本讲义出自Robert Hryniewicz在Hadoop Summit Tokyo 2016上的演讲,主要介绍了数据科学以及机器学习的相关基本概念以及机器学习的例子,并分享了机器学习的方法,还分享了K-means的聚类方法、决策树以及随机森林等相关知识。




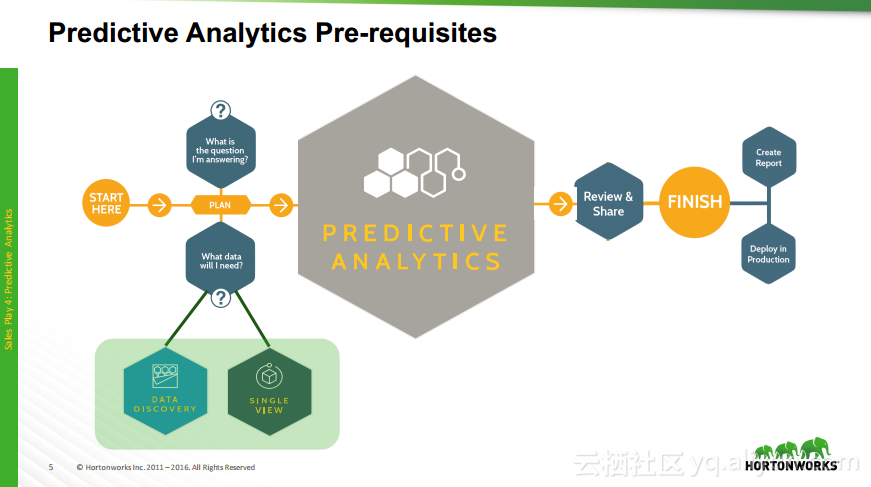
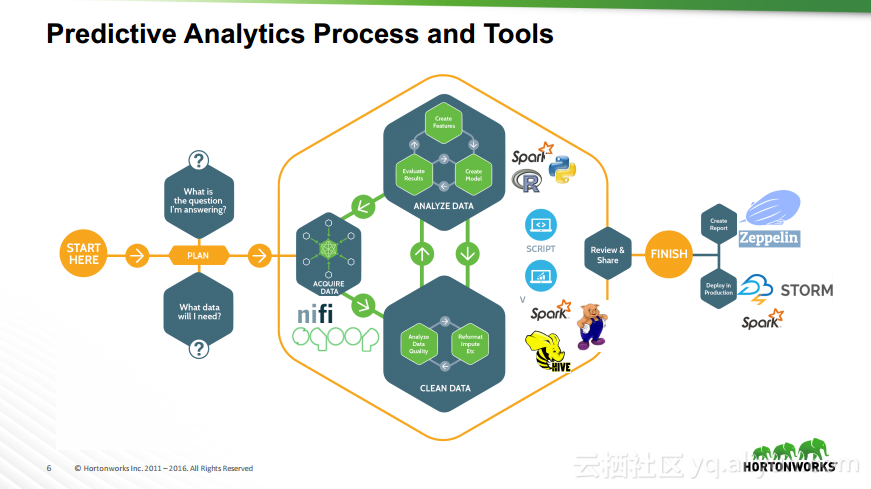
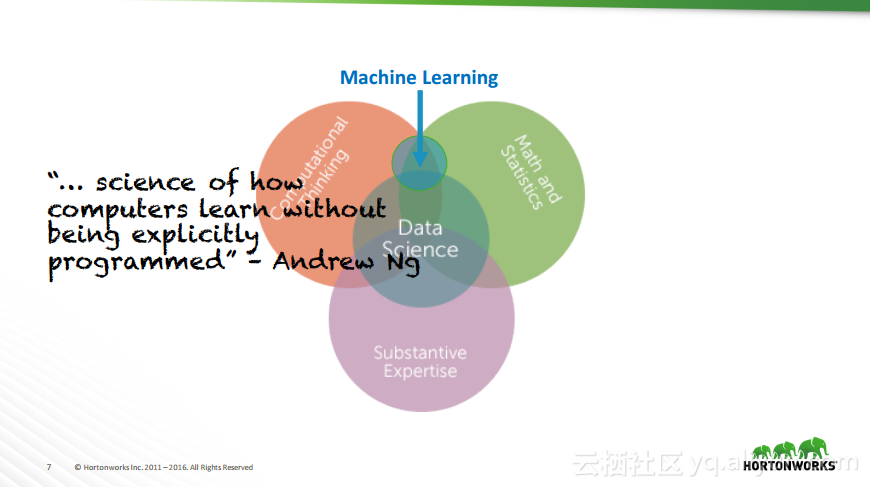


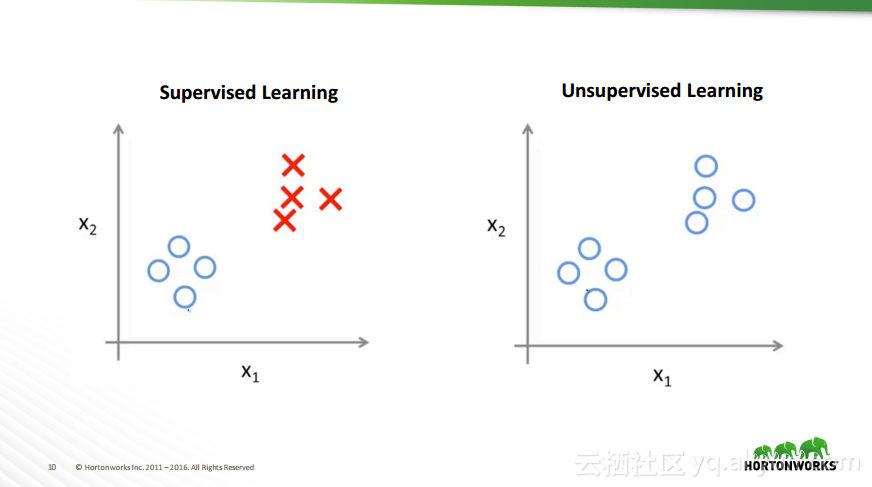











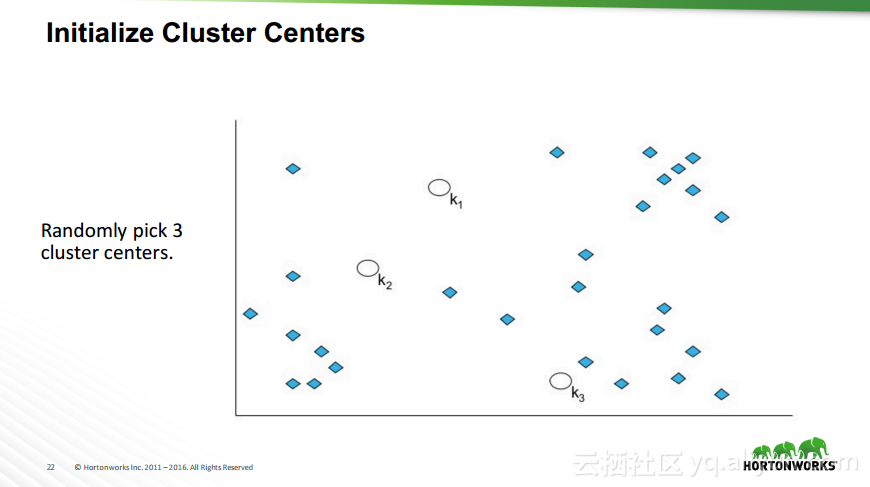
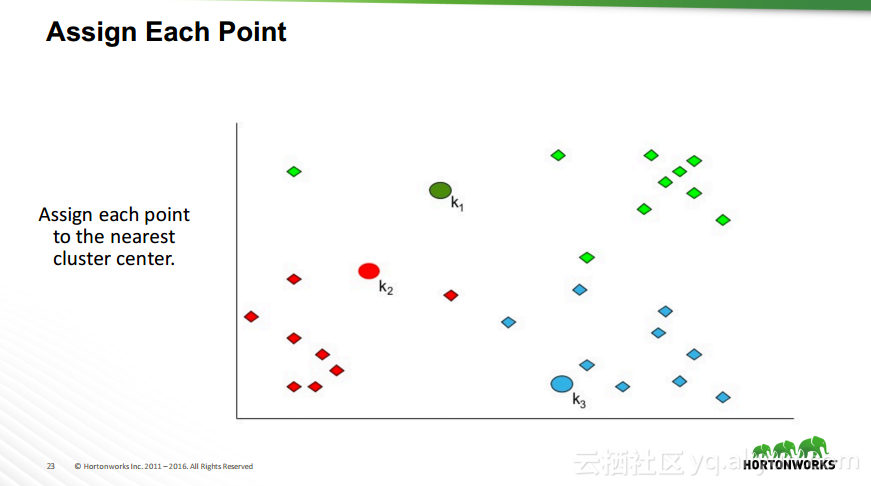
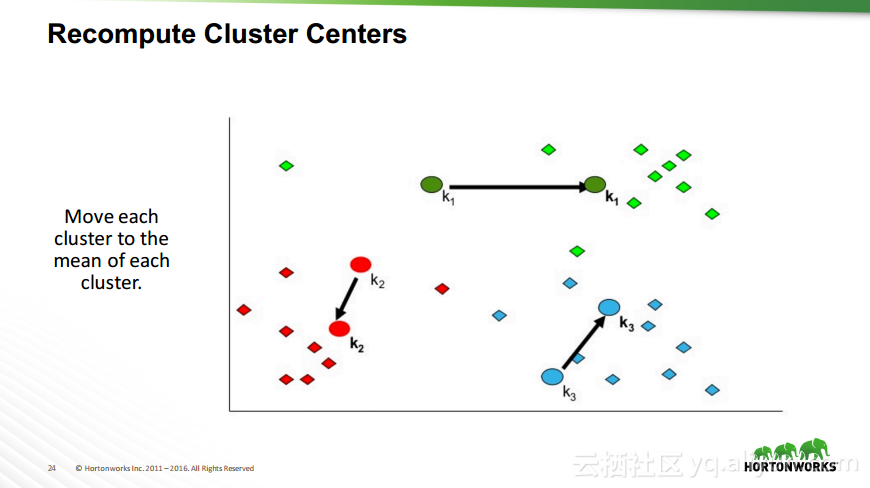

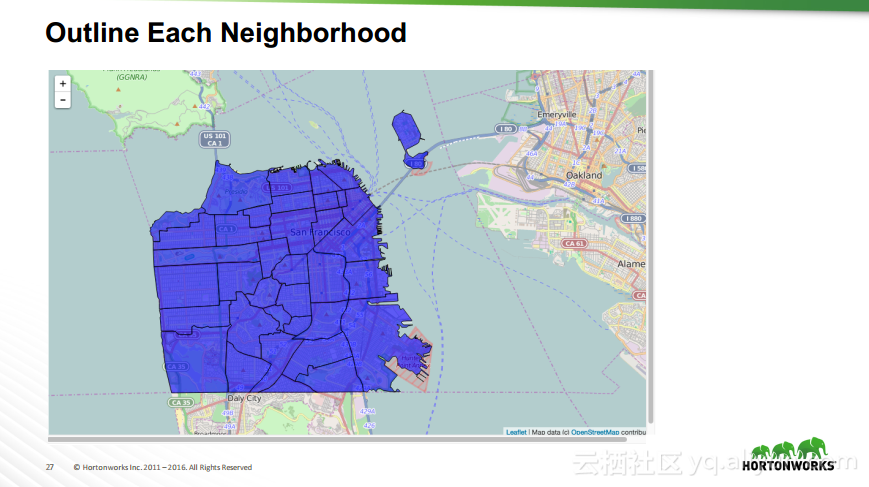
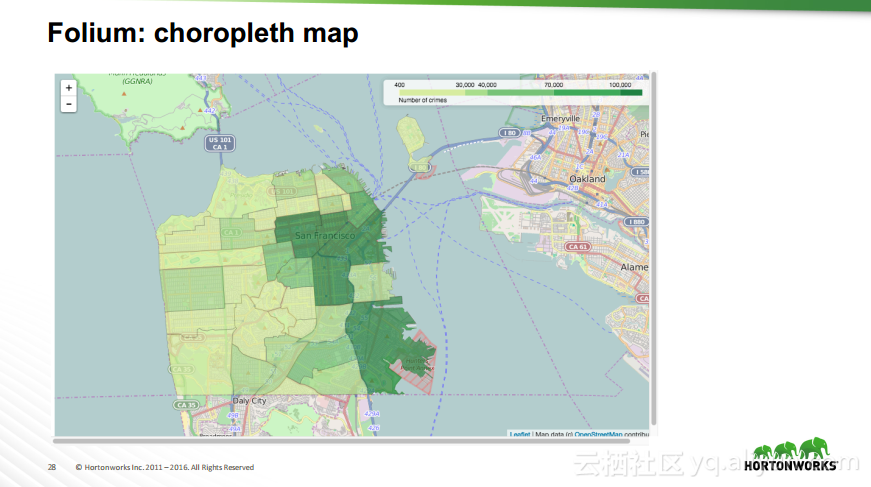
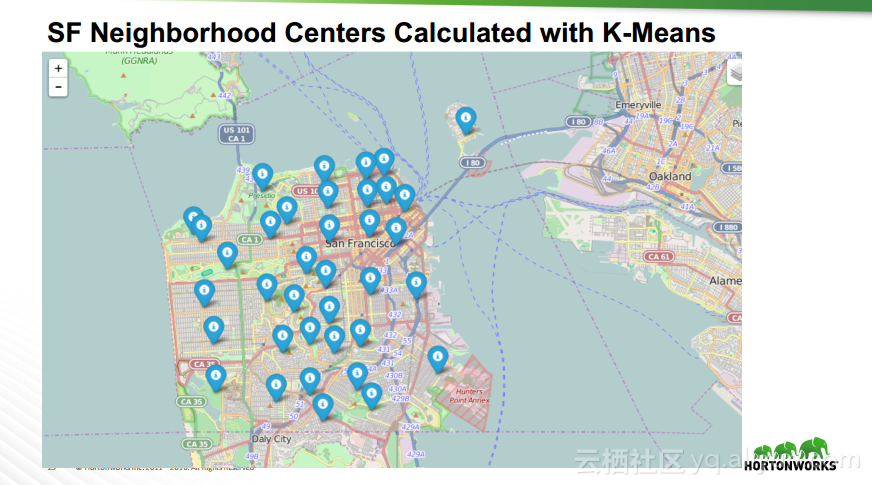
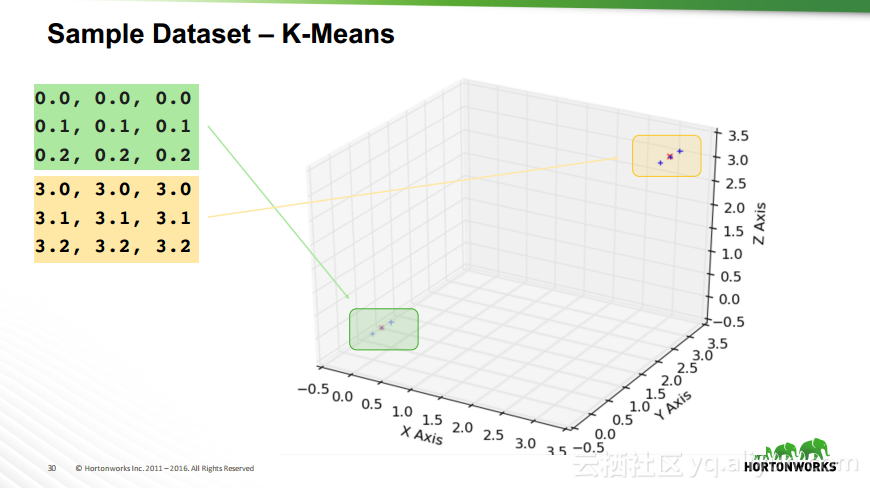



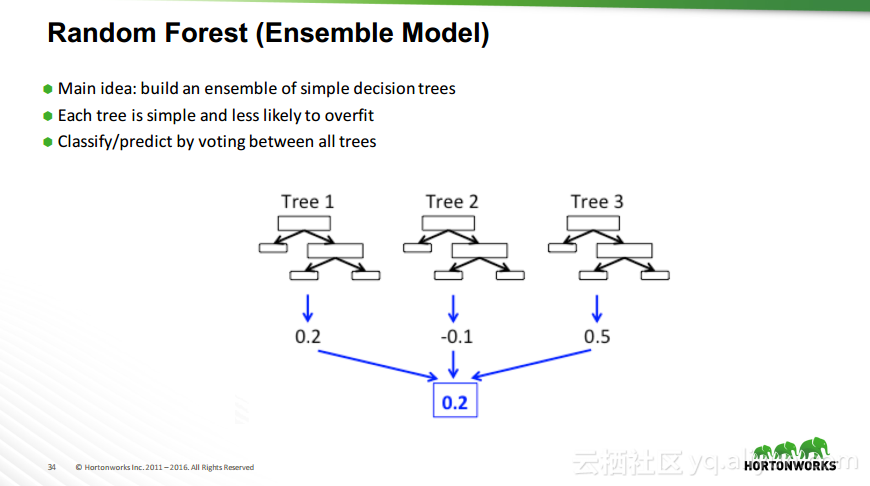
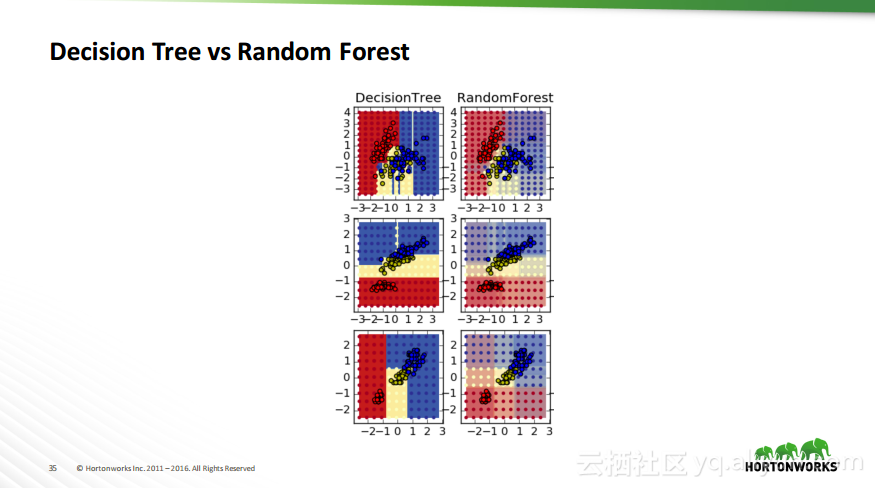
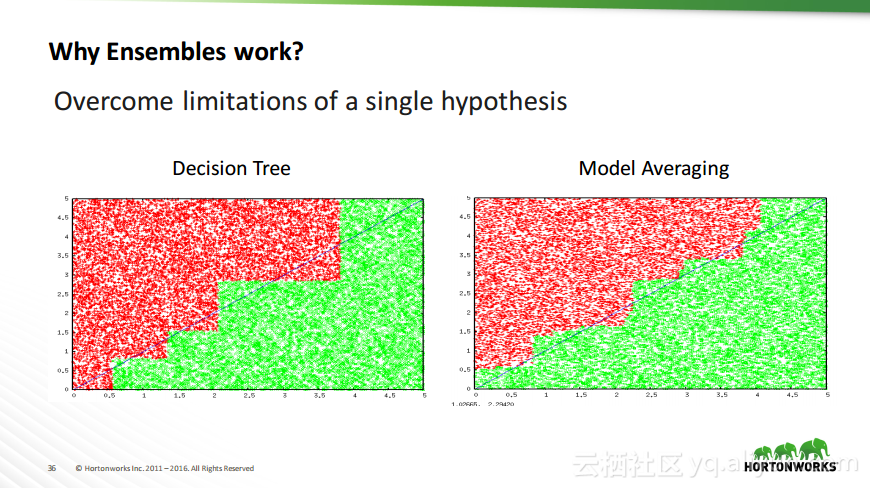


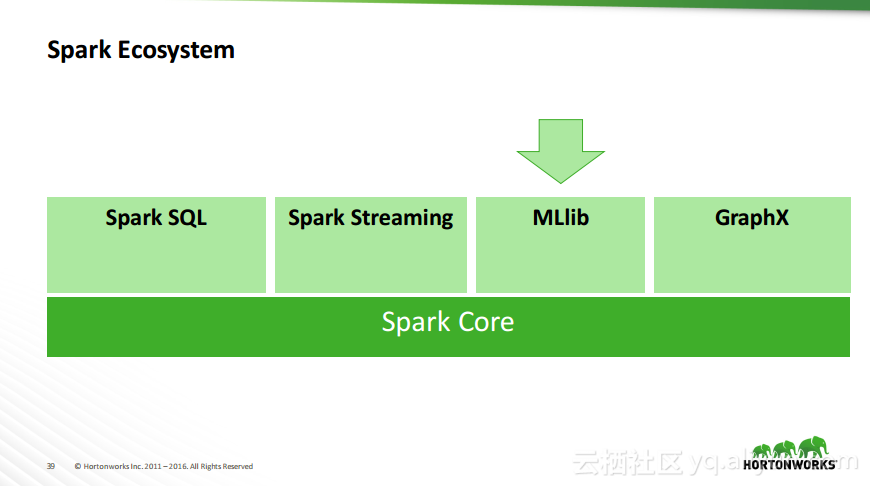
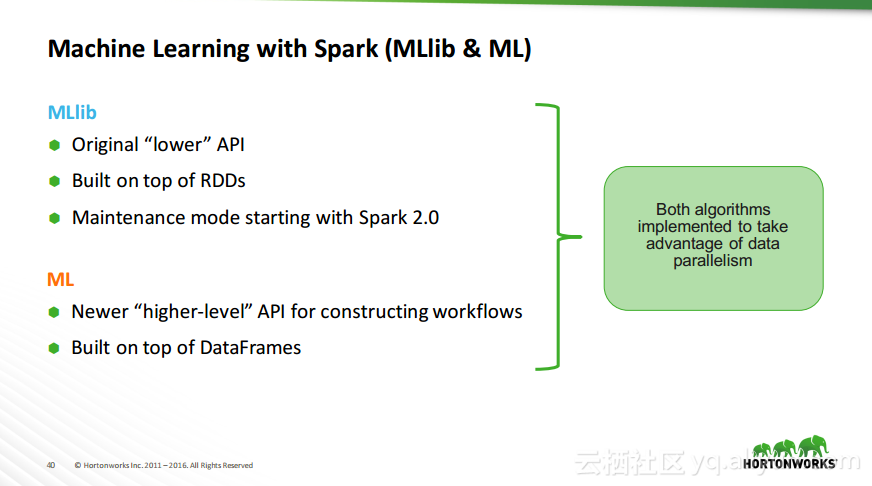
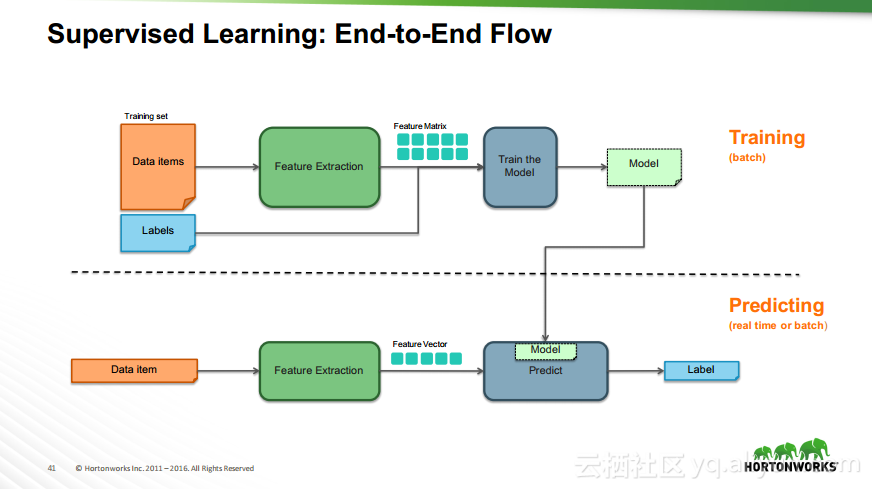
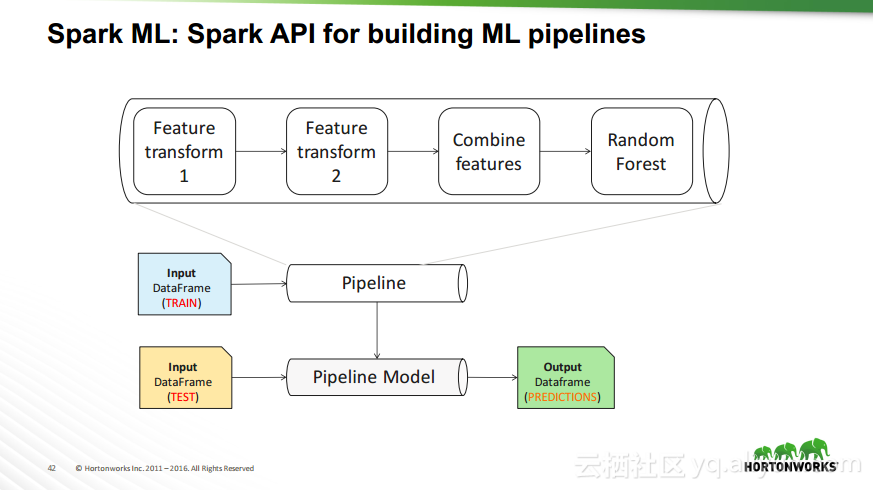
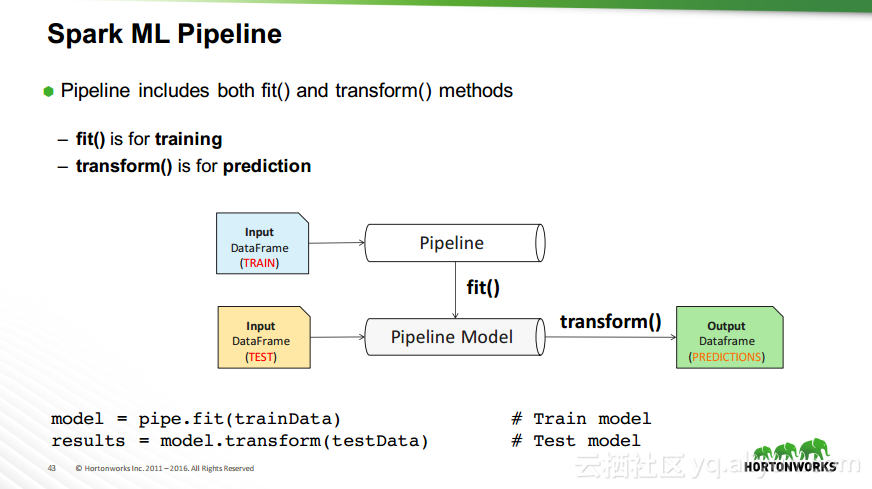


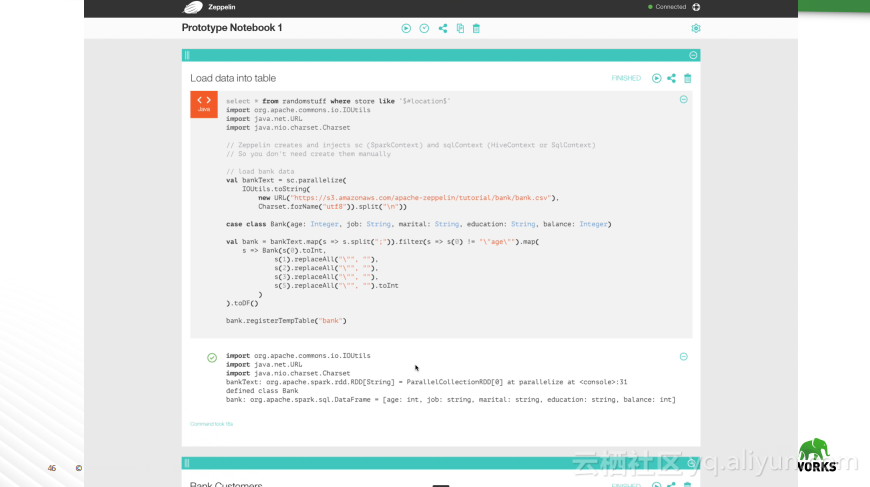





本讲义出自Robert Hryniewicz在Hadoop Summit Tokyo 2016上的演讲,主要介绍了数据科学以及机器学习的相关基本概念以及机器学习的例子,并分享了机器学习的方法,还分享了K-means的聚类方法、决策树以及随机森林等相关知识。
