本讲义出自Arun Murthy在Hadoop Summit Tokyo 2016上的演讲,主要介绍了Arun Murthy与团队的从各种流使用中学习到的最佳实践和经验,演讲的内容非常简单易懂并且非常有趣,在演讲的最后还介绍了像搭乐高一样搭建Storm与Spark Streaming Pipelines块的相应工具。


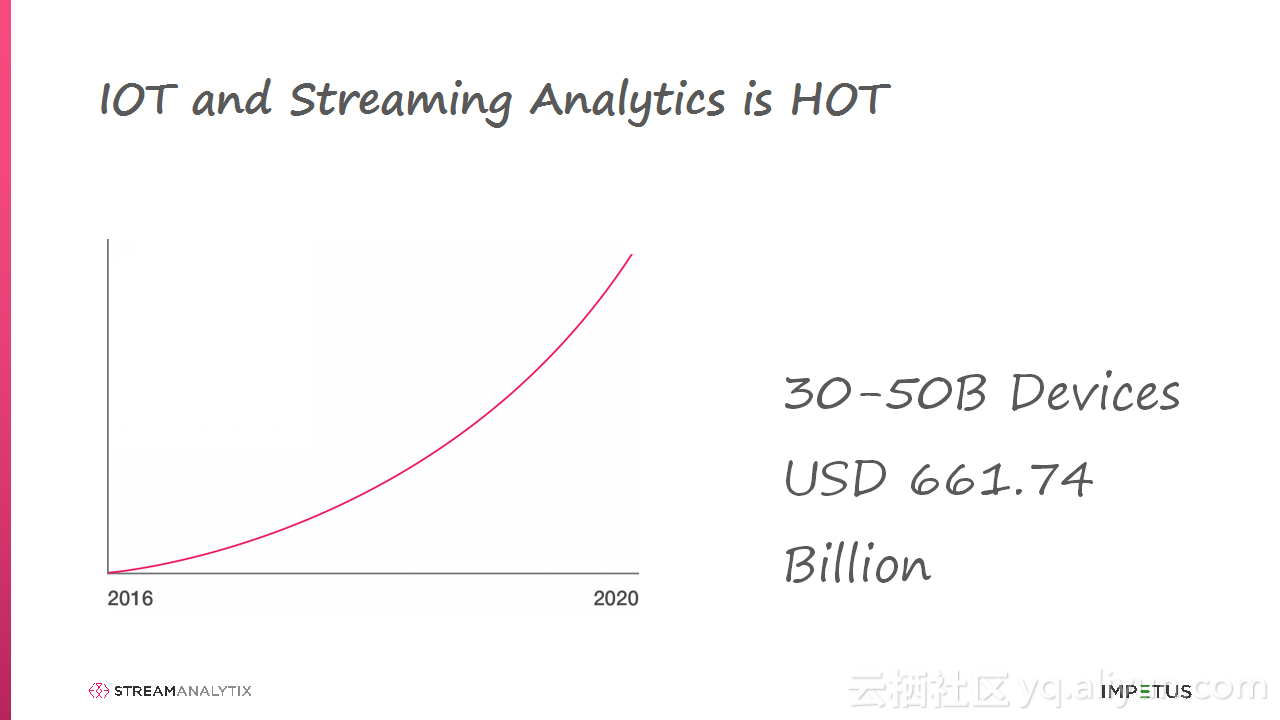




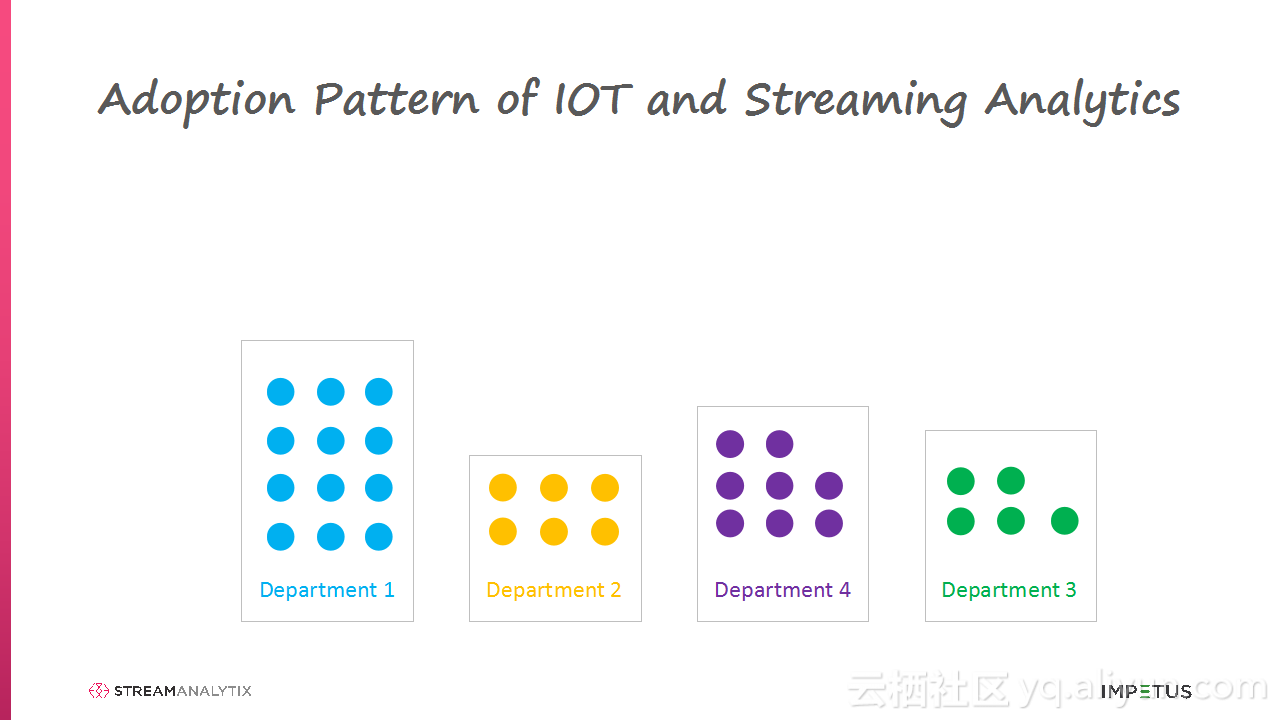
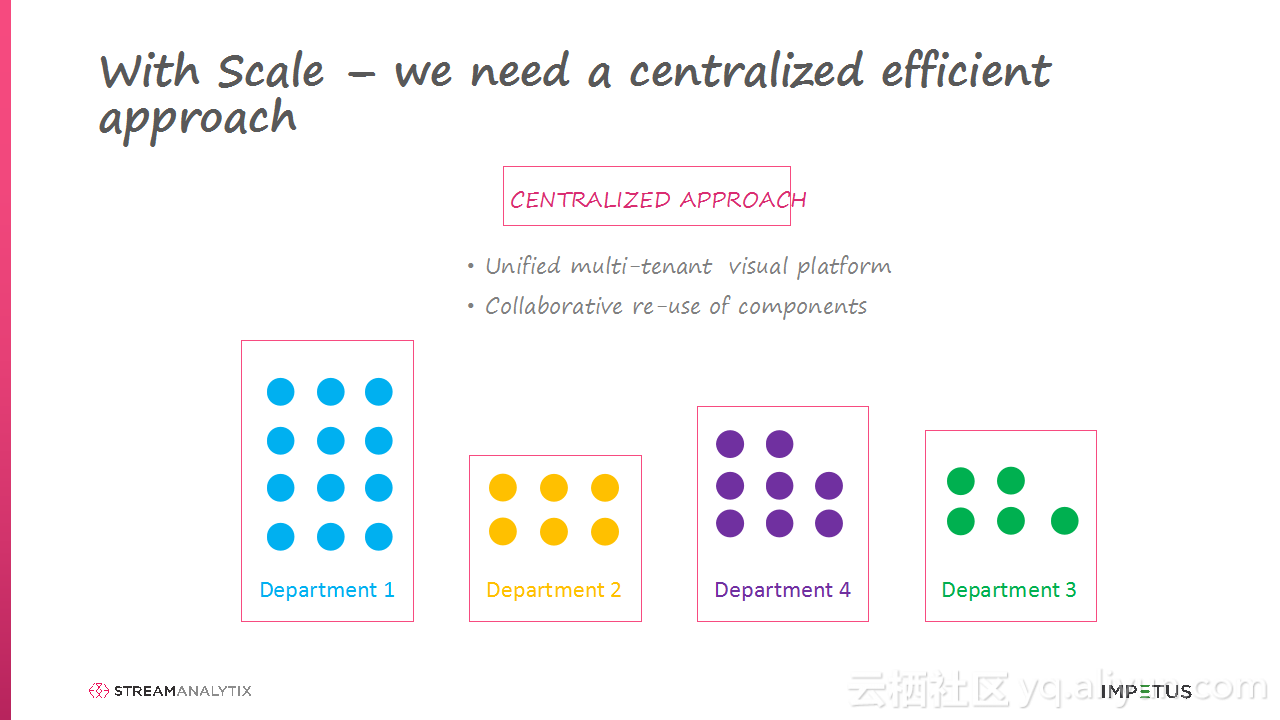


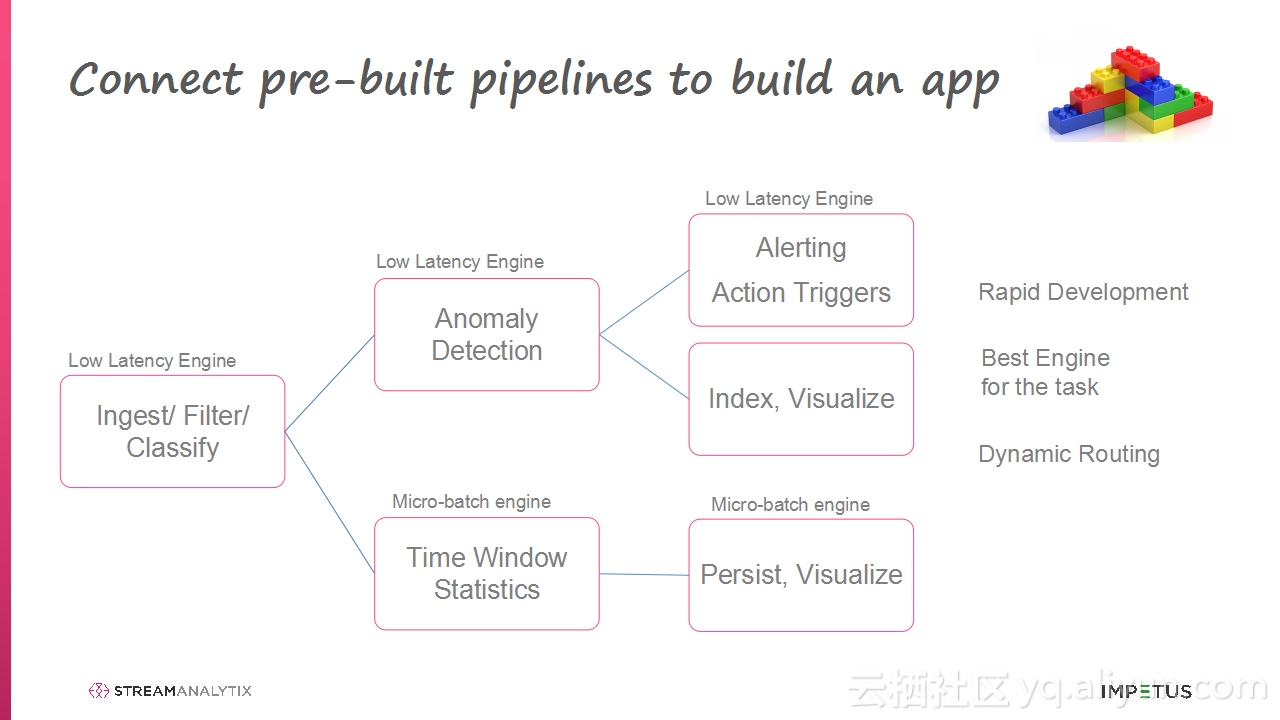


本讲义出自Arun Murthy在Hadoop Summit Tokyo 2016上的演讲,主要介绍了Arun Murthy与团队的从各种流使用中学习到的最佳实践和经验,演讲的内容非常简单易懂并且非常有趣,在演讲的最后还介绍了像搭乐高一样搭建Storm与Spark Streaming Pipelines块的相应工具。




