本讲义出自Abhishek Modi在Hadoop Summit Tokyo 2016上的演讲,主要介绍了Qubole的Hadoop技术、Qubole的架构设计、短生命周期的Hadoop集群的相关内容以及面对的挑战以及YARN的自动扩展和不断发展的HDFS技术。


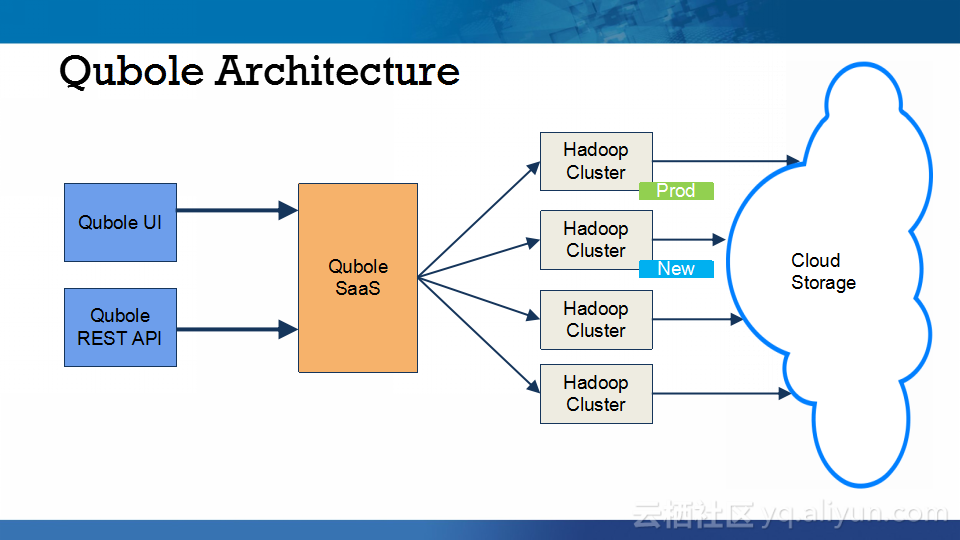
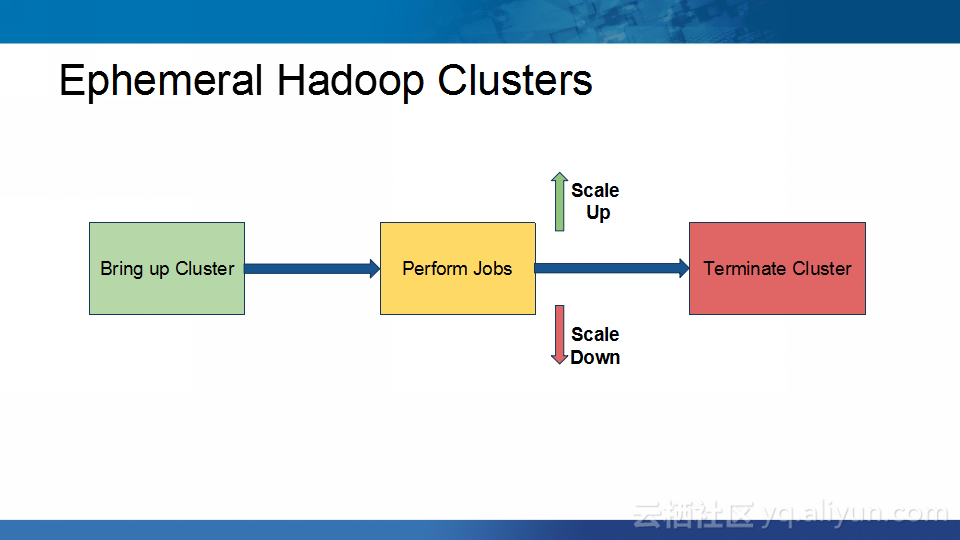


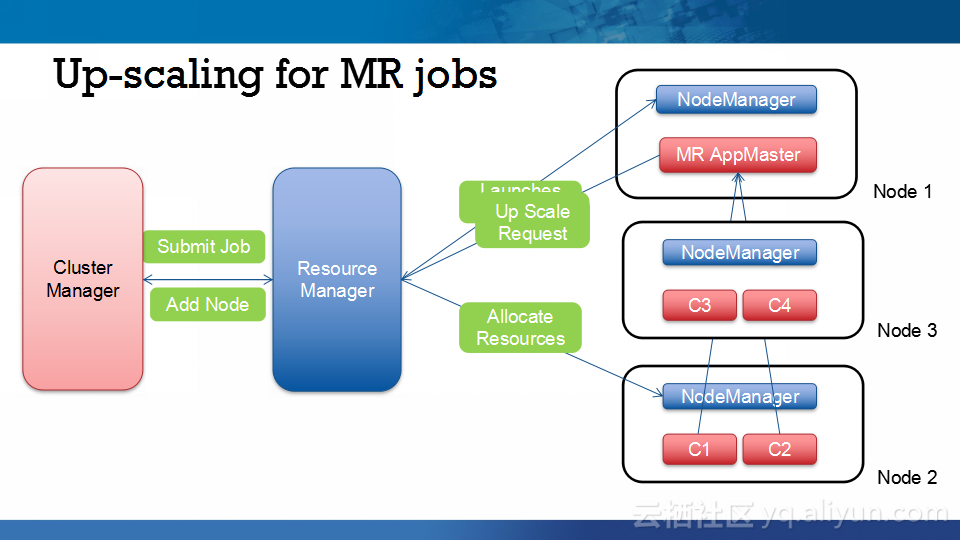
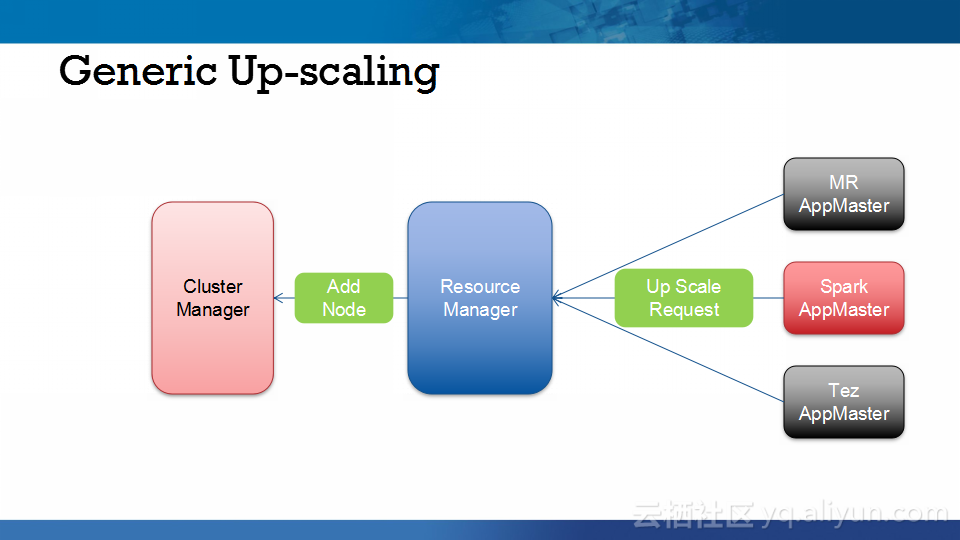
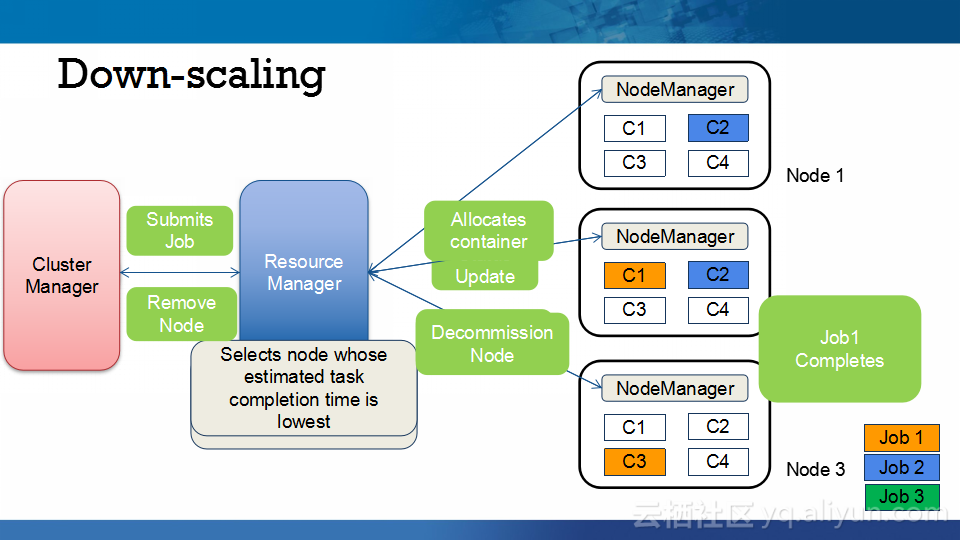
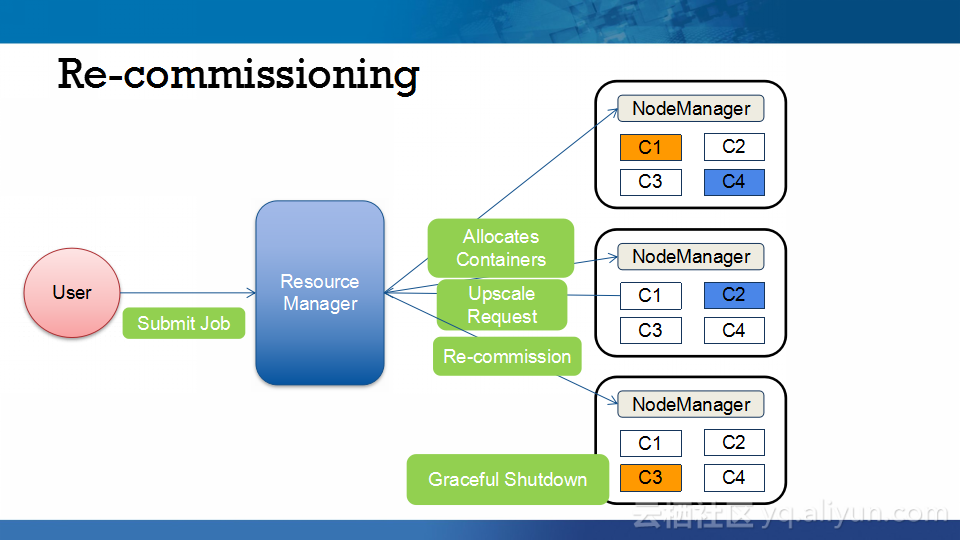


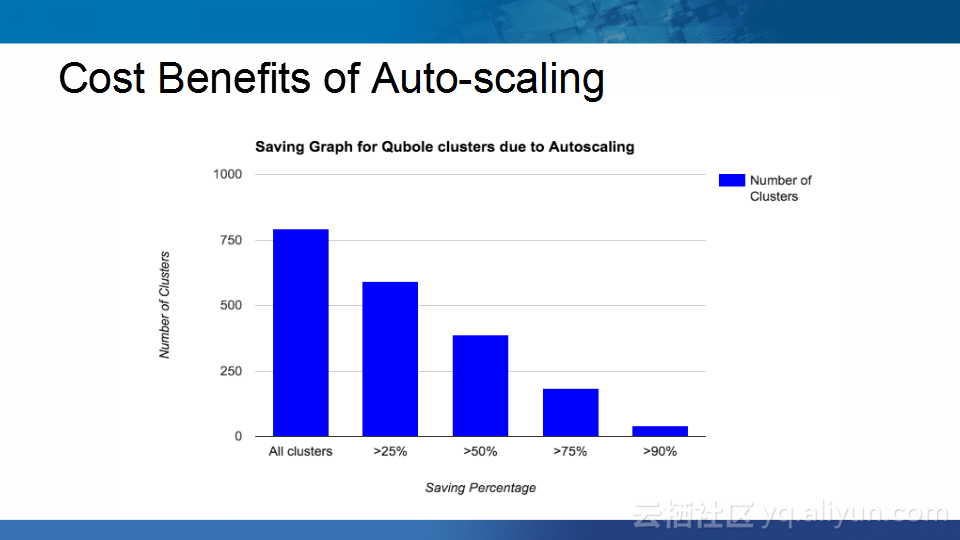




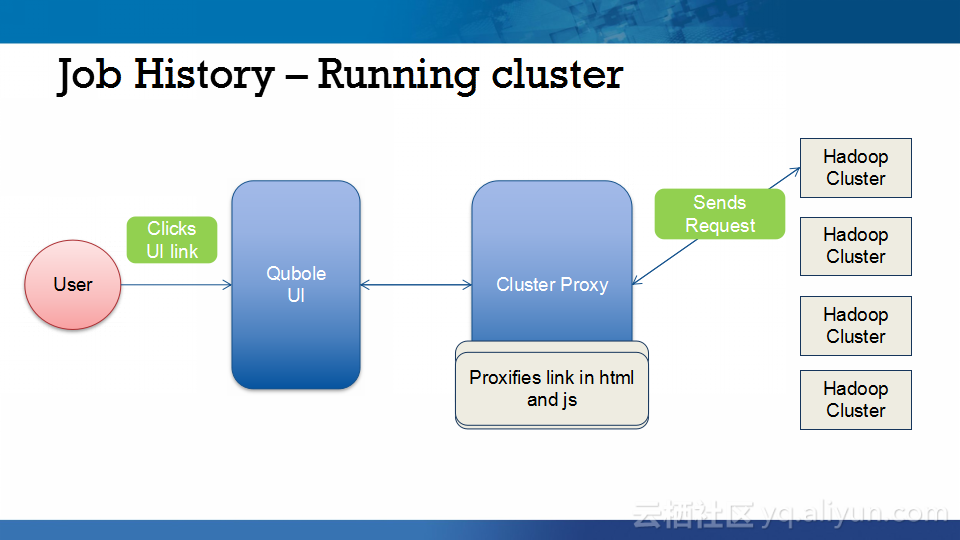
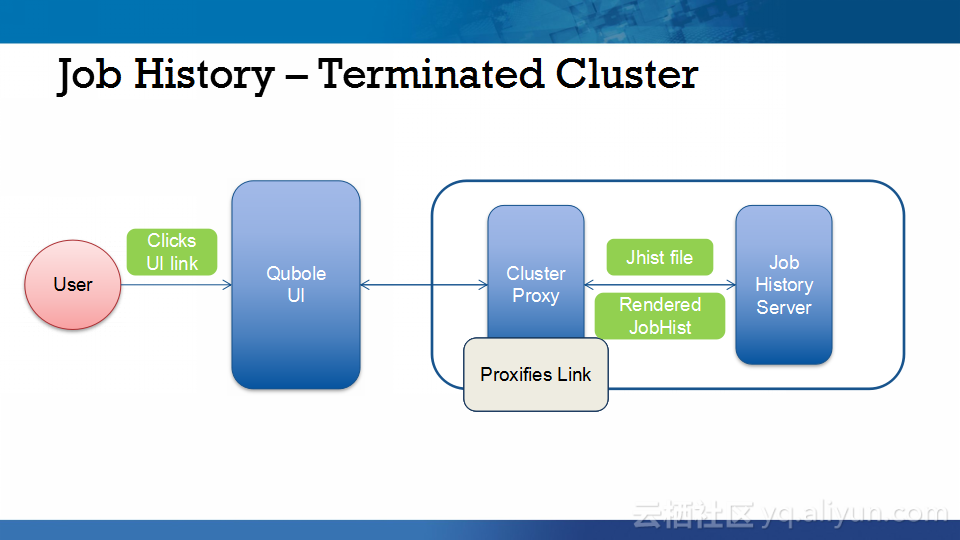



本讲义出自Abhishek Modi在Hadoop Summit Tokyo 2016上的演讲,主要介绍了Qubole的Hadoop技术、Qubole的架构设计、短生命周期的Hadoop集群的相关内容以及面对的挑战以及YARN的自动扩展和不断发展的HDFS技术。






