作者:
陶克路,花名敌珐,阿里巴巴技术专家。Apache Pulsar 等开源软件 Contributor。技术领域包括大数据和云原生技术栈,目前致力于构建大数据领域业界领先的 APM 产品。
云原生时代,Kubernetes 的重要性日益凸显,这篇文章以 Spark 为例来看一下大数据生态 on Kubernetes 生态的现状与挑战。
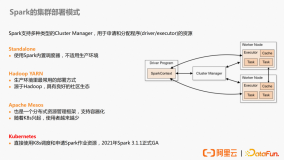
1. Standalone 模式
Spark 运行在 Kubernetes 集群上的第一种可行方式是将 Spark 以 Standalone 模式运行,但是很快社区就提出使用 Kubernetes 原生 Scheduler 的运行模式,也就是 Native 的模式。关于 Standalone 模式这里就没有继续讨论的必要了。
2. Kubernetes Native 模式
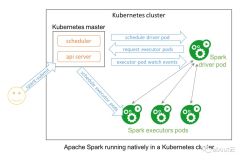
Native 模式简而言之就是将 Driver 和 Executor Pod 化,用户将之前向 YARN 提交 Spark 作业的方式提交给 Kubernetes 的 apiserver,提交命令如下:
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
local:///path/to/examples.jar其中 master 就是 kubernetes 的 apiserver 地址。提交之后整个作业的运行方式如下,先将 Driver 通过 Pod 启动起来,然后 Driver 会启动 Executor 的 Pod。这些方式很多人应该都了解了,就不赘述了,详细信息可以参考:https://spark.apache.org/docs/latest/running-on-kubernetes.html 。

3. Spark Operator
除了这种直接想 Kubernetes Scheduler 提交作业的方式,还可以通过 Spark Operator 的方式来提交。Operator 在 Kubernetes 中是一个非常重要的里程碑。在 Kubernetes 刚面世的时候,关于有状态的应用如何部署在 Kubernetes 上一直都是官方不愿意谈论的话题,直到 StatefulSet 出现。StatefulSet 为有状态应用的部署实现了一种抽象,简单来说就是保证网络拓扑和存储拓扑。但是状态应用千差万别,并不是所有应用都能抽象成 StatefulSet,强行适配反正加重了开发者的心智负担。
然后 Operator 出现了。我们知道 Kubernetes 给开发者提供了非常开放的一种生态,你可以自定义 CRD,Controller 甚至 Scheduler。而 Operator 就是 CRD + Controller 的组合形式。开发者可以定义自己的 CRD,比如我定义一种 CRD 叫 EtcdCluster 如下:
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.1.10"
repository: "quay.io/coreos/etcd"提交到 Kubernetes 之后 Etcd 的 Operator 就针对这个 yaml 中的各个字段进行处理,最后部署出来一个节点规模为 3 个节点的 etcd 集群。你可以在 github 的这个 repo:https://github.com/operator-framework/awesome-operators 中查看目前实现了 Operator 部署的分布式应用。
Google 云平台,也就是 GCP 在 github 上面开源了 Spark 的 Operator,repo 地址:。Operator 部署起来也是非常的方便,使用 Helm Chart 方式部署如下,你可以简单认为就是部署一个 Kubernetes 的 API Object (Deployment)。
$ helm install incubator/sparkoperator --namespace spark-operator这个 Operator 涉及到的 CRD 如下:
|__ ScheduledSparkApplicationSpec
|__ SparkApplication
|__ ScheduledSparkApplicationStatus
|__ SparkApplication
|__ SparkApplicationSpec
|__ DriverSpec
|__ SparkPodSpec
|__ ExecutorSpec
|__ SparkPodSpec
|__ Dependencies
|__ MonitoringSpec
|__ PrometheusSpec
|__ SparkApplicationStatus
|__ DriverInfo 如果我要提交一个作业,那么我就可以定义如下一个 SparkApplication 的 yaml,关于 yaml 里面的字段含义,可以参考上面的 CRD 文档。
kind: SparkApplication
metadata:
...
spec:
deps: {}
driver:
coreLimit: 200m
cores: 0.1
labels:
version: 2.3.0
memory: 512m
serviceAccount: spark
executor:
cores: 1
instances: 1
labels:
version: 2.3.0
memory: 512m
image: gcr.io/ynli-k8s/spark:v2.4.0
mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.11-2.3.0.jar
mainClass: org.apache.spark.examples.SparkPi
mode: cluster
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
type: Scala
status:
sparkApplicationId: spark-5f4ba921c85ff3f1cb04bef324f9154c9
applicationState:
state: COMPLETED
completionTime: 2018-02-20T23:33:55Z
driverInfo:
podName: spark-pi-83ba921c85ff3f1cb04bef324f9154c9-driver
webUIAddress: 35.192.234.248:31064
webUIPort: 31064
webUIServiceName: spark-pi-2402118027-ui-svc
webUIIngressName: spark-pi-ui-ingress
webUIIngressAddress: spark-pi.ingress.cluster.com
executorState:
spark-pi-83ba921c85ff3f1cb04bef324f9154c9-exec-1: COMPLETED
LastSubmissionAttemptTime: 2018-02-20T23:32:27Z提交作业。
对比来看 Operator 的作业提交方式似乎显得更加的冗长复杂,但是这也是一种更 kubernetes 化的 api 部署方式,也就是 Declarative API,声明式 API。
4. 挑战
基本上,目前市面的大部门公司都是使用上面两种方式来做 Spark on Kubernetes 的,但是我们也知道在 Spark Core 里面对 Kubernetes 的这种 Native 方式支持其实并不是特别成熟,还有很多可以改善的地方:
4.1 scheduler 差异。
资源调度器可以简单分类成集中式资源调度器和两级资源调度器。两级资源调度器有一个中央调度器负责宏观资源调度,对于某个应用的调度则由下面分区资源调度器来做。两级资源调度器对于大规模应用的管理调度往往能有一个良好的支持,比如性能方面,缺点也很明显,实现复杂。其实这种设计思想在很多地方都有应用,比如内存管理里面的 tcmalloc 算法,Go 语言的内存管理实现。大数据的资源调度器 Mesos/Yarn,某种程度上都可以归类为两级资源调度器。
集中式资源调度器对于所有的资源请求进行响应和决策,这在集群规模大了之后难免会导致一个单点瓶颈,毋庸置疑。但是 Kubernetes 的 scheduler 还有一点不同的是,它是一种升级版,一种基于共享状态的集中式资源调度器。Kubernetes 通过将整个集群的资源缓存到 scheduler 本地,在进行资源调度的时候在根据缓存的资源状态来做一个 “乐观” 分配(assume + commit)来实现调度器的高性能。
Kubernetes 的默认调度器在某种程度上并不能很好的 match Spark 的 job 调度需求,对此一种可行的技术方案是再提供一种 custom scheduler,比如 Spark on Kubernetes Native 方式的参与者之一的大数据公司 Palantir 就开源了他们的 custom scheduler,github repo: https://github.com/palantir/k8s-spark-scheduler。
4.2 集群规模瓶颈。
基本上现在可以确定的是 Kubernetes 会在集群规模达到五千台的时候出现瓶颈,但是在很早期的时候 Spark 发表论文的时候就声称 Spark Standalone 模式可以支持一万台规模。Kubernetes 的瓶颈主要体现在 master 上,比如用来做元数据存储的基于 raft 一致性协议的 etcd 和 apiserver 等。对此在刚过去的 2019 上海 KubeCon 大会上,阿里巴巴做了一个关于提高 master 性能的 session: 了解 Kubernetes Master 的可扩展性和性能,感兴趣的可以自行了解。
4.3 Pod 驱逐(Eviction)问题。
在 Kubernetes 中,资源分为可压缩资源(比如 CPU)和不可压缩资源(比如内存),当不可压缩资源不足的时候就会将一些 Pod 驱逐出当前 Node 节点。国内某个大厂在使用 Spark on kubernetes 的时候就遇到因为磁盘 IO 不足导致 Spark 作业失败,从而间接导致整个测试集都没有跑出来结果。如何保证 Spark 的作业 Pod (Driver/Executor) 不被驱逐呢?这就涉及到优先级的问题,1.10 之后开始支持。但是说到优先级,有一个不可避免的问题就是如何设置我们的应用的优先级?常规来说,在线应用或者 long-running 应用优先级要高于 batch job,但是显然对于 Spark 作业来说这并不是一种好的方式。
4.4 作业日志。
Spark on Yarn 的模式下,我们可以将日志进行 aggregation 然后查看,但是在 Kubernetes 中暂时还是只能通过 Pod 的日志查看,这块如果要对接 Kubernetes 生态的话可以考虑使用 fluentd 或者 filebeat 将 Driver 和 Executor Pod 的日志汇总到 ELK 中进行查看。
4.5 Prometheus 生态。
Prometheus 作为 CNCF 毕业的第二个项目,基本是 Kubernetes 监控的标配,目前 Spark 并没有提供 Prometheus Sink。而且 Prometheus 的数据读取方式是 pull 的方式,对于 Spark 中 batch job 并不适合使用 pull 的方式,可能需要引入 Prometheus 的 pushgateway。
5. 结语
被称为云上 OS 的 Kubernetes 是 Cloud Native 理念的一种技术承载与体现,但是如何通过 Kubernetes 来助力大数据应用还是有很多可以探索的地方。欢迎交流。
6. 参考:
- https://spark.apache.org/docs/latest/running-on-kubernetes.html
- https://medium.com/palantir/spark-scheduling-in-kubernetes-4976333235f3
- https://github.com/palantir/k8s-spark-scheduler
- Kubecon: 了解 Kubernetes Master 的可扩展性和性能
- Kubecon: SIG-Scheduling Deep Dive
- https://github.com/operator-framework/awesome-operators
- https://github.com/coreos/etcd-operator