作者:郭一
整理:董黎明
本文整理自2019阿里云峰会·上海开发者大会开源大数据专场中小红书实时推荐团队负责人郭一先生现场分享。小红书作为生活分享类社区,目前有8500万用户,年同比增长为300%,大约每天有30亿条笔记在发现首页进行展示。推荐是小红书非常核心且重要的场景之一,本文主要分享在推荐业务场景中小红书的实时计算应用。
实时计算在推荐业务中的场景
线上推荐流程
小红书线上推荐的流程主要可以分为三步。第一步,从小红书用户每天上传的的笔记池中选出候选集,即通过各种策略从近千万条的笔记中选出上千个侯选集进行初排。第二步,在模型排序阶段给每个笔记打分,根据小红书用户的点赞和收藏行为给平台带来的价值设计了一套权重的评估体系,通过预估用户的点击率,评估点击之后的点赞、收藏和评论等的概率进行打分。第三步,在将笔记展示给用户之前,选择分数高的笔记,通过各种策略进行多样性调整。
在此模型中最核心的点击率、点赞数、收藏、评论等都是通过机器学习模型训练对用户各项行为的预估并给出相应分数。

推荐系统架构
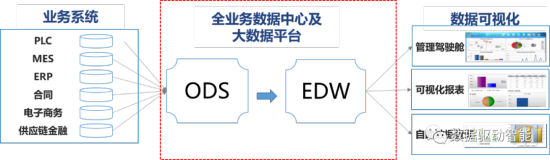
在小红书线上推荐过程的背后是一套完整的从线上到线下的推荐系统,下图展示了小红书推荐系统架构,红色表示实时操作,灰色则是离线操作。通过算法推荐之后,用户和笔记进行交互,产生用户的曝光、点赞和点击的信息,这些信息被收集形成用户笔记画像,也会成为模型训练的训练样本,产生分析报表。训练样本最终生成预测模型,投入线上进行算法推荐,如此就形成了一个闭环,其中分析报表则由算法工程师或策略工程师进行分析,调整推荐策略,最后再投入到线上推荐中。

离线批处理
离线批处理流程如下图所示,之前的处理流程是在客户端产生用户交互和打点,打点好的数据放入数仓中,以T+1模式更新用户笔记画像,生成报表并生成训练样本,最后进行模型训练和分析。小红书初级版本的离线批处理情况,整个流程都基于Hive进行处理,处理流程较慢,无法满足业务需求。

实时流处理
2018年开始小红书将离线的pipeline升级为实时的pipeline,用户一旦产生交互点击,系统会实时维护数据,更新用户笔记画像,实时产生训练样本,更新模型及生成报表。实时的流处理大大提高了开发效率,同时实时流处理依赖于Flink。在实时流中,首先用户的实时交互进入Kafka,借助Flink任务维护用户笔记画像,将其传给线上用户画像系统。相对来说,用户的笔记画像比较简单,不会存在过多的状态,而实时流处理中非常重要的场景是实时归因,这也是小红书最核心的业务。实时归因是一个有状态的场景,根据打点信息产生用户的行为标签,所有实时指标和训练样本都依赖行为标签,其中,实时指标放在Click House,数据分析师和策略工程师基于ClickHouse数据进行分析,训练样本仍然落到Hive中进行模型训练,同时在线学习系统中会将训练样本落到Kafka,进行实时模型训练。

实时归因
实时归因数据
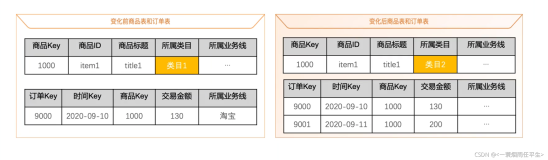
实时归因将笔记推荐给用户后会产生曝光,随即产生打点信息,用户笔记的每一次曝光、点击、查看和回退都会被记录下来。如下图所示,四次曝光的用户行为会产生四个笔记曝光。如果用户点击第二篇笔记,则产生第二篇笔记的点击信息,点赞会产生点赞的打点信息;如果用户回退就会显示用户在第二篇笔记停留了20秒。实时归因会生成两份数据,第一份是点击模型的数据标签,在下图中,第一篇笔记和第三篇笔记没有点击,第二篇笔记和第四篇笔记有点击,这类数据对于训练点击模型至关重要。同样,点赞模型需要点击笔记数据,比如用户点击了第二篇笔记并发生点赞,反之点击了第四篇笔记但没有点赞,时长模型需要点击之后停留的时间数据。以上提到的数据需要与上下文关联,产生一组数据,作为模型分析和模型训练的原始数据。

Flink Job - Session Labeler
小红书在处理实时归因原始数据时应用了Flink任务。从Kafka Source中读数据再写到另外一个Kafka Sink。Key(user_id和note_id)根据用户笔记和是否发生曝光和点击分为两个Session,Session使用Process Function API处理记录,每条记录都会记录曝光的Session和点击的Session。Session有20分钟的定长窗口,即在收到用户行为曝光或者点击之后,开20分钟的窗口查看是否这期间会发生曝光、点击、点赞或者停留了多少时间。Session中有状态信息,比如发生点击并点赞,系统维护用户在状态中停留的时间,检查点击是否有效等。Flink窗口结束时,需要将Session State中的内容输出到下游,进行分析和模型训练,同时清除ValueState。

实际生产需要解决的问题
在实际生产中落地Flink任务需要解决较多的问题。首先是如何对Flink进行集群管理,上了生产环境之后需要做Checkpoint,将任务持久化,尤其需要注意的一点是Backfill,持久化一旦出错,需要回到过去的某个时间,重新清除错误数据并恢复数据。
Flink集群管理:小红书选择将Flink部署在 K8s集群上,在小红书看来,K8S或许是未来的趋势之一。

Checkpoint & State持久化:Flink 的State 分为两种,FsStateBackend和RocksDBStateBackend。FsStateBackend支持较小的状态,但不支持增量的状态。在实时归因的场景中有20分钟的窗口,20分钟之内发生的所有的状态会放在内存中,定期做持久化。如果要避免这20分钟的数据丢失,RocksDBStateBackend是更好的选择,因为RocksDBStateBackend支持增量Checkpoint。

RocksDB调优:具体使用RocksDBStateBackend时依然会遇到调优问题。小红书在开始测试时,Checkpoint频率设置较短,一分钟做一次Checkpoint,而RocksDB每次做Checkpoint时都需要将数据从内存flash到磁盘中,Checkpoint频率较高时会产生非常多的小std文件,RocksDB需要花大量时间和资源去做整合,将小文件合并为大文件。State本身已经比较大,假如flash持续Compaction,磁盘I/O将会成为瓶颈,最后导致产生反压上游。
另一个问题是使用RocksDBStateBackend会有生成较多的MemTable,如果内存没有配置好,会导致out of memory,需要重新计算内存,调配MemTable,Parallelism和K8s point的内存。调优之后任务运行较为稳定,这时需要把本地磁盘换成高性能的SSD,保证内存有足够的空间。
此外,每次做Checkpoint都会产生性能损失。小红书选择将Checkpoint频率改成十分钟,同样可以满足生产需求,而且回填10分钟的数据只需要一到两分钟,需要注意的是调大RocksDB Compaction Threshold,避免频繁进行小文件的合并。

Backfill:回填是生产中常见的场景,实际生产中如果开发者写错代码导致数据错误,则需要删除错误数据,重新跑正确代码回填正确的数据;另外,如果原本只有点赞功能,会产生新的回填场景,分析用户点赞是否为有效点赞或者对其做简单的逻辑恢复都需要Backfill。Backfill非常依赖Flink对Hive的支持,小红书一直以来的数据都存放在Hive上,所以非常期待Flink 1.9版本性能的提高,尤其对Hive的支持的提升和对批的支持的加强。

Red Flink实时流计算平台
小红书实时流计算平台及周边生态
小红书推荐系统是一个流计算的平台,同时涉及周边的生态。如下图所示,最右边是数据接入的模块,支持从客户端接入数据,同时后端的服务提供LogSDK的模块帮助业务直接接入实时计算的平台。红色模块是流计算平台中正在开发的模块,比如,Canal通过事务的数据库日志直接将订单流对接到数据平台,系统自动分析数据Schema,一旦Schema发生变化,自动重启相应Flink任务。左下角是基于Flink 1.8做的开发,在此基础上根据业务需要增加了Latency监控,便于分析Flink堵塞的Operator,同时将Latency监控直接接入到系统中。小红书基于Flink的SQL也进行了开发,实现了不同的connector,比如ClickHouse、Hbase、Kafka等,目前这套平台支持的业务除了实时归因的场景外,还有数据ETL、实时Spam、实时DAU,包括我们正在开发的实时RGMV大促看板都是基于此平台搭建的。

小红书Flink系统
下图为系统的部分截图,左边为业务方使用小红书Flink实时流计算平台时,可以选择数据目的地,比如aws-hive和rex-clickhouse表明数据需要放到Hive和ClickHouse中。然后在Schema中输入JSON或PB格式数据,平台可以自动识别Schema,同时将数据Schema转成Flink SQL ETL的命令,自动更新Flink ETL Job的任务。此外,系统会对任务进行监控,监控任务的延迟时间、有无数据丢失,如果延迟过高或有数据丢失则产生报警及报警的级别。

平台小红书推荐预测模型的演近
- 9个行为的预测模型 (click, hide, like, fav, comment, share, follow, …)
- Click模型规模: 5亿样本/天, 1T数据/天
上面简单介绍了小红书的实时计算平台,另外一部分就是TensorFlow和Machine Learning。2018年12月,小红书的推荐预测模型只是非常简单的Spark上的GBDT模型。后期在GBDT模型上加了LR层,后来还引入了Deep和Wide。到2019年7月,小红书推荐预测模型已经演化到了GBDT + Sparse D&W的模型。小红书主要有9个预测任务,包括click、hide、like、fav、comment、share以及follow等。其中,Click是小红书最大的模型,一天大概产生5亿的样本进行模型训练,数据量达到1T/天。

目前小红书的Red ML模型基于KubeFlow,在小红书开始做ML模型时,KubeFlow在开源社区中比较受欢迎,而且TFJob可以支持TensorFlow的分布式训练。

总结与展望
小红书从去年年底开始做推荐系统,系统的搭建既依赖开源社区,也拥抱开源社区。整个实时计算平台的搭建都是基于Flink,也十分期待Flink 1.9 的新功能对于Hive 和批的支持;AI是目前小红书比较强的需求,包括模型训练算力、效率等非常敏感,也会持续关注社区相关技术;后期希望能够融合Flink与AI,将流计算与机器学习无缝整合实现更智能高效的推荐。