a vector, a point in N-dimensional semantic space, which learns directly from their distributions in texts.
使用 Vector 表示词语义,可以更加方便地计算 word similarity。
Co-occurrence Matrix and Basic Vector Semantics models
Vector Semantics Models 通常基于共现矩阵(co-occurrence matrix)构建,共现矩阵用来表示元素的共现规律,其实就是上文提到的 distributional hypothesis 的具体实现。根据元素的不同,主要有两种 co-occurrence matrix:Term-document matrix(多用于检索)和 word-word matrix (多用于词嵌入)。
■ Term-document matrix and TF-IDF model
Term-document matrix:每一行是 vocabulary 中的一个词,每一列是文章集合中的一篇文章,每一个值代表该词(row)在该文章(column)中出现的次数。文章就可以表示成 column vector,两篇文章出现的词类似一般比较相似(all sports docs will have similar entries):

Term-document matrix 在信息检索中使用比较多,用于寻找相似文章,但是基础的 Term-document matrix 有一个问题,直接使用共现次数那些高频出现的无意义词(stopwords)会有很大的权重,所以需要引入 TF-IDF model。
TF-IDF(term frequency–inverse document frequency) 是 NLP 的基础加权技术,也是信息检索中主流的共现矩阵加权技术。它用于刻画一个词对于一篇文章的重要性,主要思想是某个词在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现,则认为此词具有很好的类别区分能力。公式如下:



所以可以改进 Term-document matrix 成 TF-IDF weighting matrix,抑制那些非常高频出现的无意义词(比如 good):

实战话外音:计算 corpus 的各个 tfidf 值,直观的思路是先统计构建 Term-document matrix 然后计算 TF-IDF weighting matrix。
■ Word-word matrix and PMI model
word-word matrix:和 Term-document matrix 类似,只是每一列变成 context word,每一个 cell 代表目标词(row)和 context 词(column)在语料中共现的次数。其中的 context 往往是这个词周围的一个窗口。word-word matrix 常常用于 count-based word embedding 的计算,能很好地捕捉 syntactic/POS 信息(小的 context 窗口)和 semantic 信息(大的 context 窗口):

点互信息(Pointwise Mutual Information, PMI)是 NLP 中最重要的基础概念之一,能有效刻画两个词之间是否强相关( strongly associated ),计算的是在语料库中两个词共同出现的次数多于我们先验期望它们偶然出现的概率:

实际中常使用下面的 Positive PMI(PPMI):

word-word co-occurrence matrix 可以改写成 PPMI matrix,使用下面的公式:

第一步把词共现次数改成下面的联合概率:

第二步计算 PPMI 值,PPMI matrix 能很好地刻画词和词之间的关联性:

基础的 PPMI 公式有一个问题,会给予低频词很大的 PMI 值(分母越小值越大)。一个常用的办法是微调 p(c) 的计算逻辑,从而缩小低高频词之间的概率差距,其中α=0.75:


关联思考:对于一个数字集合,softmax 是让大者更大,p(c) 是常规求概率,则是缩小大小数字之前的差距,下文会提到的 Negative sampling 技术也用到了这个。
用 word-word co-occurrence matrix 产生的 vectors 有几个问题,高纬度、稀疏和模型不鲁棒。简单的方式可以做 co-occurrence matrix 的奇异值分解 (Singular Value Decomposition) 获得 Low dense dimensional vectors:

代码示例:
U, s, Vh = np.linalg.svd(X, full_matrices=False)实战话外音:计算 corpus 中各个词对的 PMI 值,直观的思路是先统计构建 word-word matrix 然后转换成联合概率矩阵,最后计算 PPMI matrix,如果想要用 vector 可以用 SVD先降维。
Word Embeddings
基于TF-IDF 和 PPMI 的词向量是长而稀疏的,不利于存储和计算,现在常用的词向量是短而稠密的 Word Embeddings:
- short (length 50-1000)
- dense (most elements are non-zero)
Word Embeddings 基于 Vector Semantics 的理论基础:distributional hypothesis, a word’s meaning is given by the words that frequently appear close-by。
It should learn to encode similarity in the vectors themselves。词嵌入的编码目标是把词相似性进行编码,所有优化的目标和实际的使用都围绕在 similarity 上。
这里澄清两个术语:
- distributional representations: 代表了 distributional hypothesis 的思想,反面是类似 WordNet 地直接从独立的词构建关系。
- distributed representations:代表了词用 vector 表示,词含义分散在每个维度上,反面是 one-hot vector,只有一个离散的值。
Word2vec
最经典的词嵌入 Word2vec(Mikolov et al. 2013) 是一个计算词向量的框架,主要思想是:
- 准备一个非常大的文本语料 corpus;
- 每一个 vocabulary 中的词都表示成一个定长 vector;
- 遍历 corpus 中的每个位置为 t的词,center word 为 c,context words 为 o
- 基于词向量相似度,计算条件概率;
- 不断调整词向量来最大化这个条件概率。


■ Objective Function
Word2vec 的目标函数是 negative log likelihood:

训练目标是最小化objective function,条件概率使用cosine similarity加softmax转成概率分布:

其中o/c是vocabulary中的索引,根据c去预测o的概率是Word2vec的prediction function:

■ Train Word2vec
Word2vec 模型包含的可训练参数如下:

训练 Word2vec 需要计算所有 vector 的梯度:

计算的偏导,先进行分解原式为2个部分:

部分1推导:

部分2推导:

所以,综合起来可以求得,单词 o 和单词 c 的上下文概率对center向量的偏导:

可以看到优化目标是让实际 向量逼近所有可能 context vector 的期望向量。
实际训练的一些建议:
每个词对应两个 vector 是为了优化方便,最后把两个vector取平均作为最终的词向量;
原始 paper 有两种模型:
Skip-grams (sg):用中心词预测周围词,sg比cbow 能更好地处理生僻字。
Continuous Bag of Words (cbow):用周围词预测中心词,cbow比sg训练快。
softmax 里面的分母部分 normalization factor 计算非常耗时,paper 中使用Negative sampling,用 logistic regressions 训练一个二分类区分真实的(center word, context word)词对和随机采样构造的假的(center word, random non-context word)词对,公式如下:

改成和前文一致的 negative 形式:
k个负采样词服从概率分布 (Z指归一化)。修改词频概率分布
(Z指归一化)。修改词频概率分布 ,是为了提高低频词被采样到的可能性,和PMI章节的优化技术有异曲同工之妙。
,是为了提高低频词被采样到的可能性,和PMI章节的优化技术有异曲同工之妙。
实战话外音:训练 Word2vec,直观的思路是先从 corpus 中准备所有的词对包括有效的(c,o)和负采样到的(c,random),然后基于 cosine similarity 计算 loss function,再用 sgd 优化参数,最好把 center 和 context vectors 取平均作为最终的 embedding。
Other Improved Embeddings
■ GloVe: Count-based plus Prediction-based
Word embedding 的计算方式可以分成 count-based (PMI matrix) 和 prediction-based (Word2vec)。
两者各有优点,count-based 充分利用了全局统计信息,训练也比较快,而 prediction-based 更能胜任海量数据,能捕捉更多词相似性之外的pattern。
其实两者之间有很强的内在关联性,毕竟理论基础都是 distributional hypothesis,Skip-gram 模型的 center word matrices WW 和 context word matrices CC 点乘后的矩阵可以因式分解成 PMI matrix 减去一个和负采样数kk相关的常量(Levy and Goldberg 2014):

Stanford 提出的 GloVe vector 结合 count-based 和 prediction-based 方法的优点,核心观点是共现条件概率的比率能更显著体现词的相似性:

共现条件概率的比率可以表示成词向量空间的一个线性表示:

最后的loss function是:

关联思考:在有相互比较的场景中,很多时候具体的值意义不大,但是对比的 ratio更具统计意义。GloVe 的核心思想基础是这个,非常 strong 的 baseline tfidf 的优化版统计一个词对一个类别的重要性的特征提取算法NBSVM也是如此。
■ FastText:Sub-word Embeddings
前面的 Embedding 产生方式都忽略了词的词形变化,每个词都是独立的 vector,对于处理 OOV 无能为力。FastText 是 Skip-gram 的改进版,使用 sub-word 信息,每个词都会表示成 bag of character n-grams,最终的词向量是各个 gram embedding 的求和。
比如 where(n=3) 表示成加上词本身,<和>分别代表词的开始和结束,用于区分子序列的位子。n-grams 集合中,一般使用3-6的 n-grams,需要说明的是和 tri-gram 的 her 是不同的。FastText 的优点是训练速度非常非常快,效果比 Word2vec 好,同时也可以计算 OOV 词的词向量,可以作为项目启动的第一候选词向量。
Evaluating Embeddings
■ Intrinsic vs extrinsic
词向量评估分为内在评估(Intrinsic)和外在评估(extrinsic),外在评估需要放到各种下游任务中去看实际效果,使用方式有 fixed pre-trained,fine-tuned pre-trained,multichannel 或者 concatenation 等,详见 textcnn paper。内在评估主要有几种:
(1)Analogy:通过直观的语义类比问题评估,寻找 x 满足"a is to b, as x is to y"

(2)通过可视化评估,常用技术有 PCA 和 t-SNE(non-linear projection)

pca 和 t-SNE 的效果对比:

(3)Categorization: 对训练好的 embeddings 聚类,根据标准分类集合或者人工验证,看每个聚类类别的好坏。
■ When are Pre-trained Embeddings Useful?
简单来讲,当对特定任务的训练语料比较匮乏的时候更加有用,具体如下:
- 非常有用:tagging, parsing, text classification
- 不太有用:machine translation
- 基本没用:language modeling
Sentence Embeddings/Encoder
Sentence Embeddings 和 Word Embeddings 非常类似,训练方式也可以粗略分为基于纯统计的 bag-of-words models 和基于句子维度的 distributional hypothesis 的 NN models。Sentence Representation 的作用:
- Sentence Classification 文本分类的特征输入;
- Paraphrase Identification 判断段落是否相似;
- Semantic Similarity 两个句子语义是否相似;;
- Natural Language Inference Entailment/Contradiction/Neutral;
- Retrieval 基于句向量的相似性检索。
Baseline Bow Models
Sentence Embedding 句嵌入的基础模型可以是上面提到的类似 TF-IDF weighting matrix 的基于统计的词袋模型,也可以是基于词向量的词袋模型。词向量的加权方式一般遵循一个准则:越常见的词权重越小。这里简单介绍一种,SIF(Smooth Inverse Frequency),一个简单但有效的加权词袋模型,其性能超过了简单的 RNN/CNN模型。SIF 的计算分为两步:
- 对句子中的每个词向量,乘以一个权重
 ,其中 a 是一个常数(常取0.0001),p(w) 为全局语料中该词的词频,对于出现频率越高的词,其权重越小。
,其中 a 是一个常数(常取0.0001),p(w) 为全局语料中该词的词频,对于出现频率越高的词,其权重越小。 - 计算句向量矩阵的第一个主成分 u,让每个句向量减去它在 u 上的投影(类似 PCA);
完整算法流程如下:

SIF 移除了和句义不太相关的高频词和句法结构,保留了对句义信息贡献最大的部分。
Skip-Thought
Skip-Thought Vector 使用类似 Word2vec/ 语言模型的思想,Sentence Embedding作为模型的副产品。给定一个三元组 表示3个连续的句子。模型使用 Encoder-Decoder 框架,训练时,由Encoder对进行编码,然后分别使用两个Decoder生成前一句和下一句,如下图:

 的 Decoder 是给定条件(
的 Decoder 是给定条件( 的句子表示)的语言模型,每一个词的概率:
的句子表示)的语言模型,每一个词的概率:



Quick-Thought
Quick-Thought 是 Skip-Thought 的升级版,上面给定一句话生成上一句和下一句的任务,被重新描述为一个分类任务:Decoder 作为分类器从一组候选句子中选择正确的上一个/下一个句子。Skip-Thought 可以理解为生成模型:

Quick-Thought 则是一个分类模型:
Skip-Thought 会被训练成去重构目标句子的表层结构(词的具体组合形式),导致模型不仅仅学会了预测句子语义,同时也预测了和语义无关的句子具体组成形式。同样的语义句子的表达可以有很多种,甚至表层结构完全不相似,这样的句子 Skip-Thought 模型就会认为不相似。
Quick-Thought 则是把 loss function 直接定义在句子向量化后的语义空间,比Skip-Thought 直接定义在 raw data space 的效果更好,优化的目标更加聚焦。loss function 和 Skip-gram 模型类似,负采样之后,都是直接用 cosine similarity 定义相似度,用 softmax 归一化,只不过是多分类:

顶层分类器的简化,是为了让底层 encoder 更多地学到和语义有关的表征。It should learn to encode similarity in the vectors themselves。可以很清楚的看到,Quick-Thought 是一个通用的句向量学习框架,原文底层 encoder 使用的 GRU,也可以换成别的,比如 Transformer 来增加表征能力。在实际预测阶段,把底层两个encoder 的输出拼接在一起作为最终的句向量表示: 。
。
在我们实际工作中,也常用 Quick-Thought,因为它还有一个优点是训练速度比 Skip-Thought Vector 快很多,后者需要训练3个 RNN 模块。具体的一些实现细节:
- batch_size=400,即一个 batch 为400个连续的句子;
- context_size=3,即对给定句子,其上一句和下一句被认为是相似的(句子维度的distributional hypothesis);
- 负采样:同一 batch 中除上下文句子外,均作为负例,实验证明这样简单的策略和其他常见随机负采样等策略效果类似;
- 词向量或者整个 encoder 都可以使用 pre-trained,来加快训练速度。
Other Sentence Embeddings
上面提到的无监督通用句向量训练方式在工业界更加方便落地,学术界还有一些基于 supervised learning(InferSent) 和 multi-task learning(GenSen) 的句向量模型,性能能有一些提升,但是训练的数据并不是那么容易获得,一般可以使用迁移学习在工作中落地,这里简单介绍一下比较经典的几个。
■ InferSent (Facebook)
InferSent 使用有监督的方法,在自然语言推理 (NLI) 数据集上训练 Sentence Embedding。paper 也证明了从 NLI 数据集上训练得到的句向量也适合迁移到其他 NLP 任务中。
在 NLI 任务中,每个样本由三个元素构成 ——其中 u 表示前提(premise),v 表示假设(hypothesis),l 为类标(entailment 1, contradiction 2, neutral 3),每个样本的 u 和 v 的地位不是等价的。InferSent 的网络结构如下:
——其中 u 表示前提(premise),v 表示假设(hypothesis),l 为类标(entailment 1, contradiction 2, neutral 3),每个样本的 u 和 v 的地位不是等价的。InferSent 的网络结构如下:

sentence encoder 可以根据具体需求选择,底层共享 encoder,输入 premise 和hypothesis 分别输出句子表征 u 和 v,然后使用匹配模型中非常常见的3种方式抽取两者之前的关系:向量拼接 (u,v) element-wise 相乘 u∗v,element-wise 相减取绝对值|u−v|。最后是一个三分类分类器,预测对应 l 的值。
■ GenSen (Microsoft)
GenSen 的核心思想是为了能够推广到各种不同的任务,需要对同一句话的多个方面进行编码。简单来说,模型同时在多个任务和多个数据源上进行训练,但是共享相同的 Sentence Embedding。任务及数据集包括:
- Skip-Thought(预测上一句/下一句)—— BookCorpus
- 神经机器翻译(NMT)—— En-Fr (WMT14) + En-De (WMT15)
- 自然语言推理(NLI)—— SNLI + MultiNLI
- Constituency Parsing ——PTB + 1-billion word
基础模型和 Skip-Thought Vector 类似,Encoder 部分为了速度使用 Bi-GRU,而Decoder 部分完全一致。
SemAxis: Synonym Expansion
训练获得 pre-trained 的词向量或者句向量之后,一个直接的应用是通过向量相似度来寻找近义词/近义句。这里介绍一种简单有效的近义词扩展方法 SemAxis (ACL 2018):
- 准备 pre-trained 词向量;
- 在词向量空间中,通过语义种子词词向量计算 semantic axis vector,
 代表正向词,
代表正向词, 代表负向词:
代表负向词:

在词向量空间中,映射其他词词向量 到计算的 semantic axis
到计算的 semantic axis 上:
上:

方法示意图如下:

在我们实际工作中用来扩展情感词效果如下,圈起来的是种子词,其他为扩展的:

Reference:
Books and Courses
Jurafsky, Dan. Speech and Language Processing (3rd ed. 2019)
CS224n: Natural Language Processing with Deep Learning, Winter 2019
CMU11-747: Neural Nets for NLP, Spring 2019
Goldberg, Yoav. Neural Network Methods for Natural Language Processing. (2017)
Word Embedding Papers
Tomas Mikolov, et al.: Efficient Estimation of Word Representations in Vector Space, 2013. (original Word2vec paper)
Tomas Mikolov, et al.: Distributed Representations of Words and Phrases and their Compositionality, NIPS 2013. (negative sampling paper)
Bojanowski, Piotr, et al. "Enriching word vectors with subword information." Transactions of the Association for Computational Linguistics 5 (2017): 135-146. (original fastText paper)
Jeffrey Pennington, et al.: GloVe: Global Vectors for Word Representation, 2014. (original GloVe paper)
Matthew E. Peters, et al.: Deep contextualized word representations, 2018. (original ELMo paper)
Faruqui, Manaal, and Chris Dyer. "Improving vector space word representations using multilingual correlation." Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics. 2014.
Schnabel, Tobias, et al. "Evaluation methods for unsupervised word embeddings." Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015.
Levy, Omer, and Yoav Goldberg. "Neural word embedding as implicit matrix factorization." Advances in neural information processing systems. 2014.
Arora, Sanjeev, et al. "A latent variable model approach to pmi-based word embeddings." Transactions of the Association for Computational Linguistics 4 (2016): 385-399.
Yin, Zi, and Yuanyuan Shen. "On the dimensionality of word embedding." Advances in Neural Information Processing Systems. 2018.
Wang, Sida, and Christopher D. Manning. Baselines and Bigrams: Simple, Good Sentiment and Topic Classification; ACL 2012.
An, Jisun, Haewoon Kwak. "SemAxis: A Lightweight Framework to Characterize Domain-Specific Word Semantics Beyond Sentiment." (ACL 2018)
Sentence Embedding Papers
Arora, Sanjeev, Yingyu Liang, and Tengyu Ma. "A simple but tough-to-beat baseline for sentence embeddings." (ICLR 2016, original SIF paper)
Kiros, Ryan, et al. "Skip-thought vectors." Advances in neural information processing systems. 2015. (original Skip-Thought paper)
Lajanugen Logeswaran, Honglak Lee, An efficient framework for learning sentence representations. (ICLR 2018, original Quick-Thought paper, code)
Conneau, Alexis, et al. "Supervised learning of universal sentence representations from natural language inference data." (ACL 2017, original InferSent paper)
Subramanian, Sandeep, et al. "Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning." (ICLR 2018, original GenSen paper)
Blogs
http://ruder.io/tag/word-embeddings/index.html
Universal Word Embeddings and Sentence Embeddings
awesome-sentence-embedding (up-to-date)