前言
在开始之前,先来看一段图像解码序列(格式为YUV420)的4个渲染结果,这里我分别截了4张图

其中4个渲染效果分别是
左上:直接渲染视频帧并绘制到窗口上
右上:九宫格缩放绘制帧致窗口上
左下:对视频帧进行2D变换并绘制到窗口上
右下:渲染视频帧并绘制到3D变换立方体的6个面上
试着想一下,如果在CPU端进行图像处理,比如用C/C++实现,包括上述4种效果会涉及到的格式转换、2D/3D变换、立方体贴图、无锯齿缩放等操作,实现的复杂度和代码量如何,会涉及哪些知识?
如果直接使用OpenGL,实现的复杂度和代码量又该如何?
问题
- 何种场景下更适合使用OpenGL?
- OpenGL编程与CPU编程的区别?
- 如何快速入门编写OpenGL程序?
看完此文,或许你会觉得原来渲染并没有想像的那么难!
从C/C++开始
考虑上面的例子,都需要将输入图像序列的YUV420格式转成RGBA32位进行后期渲染和显示,颜色转换比如像下面这样实现
/**
* @param dst 输出图像地址RGBA
* @param data 输入图像地址YUV420P
* @param width 图像宽度
* @param height 图像高度
* @param coef YUV转RGB的颜色矩阵,支持BT601/709/2020
*/
void yuv420p_2_rgba(uint8_t* dst, uint8_t* data, int width, int height, float coef[9])
{
for(int i = 0; i < (height >> 1); ++i) // 一次处理2行
{
for(int j = 0; j < (width >> 1); ++j) // 一交处理2列
{
auto py = data + width * 2 * i + j * 2; // 获取左上角Y地址
auto u = data[width * height + i * (width >> 1) + j] - 128; // 获取U值
auto v = data[width * height * 5 / 4 + i * (width >> 1) + j] - 128; // 获取V值
// 奇数行奇数列
for(int k = 0; k < 3; ++k)
{
dst[i * width * 8 + j * 8 + k] = clamp(coef[k*3] * py[0] + coef[k*3+1] * u + coef[k*3+2] * v, 0, 255);
}
// 奇数行偶数列
for(int k = 0; k < 3; ++k)
{
dst[i * width * 8 + j * 8 + k + 4] = clamp(coef[k*3] * py[1] + coef[k*3+1] * u + coef[k*3+2] * v, 0, 255);
}
// Y地址下移一行
py += width;
// 偶数行奇数列
for(int k = 0; k < 3; ++k)
{
dst[i * width * 8 + j * 8 + k + width * 4] = clamp(coef[k*3] * py[0] + coef[k*3+1] * u + coef[k*3+2] * v, 0, 255);
}
// 偶数行偶数列
for(int k = 0; k < 3; ++k)
{
dst[i * width * 8 + j * 8 + k + width * 4 + 4] = clamp(coef[k*3] * py[1] + coef[k*3+1] * u + coef[k*3+2] * v, 0, 255);
}
}
}
}上述C/C++代码的实现是一个初级版本,如果希望更高性能的运行在CPU上,还需要进行类似汇编优化、多线程优化(如OpenMP)等,但即便这样,对于解码4K的图像,运行在8核心超线程且主频3.4GHz的CPU上,仍然无法满足低延时计算的要求。
当C/C++实现的性能无法达到要求时,还可以采用汇编优化、多线程优化等方法,但复杂度会大大增加。
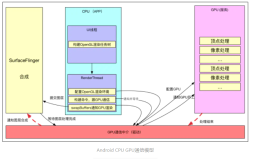
对于这一类计算密集型的工作,下面我们将看到更适合采用GPU进行处理,同时无须像CPU实现那样需要关注过多的细节。
OpenGL实现
与CPU的计算过程类似,可以将OpenGL理解为一个模块,我们通过设置给OpenGL模块相应的参数,并拿到处理的结果。
- 纹理
类似CPU上的内存,需要创建相应的GPU显存用于存储图像数据,如上所举例子,YUV420P存在三片内存,分别是Y、U、V,因此需要创建三张显存
glGenTextures(3, texture);
for (int i = 0; i < 3; ++i)
{
glBindTexture(GL_TEXTURE_2D, texture[i]);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RED, texture_width[i], texture_height[i], 0, GL_RED, GL_UNSIGNED_BYTE, 0);
ASSERT_GL();
}上述代码是创建三张显存,分别是Y、U、V,同时指定纹理缩小、放大使用线性插值,WRAP采样使用边缘像素颜色值。
当需要将CPU的内存数据上传到GPU显存中时,只需要将内存指针和相应的宽高格式等信息传递给glTexImage2D接口就行,如下
for (int i = 0; i < 3; ++i)
{
glBindTexture(GL_TEXTURE_2D, texture[i]);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RED, texture_width[i], texture_height[i], 0, GL_RED, GL_UNSIGNED_BYTE, addressof(buffer[planar_offset[i]]));
ASSERT_GL();
}这里可以看两次操作都需要使用glBindTexture接口,这是因为需要更新OpenGL内部TEXTURE_2D的当前绑定对象状态。
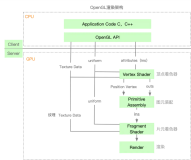
CPU上我们可以直接逐像素甚至逐字节的操作,但GPU不行,由于GPU内部是像素多线程并行处理,因此我们实际上是通过可编程一段可执行程序并发送给GPU处理的,可执行程序的生成分为两步。
- 顶点着色器
由于不是像CPU上逐像素操作那样编程,我们只需要将渲染的顶点边界值告诉GPU,GPU内部会自动帮我们对边界以内的像素位置进行计算
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec2 aTexCoord;
out vec2 TexCoord;
void main()
{
gl_Position = vec4(aPos, 0.0, 1.0);
TexCoord = vec2(aTexCoord.x, 1.0 - aTexCoord.y);
}上述代码示例了一个顶点着色器的实现,双称vertex shader,顾名思义,即是对像素顶点进行操作,其中aPos和aTexCoord分别是外部输入给GPU的顶点位置和坐标,main函数计算更新后的位置和坐标,并发送给片段着色器。
- 片段着色器
#version 330 core
out vec4 FragColor;
in vec2 TexCoord;
uniform sampler2D texY;
uniform sampler2D texU;
uniform sampler2D texV;
uniform mat3 coef;
void main()
{
float y = (texture(texY, TexCoord).r - 16.0/255.0) * (255.0/219.0);
float u = (texture(texU, TexCoord).r - 0.5) * (255.0/224.0);
float v = (texture(texV, TexCoord).r - 0.5) * (255.0/224.0);
FragColor = vec4(coef * vec3(y, u, v), 1.0);
}这里可以看到,输入给片段着色器的是TexCoord,即顶点着色器的输出,这里uniform表示可能随时会发生变化的变量,需要外部渲染前设置更新,main函数输出计算后的像素颜色值。
- 可执行程序
当完成了顶点着色器和片段着色器后,我们就可以将两者编译并链接成可实际在GPU上运行的可执行程序了。
GLuint GenerateProgram(char const* vertexShaderSource, char const* fragmentShaderSource)
{
// 编译顶点着色器
int vertexShader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);
int success;
char infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);
if (!success)
{
glGetShaderInfoLog(vertexShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 编译片段着色器
int fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);
glGetShaderiv(fragmentShader, GL_COMPILE_STATUS, &success);
if (!success)
{
glGetShaderInfoLog(fragmentShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::FRAGMENT::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 链接顶点着色器和片段着色器
int shaderProgram = glCreateProgram();
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
glLinkProgram(shaderProgram);
glGetProgramiv(shaderProgram, GL_LINK_STATUS, &success);
if (!success)
{
glGetProgramInfoLog(shaderProgram, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::PROGRAM::LINKING_FAILED\n" << infoLog << std::endl;
}
glDeleteShader(vertexShader);
glDeleteShader(fragmentShader);
return shaderProgram;
}就像编译C++代码一样,先分别编译顶点和片段着色器,生成目标文件,再将两个目标文件链接成可执行程序。
- 顶点数组对象
又称为VAO(Vertex Array Object),当我们生成可执行程序并发送给GPU后,还需要将顶点和纹理坐标等信息告诉Program,VAO使用如下方法生成
// *INDENT-OFF*
float vertices[] =
{
// 顶点位置 // 纹理坐标
-1.0f, -1.0f, 0.0f, 0.0f, // bottom left
1.0f, -1.0f, 1.0f, 0.0f, // bottom right
-1.0f, 1.0f, 0.0f, 1.0f, // top left
1.0f, 1.0f, 1.0f, 1.0f, // top right
};
// *INDENT-ON*
glGenVertexArrays(1, &VAO[kRenderNormal]);
glGenBuffers(1, &VBO[kRenderNormal]);
glBindVertexArray(VAO[kRenderNormal]);
glBindBuffer(GL_ARRAY_BUFFER, VBO[kRenderNormal]);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 顶点位置属性
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 纹理坐标属性
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)(2 * sizeof(float)));
glEnableVertexAttribArray(1);
glBindVertexArray(0);
ASSERT_GL();先创建VAO,再绑定VAO到当前使用,再创建相应的VBO并绑定到VAO上,注意这里的顶点位置归一化范围为【-1,1】,纹理坐标归一化范围为【0,1】,其中左下角为原点坐标【0,0】,这与通常理解的窗口坐标系统和图像坐标系不同。
这里可以将VAO理解成一个对象,我们通过调用OpenGL的接口分别更新这个对象的参数值,尤其是顶点位置和纹理坐标固定的情况下,我们只需要从CPU到GPU上传一次数据,减少性能开销。
- 视口
渲染之前,还需要告诉OpenGL渲染到窗口的具体位置和区域
glViewport(0, 0, width, height);- 渲染
当上述OpenGL资源都准备好后,我们就可以开始渲染了
glUseProgram(program[render_mode]);
auto loc = glGetUniformLocation(program[kRenderNormal], "coef");
glUniformMatrix3fv(loc, 1, GL_FALSE, yuva_to_rgba_709);
ASSERT_GL();
for (int i = 0; i < 3; ++i)
{
glActiveTexture(GL_TEXTURE0 + i);
glBindTexture(GL_TEXTURE_2D, texture[i]);
auto loc = glGetUniformLocation(program[kRenderNormal], texture_name[i]);
glUniform1i(loc, i);
ASSERT_GL();
}
glBindVertexArray(VAO[render_mode]);
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
ASSERT_GL();
glBindVertexArray(0);如上代码所示,先将CPU上计算好的值更新到GPU中的Program中,再采用相应的Draw接口,此时OpenGL就渲染完成。
需要注意的是,GL_TEXTURE_2D设置给Program,需要先Active相应的GL_TEXTUREi,再更新位置为索引glUniform1i。
更多渲染实现
- 九宫格
从一屏到九屏,使用OpenGL实现非常简单,着色器可以复用,我们只需要将CPU发送给GPU的顶点位置和纹理坐标改变一下即可,这里我用了EBO实现作为例子,实际也可以使用上述的VBO。
// *INDENT-OFF*
float vertices[] =
{
// 顶点位置 // 纹理坐标
-1.0f, -1.0f, 0.0f, 3.0f, // bottom left
1.0f, -1.0f, 3.0f, 3.0f, // bottom right
-1.0f, 1.0f, 0.0f, 0.0f, // top left
1.0f, 1.0f, 3.0f, 0.0f, // top right
};
// *INDENT-ON*
unsigned char indices[] =
{
0, 1, 2, // first triangle
1, 2, 3 // second triangle
};
glGenVertexArrays(1, &VAO[kRenderRepeat]);
glGenBuffers(1, &VBO[kRenderRepeat]);
glGenBuffers(1, &EBO[kRenderRepeat]);
glBindVertexArray(VAO[kRenderRepeat]);
glBindBuffer(GL_ARRAY_BUFFER, VBO[kRenderRepeat]);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO[kRenderRepeat]);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
// 顶点位置属性
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 纹理坐标属性
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)(2 * sizeof(float)));
glEnableVertexAttribArray(1);
glBindVertexArray(0);
ASSERT_GL();如上代码所未,最大的不同,即是直接将纹理坐标位置从【0,1】的范围变成了【0,3】,在渲染时还需要更新纹理的采样模式
for (int i = 0; i < 3; ++i)
{
glBindTexture(GL_TEXTURE_2D, texture[i]);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RED, texture_width[i], texture_height[i], 0, GL_RED, GL_UNSIGNED_BYTE, addressof(buffer[planar_offset[i]]));
ASSERT_GL();
if (render_mode == kRenderRepeat)
{
glGenerateMipmap(GL_TEXTURE_2D);
}
}
auto wrap_mode = render_mode == kRenderRepeat ? GL_REPEAT : GL_CLAMP_TO_EDGE;
auto filter_mode = render_mode == kRenderRepeat ? GL_NEAREST_MIPMAP_LINEAR : GL_LINEAR;
for (int i = 0; i < 3; ++i)
{
glBindTexture(GL_TEXTURE_2D, texture[i]);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, filter_mode);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, wrap_mode);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, wrap_mode);
ASSERT_GL();
}上述代码修改后,由于使用EBO,因此需要采用索引绘制接口进行渲染
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_BYTE, 0);如此就可以见到9屏的效果了,是不是so easy!
- 立方体
试想一下,如果使用C++实现一个立方体渲染,是不是相当复杂,光是想想空间变换及纹理贴图这些东西就比较头疼,但是GPU实现就相当简单了,我们只需要多增加几个三角形绘制
// *INDENT-OFF*
float vertices[] =
{
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
0.5f, -0.5f, -0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f
};我们只需要在2D渲染的基础上,增加所有6个面的深度信息
glDrawArrays(GL_TRIANGLES, 0, 36);即是简单的从渲染2个三角形,到改成渲染12个三角形,就完成立方体渲染。
- 2D变换
要让图像动起来,我们只需要将计算逐帧变化的模型、视图矩阵更新给Program
static glm::mat4 model = glm::mat4(1.0f);
static glm::mat4 view = glm::mat4(1.0f);
if (!pause)
{
model = glm::scale(glm::mat4(1.0f), glm::vec3(sinf(glfwGetTime()), sinf(glfwGetTime()), 1.f));
model = glm::scale(model, glm::vec3((float)window_height / window_width, 1.f, 1.f));
model = glm::rotate(model, glm::radians(-45.0f * (float)glfwGetTime()), glm::vec3(0.0f, 0.0f, 1.0f));
model = glm::scale(model, glm::vec3((float)window_width / window_height, 1.f, 1.f));
}
auto loc = glGetUniformLocation(program[render_mode], "model");
glUniformMatrix4fv(loc, 1, GL_FALSE, glm::value_ptr(model));
ASSERT_GL();
loc = glGetUniformLocation(program[render_mode], "view");
glUniformMatrix4fv(loc, 1, GL_FALSE, glm::value_ptr(view));
ASSERT_GL();- 3D变换
三维变换稍微复杂些,需要考虑深度信息,同时将计算好的变化的模型、视图、投影矩阵更新给Program
glm::mat4 projection = glm::perspective(glm::radians(45.0f), (float)window_width / window_height, 0.1f, 100.0f);
loc = glGetUniformLocation(program[kRenderCube], "projection");
glUniformMatrix4fv(loc, 1, GL_FALSE, glm::value_ptr(projection));
ASSERT_GL();static glm::mat4 view = glm::mat4(1.0f);
float radius = 5.0f;
float camX = sin(glfwGetTime()) * radius;
float camZ = cos(glfwGetTime()) * radius;
if (!pause)
{
view = glm::lookAt(glm::vec3(camX, 0.0f, camZ), glm::vec3(0.0f, 0.0f, 0.0f), glm::vec3(0.0f, 1.0f, 0.0f));
}
auto loc = glGetUniformLocation(program[render_mode], "view");
glUniformMatrix4fv(loc, 1, GL_FALSE, glm::value_ptr(view));
ASSERT_GL();
glm::mat4 model = glm::mat4(1.0f);
float angle = 45.0f;
model = glm::rotate(model, glm::radians(angle), glm::vec3(1.0f, 1.0f, 1.0f));
loc = glGetUniformLocation(program[render_mode], "model");
glUniformMatrix4fv(loc, 1, GL_FALSE, glm::value_ptr(model));
ASSERT_GL();总结
本文以实例的例子和代码讲解OpenGL的入门概念和实现步骤,附件为实现的具体代码,更复杂的知识还等待你去发现。