用Google搜异常信息,肯定都访问过Stack Overflow网站
全球最大的程序员问答网站,名字来自于一个常见的报错,就是栈溢出(stack overflow)
从函数调用开始,在计算机指令层面函数间的相互调用是怎么实现的,以及什么情况下会发生栈溢出
1 栈的意义
先看一个简单的C程序
- function.c

- 直接在Linux中使用GCC编译运行
[hadoop@JavaEdge Documents]$ vim function.c
[hadoop@JavaEdge Documents]$ gcc -g -c function.c
[hadoop@JavaEdge Documents]$ objdump -d -M intel -S function.o
function.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add>:
#include <stdio.h>
int static add(int a, int b)
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d fc mov DWORD PTR [rbp-0x4],edi
7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
a: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
d: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
10: 01 d0 add eax,edx
12: 5d pop rbp
13: c3 ret
0000000000000014 <main>:
return a+b;
}
int main()
{
14: 55 push rbp
15: 48 89 e5 mov rbp,rsp
18: 48 83 ec 10 sub rsp,0x10
int x = 5;
1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5
int y = 10;
23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa
int u = add(x, y);
2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
30: 89 d6 mov esi,edx
32: 89 c7 mov edi,eax
34: e8 c7 ff ff ff call 0 <add>
39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
return 0;
3c: b8 00 00 00 00 mov eax,0x0
}
41: c9 leave
42: c3 ret main函数和上一节我们讲的的程序执行区别不大,主要是把jump指令换成了函数调用的call指令,call指令后面跟着的,仍然是跳转后的程序地址
看看add函数
add函数编译后,代码先执行了一条push指令和一条mov指令
在函数执行结束的时候,又执行了一条pop和一条ret指令
这四条指令的执行,其实就是在进行我们接下来要讲压栈(Push)和出栈(Pop)
函数调用和上一节我们讲的if…else和for/while循环有点像
都是在原来顺序执行的指令过程里,执行了一个内存地址的跳转指令,让指令从原来顺序执行的过程里跳开,从新的跳转后的位置开始执行。
但是,这两个跳转有个区别
- if…else和for/while的跳转,是跳转走了就不再回来了,就在跳转后的新地址开始顺序地执行指令,后会无期
- 函数调用的跳转,在对应函数的指令执行完了之后,还要再回到函数调用的地方,继续执行call之后的指令,地球毕竟是圆的
有没有一个可以不跳回原来开始的地方,从而实现函数的调用呢
似乎有.可以把调用的函数指令,直接插入在调用函数的地方,替换掉对应的call指令,然后在编译器编译代码的时候,直接就把函数调用变成对应的指令替换掉。
不过思考一下,你会发现漏洞
如果函数A调用了函数B,然后函数B再调用函数A,我们就得面临在A里面插入B的指令,然后在B里面插入A的指令,这样就会产生无穷无尽地替换。
就好像两面镜子面对面放在一块儿,任何一面镜子里面都会看到无穷多面镜子

Infinite Mirror Effect
如果函数A调用B,B再调用A,那么代码会无限展开
那就换一个思路,能不能把后面要跳回来执行的指令地址给记录下来呢?
就像PC寄存器一样,可以专门设立一个“程序调用寄存器”,存储接下来要跳转回来执行的指令地址
等到函数调用结束,从这个寄存器里取出地址,再跳转到这个记录的地址,继续执行就好了。
但在多层函数调用里,只记录一个地址是不够的
在调用函数A之后,A还可以调用函数B,B还能调用函数C
这一层又一层的调用并没有数量上的限制
在所有函数调用返回之前,每一次调用的返回地址都要记录下来,但是我们CPU里的寄存器数量并不多
像我们一般使用的Intel i7 CPU只有16个64位寄存器,调用的层数一多就存不下了。
最终,CSer们想到了一个比单独记录跳转回来的地址更完善的办法
在内存里面开辟一段空间,用栈这个后进先出(LIFO,Last In First Out)的数据结构
栈就像一个乒乓球桶,每次程序调用函数之前,我们都把调用返回后的地址写在一个乒乓球上,然后塞进这个球桶
这个操作其实就是我们常说的压栈。如果函数执行完了,我们就从球桶里取出最上面的那个乒乓球,很显然,这就是出栈。
拿到出栈的乒乓球,找到上面的地址,把程序跳转过去,就返回到了函数调用后的下一条指令了
如果函数A在执行完成之前又调用了函数B,那么在取出乒乓球之前,我们需要往球桶里塞一个乒乓球。而我们从球桶最上面拿乒乓球的时候,拿的也一定是最近一次的,也就是最下面一层的函数调用完成后的地址
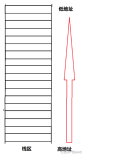
乒乓球桶的底部,就是栈底,最上面的乒乓球所在的位置,就是栈顶

压栈的不只有函数调用完成后的返回地址
比如函数A在调用B的时候,需要传输一些参数数据,这些参数数据在寄存器不够用的时候也会被压入栈中
整个函数A所占用的所有内存空间,就是函数A的栈帧(Stack Frame)
Frame在中文里也有“相框”的意思,所以,每次到这里,都有种感觉,整个函数A所需要的内存空间就像是被这么一个“相框”给框了起来,放在了栈里面。
而实际的程序栈布局,顶和底与我们的乒乓球桶相比是倒过来的
底在最上面,顶在最下面,这样的布局是因为栈底的内存地址是在一开始就固定的。而一层层压栈之后,栈顶的内存地址是在逐渐变小而不是变大

对应上面函数add的汇编代码,我们来仔细看看,main函数调用add函数时
- add函数入口在0~1行
- add函数结束之后在12~13行
在调用第34行的call指令时,会把当前的PC寄存器里的下一条指令的地址压栈,保留函数调用结束后要执行的指令地址
- 而add函数的第0行,push rbp指令,就是在压栈
这里的rbp又叫栈帧指针(Frame Pointer),存放了当前栈帧位置的寄存器。push rbp就把之前调用函数,也就是main函数的栈帧的栈底地址,压到栈顶。 - 第1行的一条命令mov rbp, rsp,则是把rsp这个栈指针(Stack Pointer)的值复制到rbp里,而rsp始终会指向栈顶
这个命令意味着,rbp这个栈帧指针指向的地址,变成当前最新的栈顶,也就是add函数的栈帧的栈底地址了。 - 在函数add执行完成之后,又会分别调用第12行的pop rbp
将当前的栈顶出栈,这部分操作维护好了我们整个栈帧 - 然后调用第13行的ret指令,这时候同时要把call调用的时候压入的PC寄存器里的下一条指令出栈,更新到PC寄存器中,将程序的控制权返回到出栈后的栈顶。
2 构造Stack Overflow
通过引入栈,我们可以看到,无论有多少层的函数调用,或者在函数A里调用函数B,再在函数B里调用A
这样的递归调用,我们都只需要通过维持rbp和rsp,这两个维护栈顶所在地址的寄存器,就能管理好不同函数之间的跳转
不过,栈的大小也是有限的。如果函数调用层数太多,我们往栈里压入它存不下的内容,程序在执行的过程中就会遇到栈溢出的错误,这就是stack overflow
构造一个栈溢出的错误
并不困难,最简单的办法,就是我们上面说的Infiinite Mirror Effect的方式,让函数A调用自己,并且不设任何终止条件
这样一个无限递归的程序,在不断地压栈过程中,将整个栈空间填满,并最终遇上stack overflow。
int a()
{
return a();
}
int main()
{
a();
return 0;
}除了无限递归,递归层数过深,在栈空间里面创建非常占内存的变量(比如一个巨大的数组),这些情况都很可能给你带来stack overflow
相信你理解了栈在程序运行的过程里面是怎么回事,未来在遇到stackoverflow这个错误的时候,不会完全没有方向了。
3 利用函数内联实现性能优化
上面我们提到一个方法,把一个实际调用的函数产生的指令,直接插入到的位置,来替换对应的函数调用指令。尽管这个通用的函数调用方案,被我们否决了,但是如果被调用的函数里,没有调用其他函数,这个方法还是可以行得通的。
事实上,这就是一个常见的编译器进行自动优化的场景,我们通常叫函数内联(Inline)
只要在GCC编译的时候,加上对应的一个让编译器自动优化的参数-O,编译器就会在可行的情况下,进行这样的指令替换。
- 案例

为了避免编译器优化掉太多代码,小小修改了一下function.c,让参数x和y都变成了,通过随机数生成,并在代码的最后加上将u通过printf打印
[hadoop@JavaEdge Documents]$ vim function.c
[hadoop@JavaEdge Documents]$ gcc -g -c -O function.c
[hadoop@JavaEdge Documents]$ objdump -d -M intel -S function.o
function.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
{
return a+b;
}
int main()
{
0: 53 push rbx
1: bf 00 00 00 00 mov edi,0x0
6: e8 00 00 00 00 call b <main+0xb>
b: 89 c7 mov edi,eax
d: e8 00 00 00 00 call 12 <main+0x12>
12: e8 00 00 00 00 call 17 <main+0x17>
17: 89 c3 mov ebx,eax
19: e8 00 00 00 00 call 1e <main+0x1e>
1e: 89 c1 mov ecx,eax
20: bf 67 66 66 66 mov edi,0x66666667
25: 89 d8 mov eax,ebx
27: f7 ef imul edi
29: d1 fa sar edx,1
2b: 89 d8 mov eax,ebx
2d: c1 f8 1f sar eax,0x1f
30: 29 c2 sub edx,eax
32: 8d 04 92 lea eax,[rdx+rdx*4]
35: 29 c3 sub ebx,eax
37: 89 c8 mov eax,ecx
39: f7 ef imul edi
3b: c1 fa 02 sar edx,0x2
3e: 89 d7 mov edi,edx
40: 89 c8 mov eax,ecx
42: c1 f8 1f sar eax,0x1f
45: 29 c7 sub edi,eax
47: 8d 04 bf lea eax,[rdi+rdi*4]
4a: 01 c0 add eax,eax
4c: 29 c1 sub ecx,eax
#include <time.h>
#include <stdlib.h>
int static add(int a, int b)
{
return a+b;
4e: 8d 34 0b lea esi,[rbx+rcx*1]
{
srand(time(NULL));
int x = rand() % 5;
int y = rand() % 10;
int u = add(x, y);
printf("u = %d\n", u);
51: bf 00 00 00 00 mov edi,0x0
56: b8 00 00 00 00 mov eax,0x0
5b: e8 00 00 00 00 call 60 <main+0x60>
60: b8 00 00 00 00 mov eax,0x0
65: 5b pop rbx
66: c3 ret 上面的function.c的编译出来的汇编代码,没有把add函数单独编译成一段指令顺序,而是在调用u = add(x, y)的时候,直接替换成了一个add指令。
除了依靠编译器的自动优化,你还可以在定义函数的地方,加上inline的关键字,来提示编译器对函数进行内联。
内联带来的优化是,CPU需要执行的指令数变少了,根据地址跳转的过程不需要了,压栈和出栈的过程也不用了。
不过内联并不是没有代价,内联意味着,我们把可以复用的程序指令在调用它的地方完全展开了。如果一个函数在很多地方都被调用了,那么就会展开很多次,整个程序占用的空间就会变大了。
这样没有调用其他函数,只会被调用的函数,我们一般称之为叶子函数(或叶子过程)

3 总结
这一节,我们讲了一个程序的函数间调用,在CPU指令层面是怎么执行的。其中一定需要你牢记的,就是程序栈这个新概念。
我们可以方便地通过压栈和出栈操作,使得程序在不同的函数调用过程中进行转移。而函数内联和栈溢出,一个是我们常常可以选择的优化方案,另一个则是我们会常遇到的程序Bug。
通过加入了程序栈,我们相当于在指令跳转的过程种,加入了一个“记忆”的功能,能在跳转去运行新的指令之后,再回到跳出去的位置,能够实现更加丰富和灵活的指令执行流程。这个也为我们在程序开发的过程中,提供了“函数”这样一个抽象,使得我们在软件开发的过程中,可以复用代码和指令,而不是只能简单粗暴地复制、粘贴代码和指令。
4 推荐阅读
可以仔细读一下《深入理解计算机系统(第三版)》的3.7小节《过程》,进一步了解函数调用是怎么回事。
另外,我推荐你花一点时间,通过搜索引擎搞清楚function.c每一行汇编代码的含义,这个能够帮你进一步深入了解程序栈、栈帧、寄存器以及Intel CPU的指令集。
参考
深入浅出计算机组成原理