世界上没有两片雪花是完全相同的。
为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的ID,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的ID必须不同。Twitter公司提出了一种名为SnowFlake算法来生成唯一的ID作为系统中的key。
为何需要生成ID?
在应用程序中,经常需要全局唯一的ID作为数据库中表主键。如何生成全局唯一ID?
首先,需要确定全局唯一ID是整型还是字符串?如果是字符串,那么现有的UUID就完全满足需求,不需要额外的工作。缺点是字符串作为ID占用空间大,索引效率比整型低。
通常情况下,我们都会使用数据库的自增主键功能,从1开始,基本可以做到连续递增。Oracle可以用SEQUENCE,MySQL可以用表主键的AUTO_INCREMENT, 虽然不能保证全局唯一,但每个表唯一,也基本满足需求。
但是这样的做法有两个问题,第一个是每次生成都是先要插入数据库,让数据库去生成这个ID后返回。当需要插入关联数据的时候,必须先等数据库插入成功,然后才能插入关联数据。如果插入过程比较长,需要用队列操作的时候,就无法将相关操作放入队列做异步处理。第二个是生成的ID是连续的,很多ID是用于用户号,订单号等敏感信息,网站外部用户可以根据特定时间之间生成的ID差值来估算出业务量。
因此,可以在插入数据库之前,就先用Twitter提出的雪花算法,生成ID后再作为主键插入数据库。
SnowFlake算法
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:
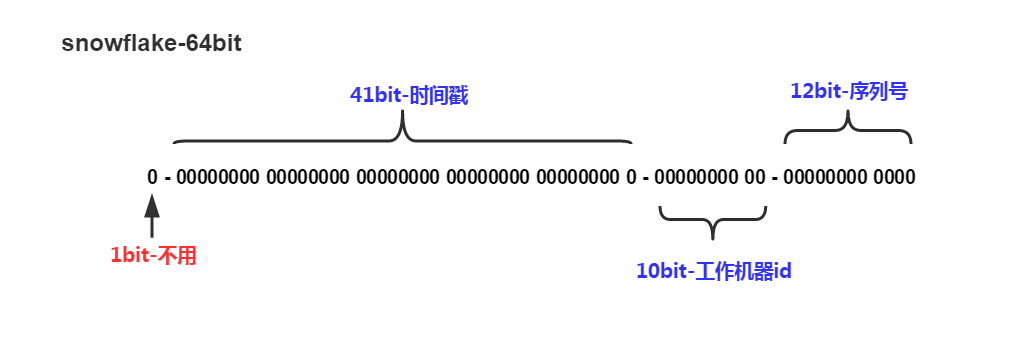
- 1位,不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0
- 41位,用来记录时间戳(毫秒)。
41位可以表示2^{41}-1个数字,
如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 2^{41}-1,减1是因为可表示的数值范围是从0开始算的,而不是1。
也就是说41位可以表示2^{41}-1个毫秒的值,转化成单位年则是(2^{41}-1) / (1000 60 60 24 365) = 69年
- 10位,用来记录工作机器id。
可以部署在2^{10} = 1024个节点,包括5位datacenterId和5位workerId
5位(bit)可以表示的最大正整数是2^{5}-1 = 31,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId。严格来说,应该每个进程都需要不同的workId。
- 12位,序列号,用来记录同毫秒内产生的不同id。
12位(bit)可以表示的最大正整数是2^{12}-1 = 4095,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
SnowFlake算法生成53位长度整数
如果直接用网上的SnowFlake算法库生成的64位长度整数,在作为主键传递到Web前端的时候,就会碰到一个大坑。JavaScript里面没有64位整数,只有一种Number数据类型表示数字,采用IEEE754格式来表示数字,不区分整数和浮点数,JavaScript中的所有数字都用浮点数值表示,最大的数字精度只有53位,超过这个位数,JavaScript将丢失精度。因此,使用53位整数可以直接由JavaScript读取,而超过53位时,就必须转换成字符串才能保证JavaScript处理正确,这会给API接口带来额外的复杂度。
因此我根据网上的代码,做了一些修改,用c#语言改写SnowFlake算法生成53位长度整数。方法就是保留41位时间戳,加上2位机器编号,10位序列号组成一个53位的ID。对于小型的项目,4个生成器也够用了,每毫秒最多可以生成1024个序列号也足够满足使用。
源代码以MIT协议的方式开源,托管到github。


