一.简述
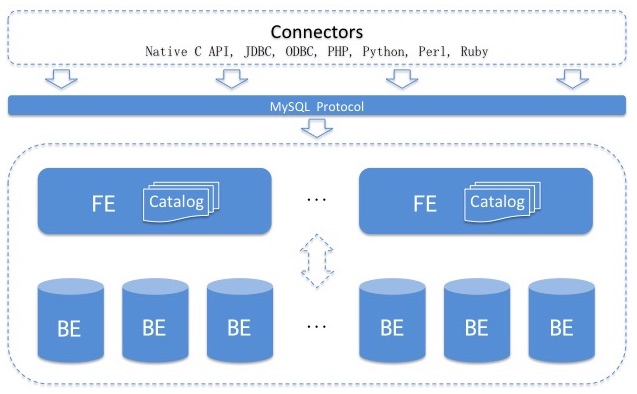
Apache Doris是由百度的Palo项目开源而来,整体架构分为两层:多个 FE 组成第一层,提供 FE 的横向扩展和高可用;多个 BE 组成第二层,负责数据存储于管理。
- FE 节点分为 follower 和 observer 两类。各个 FE 之间,通过 bdbje(BerkeleyDB Java Edition)进行 leader 选举,数据同步等工作。
- follower 节点通过选举,其中一个 follower 成为 leader 节点,负责元数据的写入操作。当 leader 节点宕机后,其他 follower 节点会重新选举出一个 leader,保证服务的高可用。
- observer 节点仅从 leader 节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
二.Kafka实时流数据
Ⅰ).创建数据表
CREATE TABLE IF NOT EXISTS datasource_name.table_name(
'id' LARGEINT NOT NULL,
'name' VARCHAR(50) NOT NULL,
'process_time' BIGINT SUM DEFAULT '0'
)
ENGINE=olap
AGGREGATE KEY('id','name')
DISTRIBUTED BY HASH('id') BUCKETS 16
PROPERTIES(
"replication_num"="2",
"storage_medium"="SSD",
"storage_cooldown_time"="2020-01-01 12:00:00"
)Ⅱ).动态插入列
drois数据库由于是列式存储,所以支持动态扩展列
ALTER TABLE datasource_name.table_name ADD COLUMN jsp_process_time BIGINT SUM DEFAULT '0' after process_time;
ALTER TABLE datasource_name.table_name ADD COLUMN ejb_process_time BIGINT SUM DEFAULT '0' after jsp_process_time;Ⅲ).查看表结构
DESC datasource_name.table_name;Ⅳ).配置Kafka routine load
CREATE ROUTINE LOAD datasource_name.kafka_load ON datasource_name.table_name
COLUMNS TERMINATED BY "|",
COLUMNS(id,name,process_time,jsp_process_time,ejb_process_time)
PROPERTIES(
"desired_concurrent_number"="3",
"max_batch_interval"="20",
"max_batch_rows"="300000",
"max_batch_size"="209715200"
)
FROM KAFKA(
"kafka_broker_list"="hostname1:9092,hostname2:9092,hostname3:9092",
"kafka_topic"="topic_name",
"kafka_partitions"="0,1,2",
"kafka_offsets"="0,0,0"
)Ⅴ).查看routine load状态
SHOW ALL ROUTINE LOAD FOR datasource_name.kafka_load;Ⅵ).常用routine load命令
a).暂停routine load
PAUSE ROUTINE LOAD FOR datasource_name.kafka_load;b).恢复routine load
RESUME ROUTINE LOAD FOR datasource_name.kafka_load;c).停止routine load
STOP ROUTINE LOAD FOR datasource_name.kafka_load;d).查看所有routine load
SHOW [ALL] ROUTINE LOAD FOR datasource_name.kafka_load;e).查看routine load任务
SHOW ROUTINE LOAD TASK datasource_name.kafka_load;Ⅶ).查看数据
SELECT * FROM datasource_name.table_name LIMIT 10;三.Apache Doris优缺点
优点
- 支持MySQL客户端的方式,查询访问数据源
- 支持数据列式存储,对数据列的动态增减方便
- BE、FE的扩容简单
- 支持在明细数据上的SUM、MIN、MAX等基本聚合统计
- 对RDBMS数据库有基础的,上手容易
缺点
- Doris编译,环境依赖重、编译过程问题多
- Doris数据格式支持较简单,不支持或json格式的数据
- 微批导入数据量不能超过1GB,而且不支持多文件同时导入
- streaming数据,需等数据streaming结束后才开始导入任务
- 导入过程中的出现异常数据会导致整个导入任务的失败(为保障数据的原子性和一致性)
- 目前社区活跃度低,基本由百度贡献