加工需求
统计类日志形式
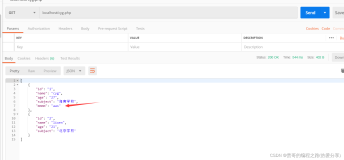
程序构建的日志经常会以一种统计性质的JSON格式写入, 通常其包含一个基础信息, 以及多个子健为数组的形式. 例如一个服务器每隔1分钟写入一条日志, 包含当前信息状态, 以及相关服务器和客户端节点的统计状态信息.
样例:
__source__: 1.2.3.4
__topic__:
content:{
"service": "search_service",
"overal_status": "yellow",
"servers": [
{
"host": "1.2.3.4",
"status": "green"
},
{
"host": "1.2.3.5",
"status": "green"
}
],
"clients": [
{
"host": "1.2.3.6",
"status": "green"
},
{
"host": "1.2.3.7",
"status": "red"
}
]
}加工需求
1、对原始日志进行topic分裂,主题主要分为三个,分别是overall_type、client_status、server_status
2、对于不同的topic保存不同的信息
- overall_type:保留server、client数量,overal_status颜色和service信息
- client_status: 保留对应的host地址、status状态和service信息
- server_status: 保留对应的host地址、status状态和service信息
期望输出的日志
期望样例中的一条日志会被分裂加工成5条日志:
__source__: 1.2.3.4
__topic__: overall_type
client_count: 2
overal_status: yellow
server_count: 2
service: search_service
__source__: 1.2.3.4
__topic__: client_status
host: 1.2.3.7
status: red
service: search_service
__source__: 1.2.3.4
__topic__: client_status
host: 1.2.3.6
status: green
service: search_service
__source__: 1.2.3.4
__topic__: server_status
host: 1.2.3.4
status: green
service: search_service
__source__: 1.2.3.4
__topic__: server_status
host: 1.2.3.5
status: green
service: search_service解决方案
初步处理
1、第一步将一条日志拆分成3条日志, 给主题赋予3个不同值, 在进行分裂,经过分裂后会分成除了topic不同,其他信息相同的三条日志。
e_set("__topic__", "server_status,client_status,overall_type")
e_split("__topic__")处理后日志格式如下(在内存中):
__source__: 1.2.3.4
__topic__: server_status // 另外2条是client_status和overall_type, 其他一样
content: {
...如前...
}2、第二步为基于content的JSON内容在第一层展开, 并删除content字段:
e_json('content',depth=1)
e_drop_fields("content")处理后的日志格式如下(在内存中):
__source__: 1.2.3.4
__topic__: overall_type // 另外2条是client_status和overall_type, 其他一样
clients: [{"host": "1.2.3.6", "status": "green"}, {"host": "1.2.3.7", "status": "red"}]
overal_status: yellow
servers: [{"host": "1.2.3.4", "status": "green"}, {"host": "1.2.3.5", "status": "green"}]
service: search_service 处理overall_type日志
- 针对主题是overall_type的日志, 统计client_count和server_count:
e_if(e_search("__topic__==overall_type"),
e_compose(
e_set("client_count" json_select(v("clients"), "length([*])", default=0)),
e_set("server_count" json_select(v("servers"), "length([*])", default=0))
))处理后的日志为(仅显示修改部分):
__topic__: overall_type
server_count: 2
client_count: 2- 丢弃相关字段:
e_if(e_search("__topic__==overall_type"), e_drop_fields("clients", "servers"))处理server_status日志
- 针对主题是server_status的日志, 进行进一步分裂.
e_if(e_search("__topic__==server_status"),
e_compose(
e_split("servers"),
e_json("servers", depth=1)
))处理后的日志为2条如下(仅显示修改部分):
__topic__: server_status
servers: {"host": "1.2.3.4", "status": "green"}
host: 1.2.3.4
status: green和
__topic__: server_status
servers: {"host": "1.2.3.5", "status": "green"}
host: 1.2.3.5
status: green- 保留相关字段:
e_if(e_search("__topic__==overall_type"), e_drop_fields("servers"))处理client_status日志
- 同理, 针对主题是client_status的日志, 进行进一步分裂, 在删除多余字段.
e_if(e_search("__topic__==client_status"),
e_compose(
e_split("clients"),
e_json("clients", depth=1),
e_drop_fields("clients")
))处理后的日志为2条如下(仅显示修改部分):
__topic__: client_status
host: 1.2.3.6
status: green和
__topic__: clients
host: 1.2.3.7
status: red综合
综上,LOG DSL规则是
# 总体分裂
e_set("__topic__", "server_status,client_status,overall_type")
e_split("__topic__")
e_json('content',depth=1)
e_drop_fields("content")
# 处理overall_type日志
e_if(e_search("__topic__==overall_type"),
e_compose(
e_set("client_count" json_select(v("clients"), "length([*])", default=0)),
e_set("server_count" json_select(v("servers"), "length([*])", default=0))
))
# 处理server_status日志
e_if(e_search("__topic__==server_status"),
e_compose(
e_split("servers"),
e_json("servers", depth=1)
))
e_if(e_search("__topic__==overall_type"), e_drop_fields("servers"))
# 处理client_status日志
e_if(e_search("__topic__==client_status"),
e_compose(
e_split("clients"),
e_json("clients", depth=1),
e_drop_fields("clients")
))方案优化
一个边界问题
注意到以上方案对于content.servers和content.servers是空时的处理有一些问题,
假设原始日志是:
__source__: 1.2.3.4
__topic__:
content:{
"service": "search_service",
"overal_status": "yellow",
"servers": [ ],
"clients": [ ]
}会被分裂为3条日志, 其中主题是client_status和server_status的日志内容是空的.
__source__: 1.2.3.4
__topic__: overall_type
client_count: 0
overal_status: yellow
server_count: 0
service: search_service
__source__: 1.2.3.4
__topic__: client_status
service: search_service
__source__: 1.2.3.4
__topic__: server_status
host: 1.2.3.4
status: green
service: search_service
方案1
这里可以在初始分裂后, 处理server_status和client_status日志前分别判断并丢弃空的相关事件:
# 处理server_status: 空的丢弃(非空保留)
e_keep(op_and(e_search("__topic__==server_status"), json_select(v("servers"), "length([*])")))
# 处理client_status: 空的丢弃(非空保留)
e_keep(op_and(e_search("__topic__==client_status"), json_select(v("clients"), "length([*])")))综合
综上,LOG DSL规则是
# 总体分裂
e_set("__topic__", "server_status,client_status,overall_type")
e_split("__topic__")
e_json('content',depth=1)
e_drop_fields("content")
# 处理overall_type日志
e_if(e_search("__topic__==overall_type"),
e_compose(
e_set("client_count" json_select(v("clients"), "length([*])", default=0)),
e_set("server_count" json_select(v("servers"), "length([*])", default=0))
))
# 新加: 预处理server_status: 空的丢弃(非空保留)
e_keep(op_and(e_search("__topic__==server_status"), json_select(v("servers"), "length([*])")))
# 处理server_status日志
e_if(e_search("__topic__==server_status"),
e_compose(
e_split("servers"),
e_json("servers", depth=1)
))
e_if(e_search("__topic__==overall_type"), e_drop_fields("servers"))
# 新加: 预处理client_status: 空的丢弃(非空保留)
e_keep(op_and(e_search("__topic__==client_status"), json_select(v("clients"), "length([*])")))
# 处理client_status日志
e_if(e_search("__topic__==client_status"),
e_compose(
e_split("clients"),
e_json("clients", depth=1),
e_drop_fields("clients")
))方案2
在初始分裂时进行判断, 如果对应数据是空的就不分裂出更多事件:
# 初始主题
e_set("__topic__", "server_status")
# 如果content.servers非空, 则从server_status分裂出1条日志
e_if(json_select(v("content"), "length(servers[*])"),
e_compse(
e_set("__topic__", "server_status,overall_type"),
e_split("__topic__")
))
# 如果content.clients非空, 则从overall_type再分裂出1条日志
e_if(op_and(e_search("__topic__==overall_type"), json_select(v("content"), "length(clients[*])")),
e_compse(
e_set("__topic__", "client_status,overall_type"),
e_split("__topic__")
))综合
综上,LOG DSL规则是
# 总体分裂
e_set("__topic__", "server_status")
# 如果content.servers非空, 则从server_status分裂出1条日志
e_if(json_select(v("content"), "length(servers[*])"),
e_compse(
e_set("__topic__", "server_status,overall_type"),
e_split("__topic__")
))
# 如果content.clients非空, 则从server_status分裂出1条日志
e_if(op_and(e_search("__topic__==overall_type"), json_select(v("content"), "length(clients[*])")),
e_compse(
e_set("__topic__", "client_status,overall_type"),
e_split("__topic__")
))
# 处理overall_type日志
e_if(e_search("__topic__==overall_type"),
e_compose(
e_set("client_count" json_select(v("clients"), "length([*])", default=0)),
e_set("server_count" json_select(v("servers"), "length([*])", default=0))
))
# 处理server_status日志
e_if(e_search("__topic__==server_status"),
e_compose(
e_split("servers"),
e_json("servers", depth=1)
))
e_if(e_search("__topic__==overall_type"), e_drop_fields("servers"))
# 处理client_status日志
e_if(e_search("__topic__==client_status"),
e_compose(
e_split("clients"),
e_json("clients", depth=1),
e_drop_fields("clients")
))比较
方案1会在分裂出日志后再删除, 逻辑上有些多余, 但规则简单易维护. 默认推荐.
方案2会在分裂前进行判断, 处理效率会高一些, 但规则略微冗余, 仅在特定场景(例如初始分裂可能导致大量额外事件产生)时推荐.
进一步参考
欢迎扫码加入官方钉钉群获得实时更新与阿里云工程师的及时直接的支持: