
免费开通大数据服务:https://www.aliyun.com/product/odps
乍一看标题会以为是不是作者写错了,怎么会有从MaxCompute到MaxCompute迁移数据的场景呢?在实际使用中已经有客户遇到了这种场景,比如:两个网络互通的专有云环境之间数据迁移、公共云数加DataIDE上两个云账号之间数据迁移、还有网络不通的两个MaxCompute项目数据迁移等等,下面我们逐个场景介绍。
场景一:两个网络互通的专有云MaxCompute环境之间数据迁移
这种场景需要先从源MaxCompute中导出元数据DDL,在目标MaxCompute中初始化表,然后借助DataX工具完成数据迁移,步骤如下:
1. 安装配置ODPS客户端
https://help.aliyun.com/document_detail/27804.html
2. 安装配置Datax客户端
下载DataX工具包,下载后解压至本地某个目录,修改权限为755,进入bin目录,即可运行样例同步作业:
$ tar zxvf datax.tar.gz
$ sudo chmod -R 755 {YOUR_DATAX_HOME}
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py ../job/job.json3. 表结构迁移
3.1 从ODPS中导出某个表的建表语句,可用来测试数据同步。
export table table_name;
DDL:create table IF NOT EXISTS ` date_timestame ` (`id` datetime comment "") partitioned by(pt string comment "");
alter table ` date_timestame ` add IF NOT EXISTS partition(dt='20161001');
alter table ` date_timestame ` add IF NOT EXISTS partition(dt='20161101');
alter table ` date_timestame ` add IF NOT EXISTS partition(dt='20161201');
alter table ` date_timestame ` add IF NOT EXISTS partition(dt='20170101');3.2 从ODPS批量导出建表语句。
export <projectname> <local_path>;
3.3 将建表语句在目标ODPS的project下执行,即可完成表结构创建。
4. 数据迁移
从源ODPS读取数据写入到目标ODPS,先按照“表结构迁移”在目标ODPS创建一个表,做DataX数据同步验证。
4.1 、创建作业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
odps2odps.json样例(填写相关参数,odpsServer/ tunnelServer要改成源/目标ODPS配置):
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessId": "${srcAccessId}",
"accessKey": "${srcAccessKey}",
"project": "${srcProject}",
"table": "${srcTable}",
"partition": ["pt=${srcPartition}"],
"column": [
"*"
],
"odpsServer": "http://service.odpsstg.aliyun-inc.com/stgnew",
"tunnelServer": "http://tunnel.odpsstg.aliyun-inc.com"
}
},
"writer": {
"name": "odpswriter",
"parameter": {
"accessId": "${dstAccessId}",
"accessKey": "${dstAccessKey}",
"project": "${dstProject}",
"table": "${dstTable}",
"partition": "pt",
"column": [
"*"
],
"odpsServer": "http://service.odpsstg.aliyun-inc.com/stgnew",
"tunnelServer": "http://tunnel.odpsstg.aliyun-inc.com"
}
}
}
]
}
}4.2 、启动DataX
$ cd {YOUR_DATAX_DIR_BIN} $ python datax.py ./odps2odps.json
同步结束,显示日志如下:
4.3 、批量迁移
根据导出的表结构批量生成DataX同步脚本,我会协助完成。
场景二:公共云数加DataIDE上两个云账号之间数据迁移
这个场景比较容易理解,比如一个公司很可能会申请多个云账号,假如每个云账号都开通了MaxCompute,很可能就会碰到两个云账号的MaxCompute之间数据迁移。公共云上都借助于DataIDE使用MaxCompute,而DataIDE上面本身提供了数据同步任务,我们通过配置数据同步任务即可很容易的完成数据迁移。执行步骤如下:
1、在其中一个MaxCompute项目空间项目管理中添加数据源,该数据源为另一个云账号的MaxCompute项目空间。
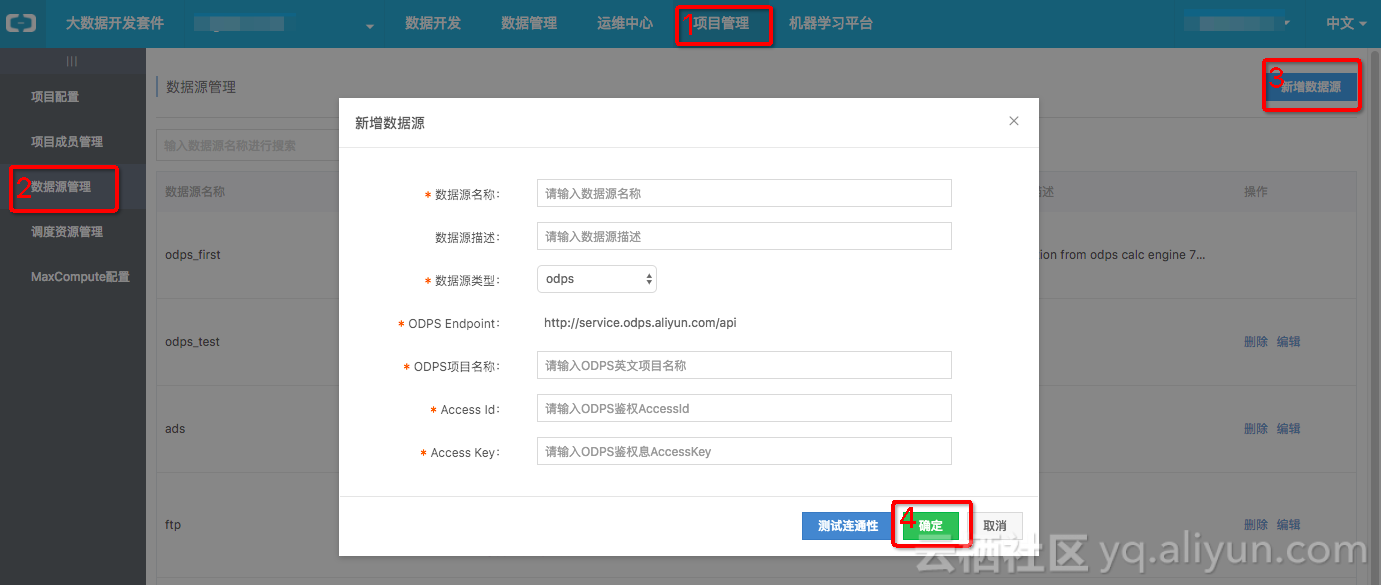
2、在DataIDE数据开发中新建“数据同步”任务,如果目标数据源中表还不存在,可以点击“快速建ODPS表”,配置字段映射等。
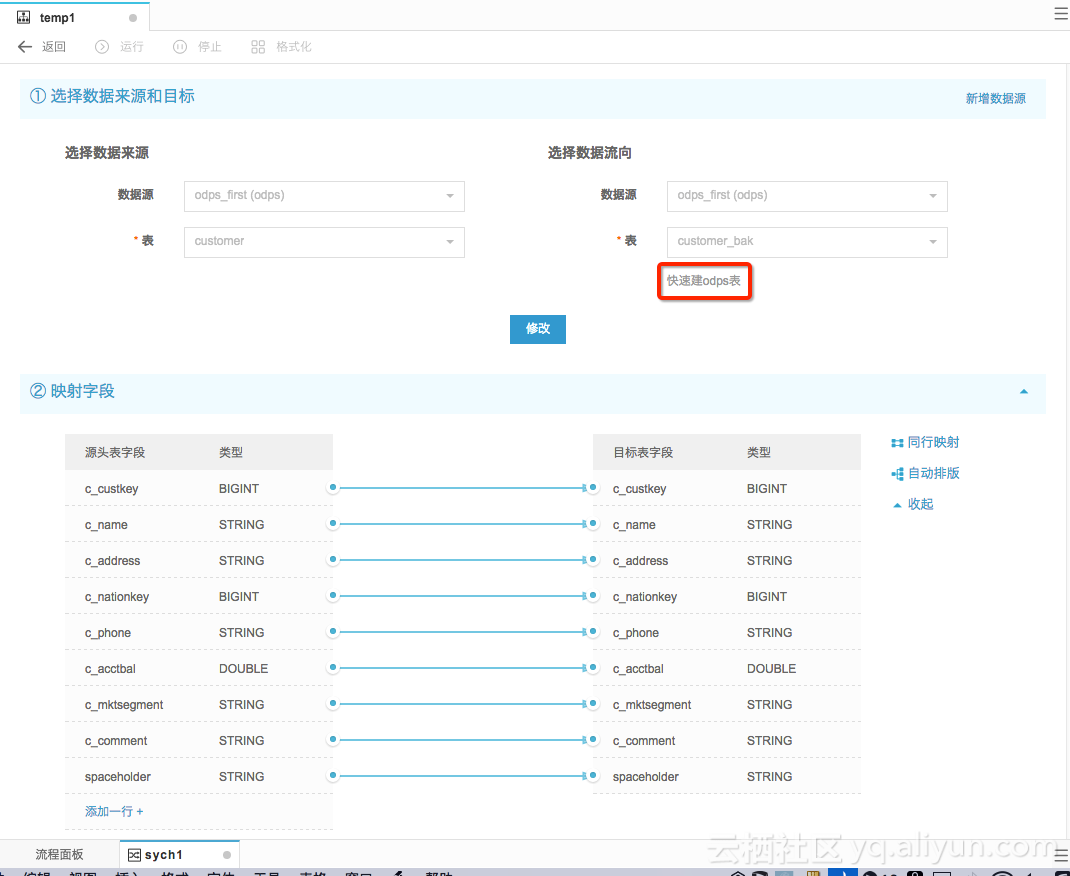
3、保存之后点击“测试运行”即可。
场景三:网络不通的两个MaxCompute环境数据迁移
这种场景做数据同步局限性比较大,由于网络不通,数据迁移必须要在中间落盘后再写入,所以当数据量比较大时要考虑磁盘容量、带宽等问题。步骤如下:
1、首先也是要先将源MaxCompute项目空间的DDL导出并在目标项目空间创建表,操作同场景一。
export <projectname> <local_path>;
2、安装配置ODPS客户端,操作同场景一。
3、通过ODPS CLT中的tunnel命令实现数据的导出。命令参考:
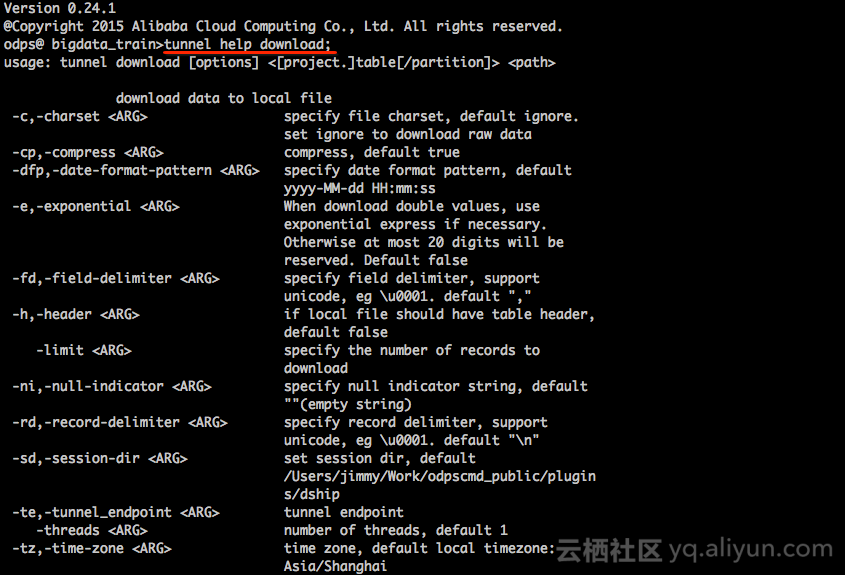
Example:
tunnel download test_project.test_table log.txt
4、通过ODPS CLT中的tunnel命令实现数据的导入。命令参考:
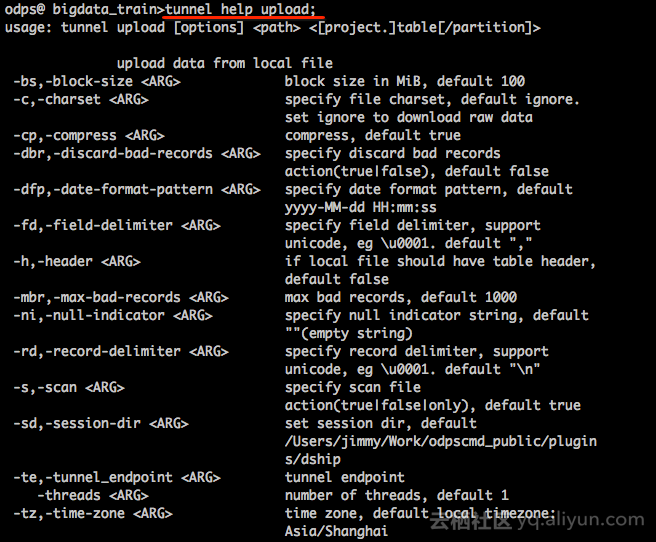
Example:
tunnel upload log.txt test_project.test_table
相关数据同步及分析文章:
