本讲义出自Shwetha Shivalingamurthy与Suma Shivaprasad在Hadoop Summit Tokyo 2016上的演讲,主要分享了企业数据分类和治理的案例并且深入地讲解了大数据治理的相关内容,并介绍了Atlas的概览和架构设计以及其特性和发展路线。




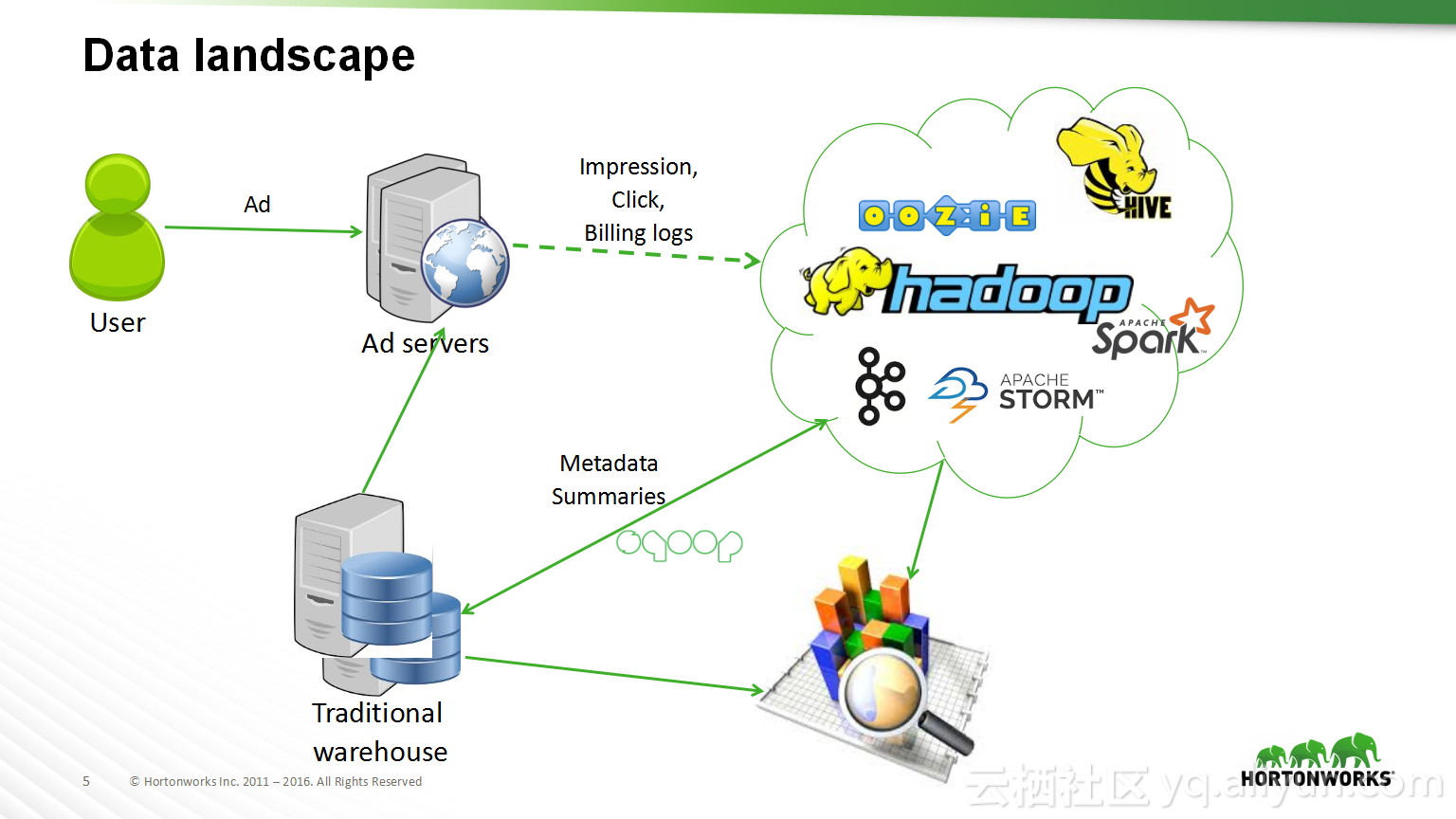


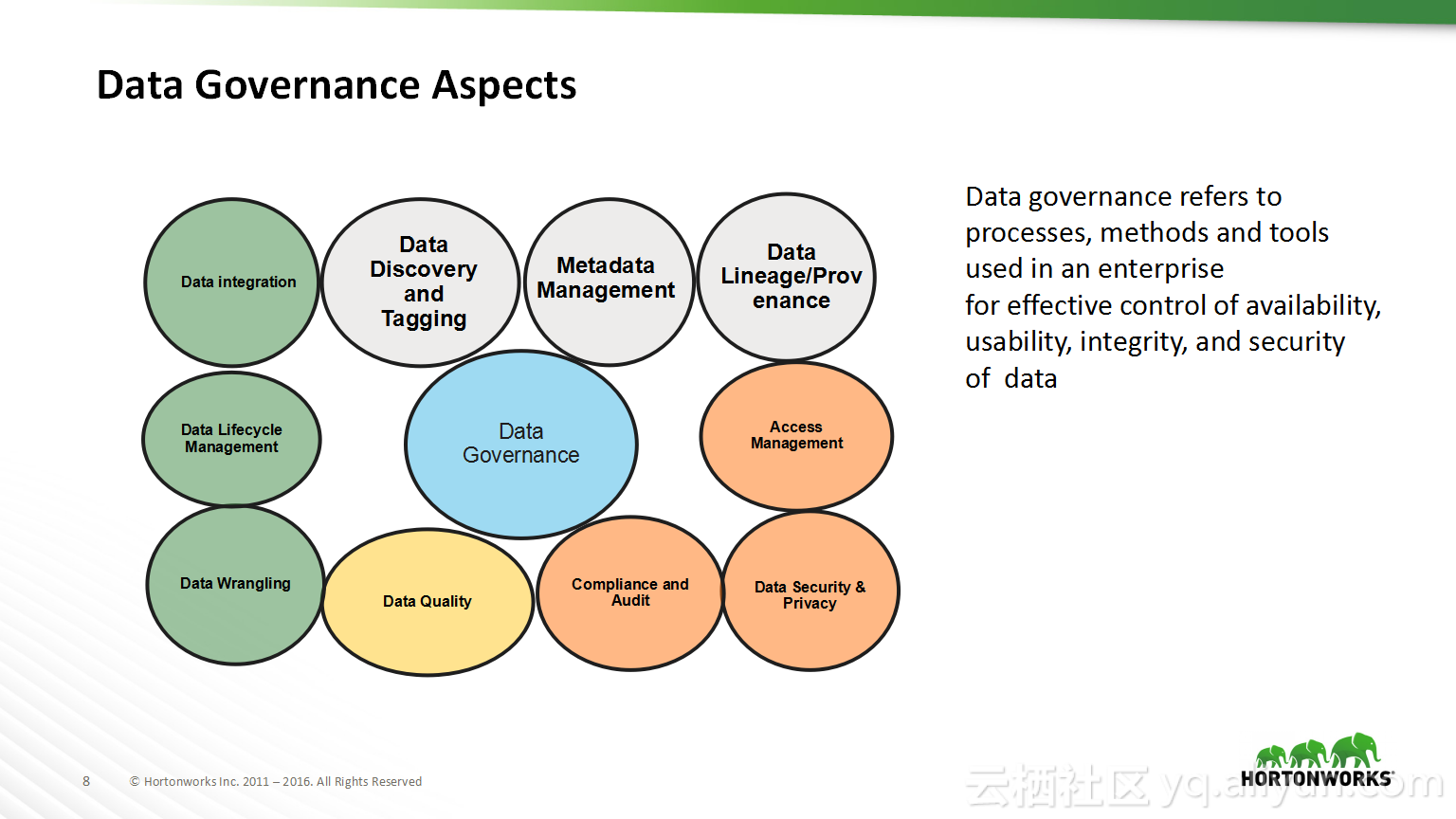
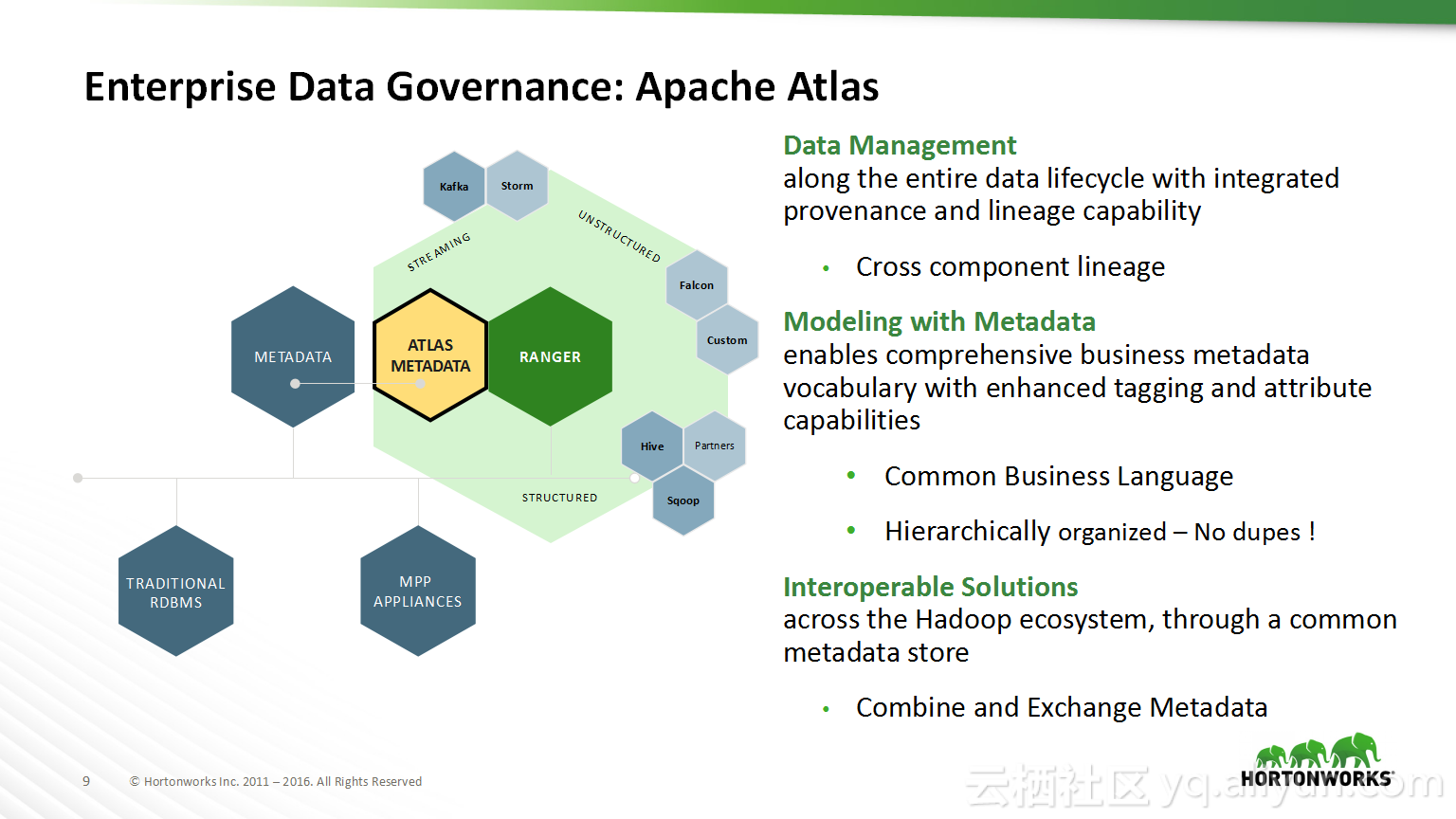
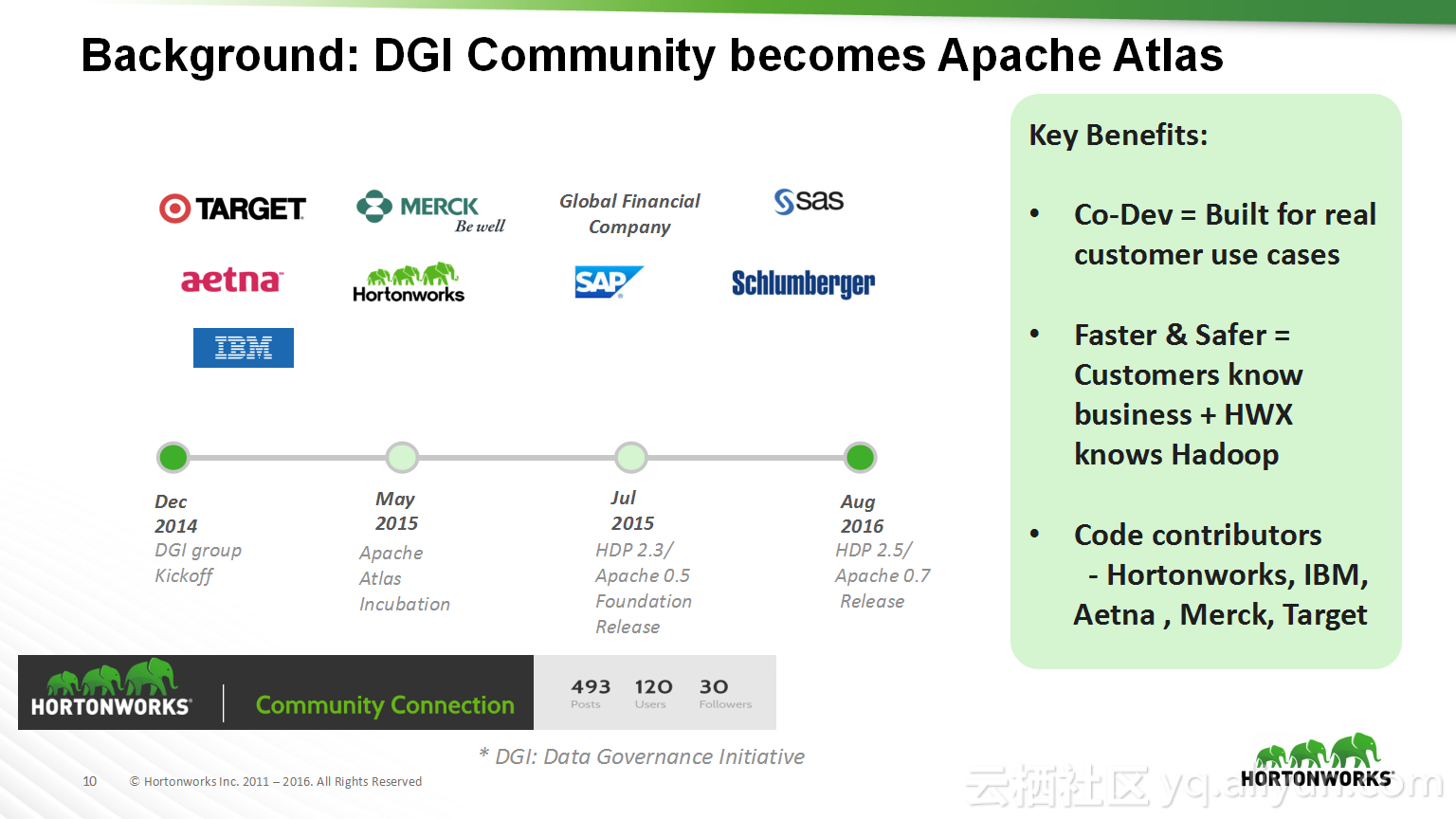

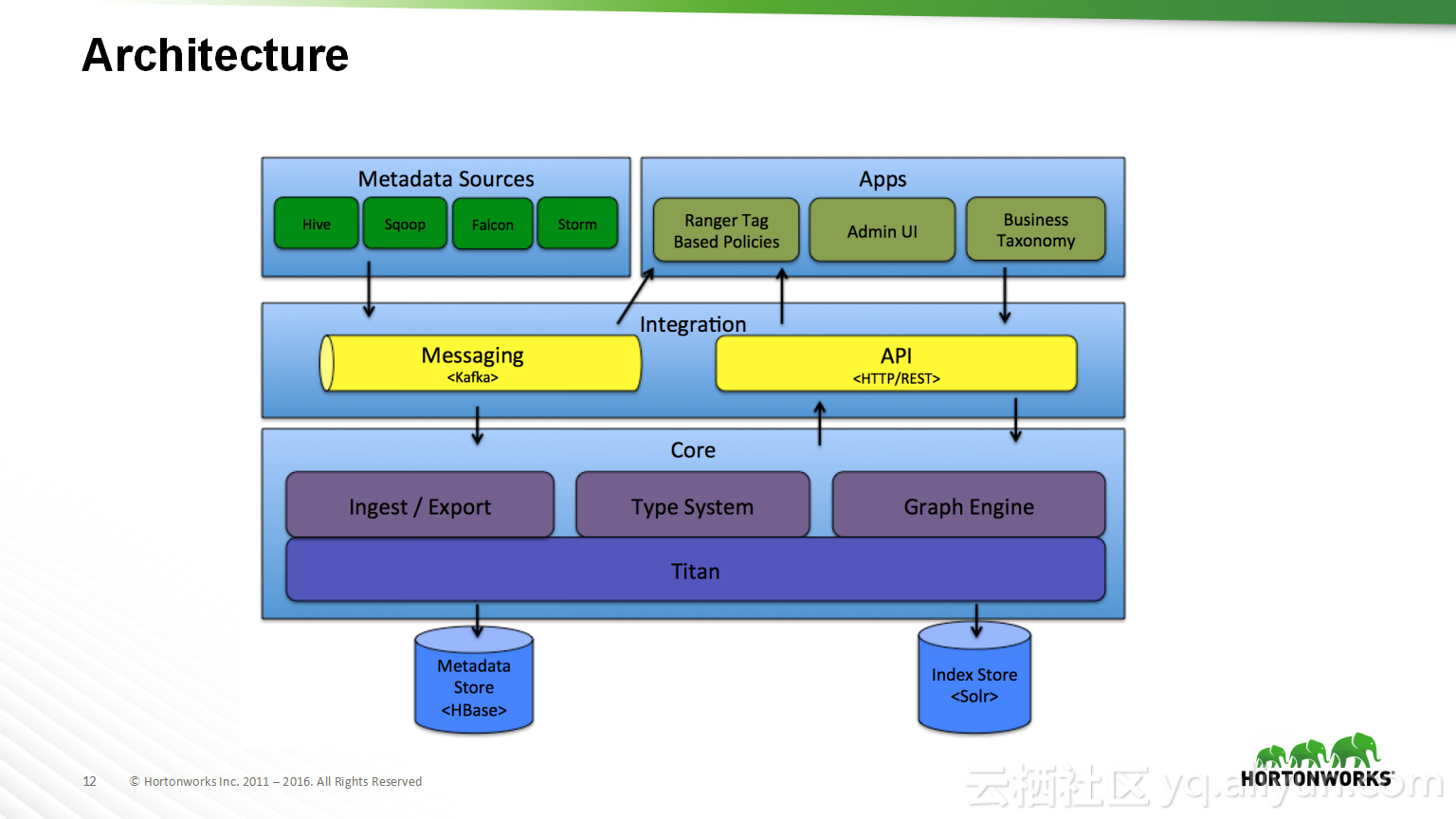

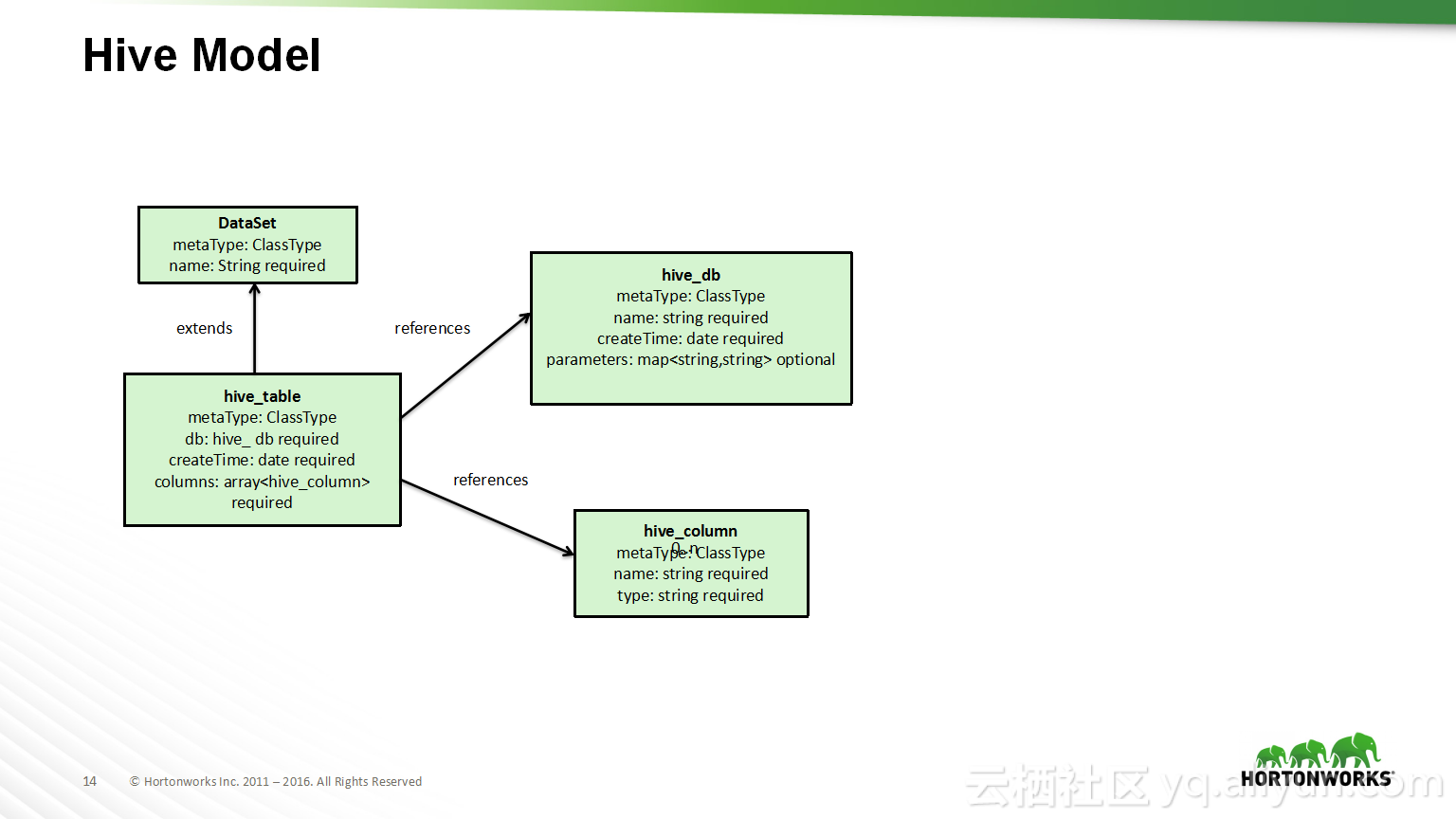
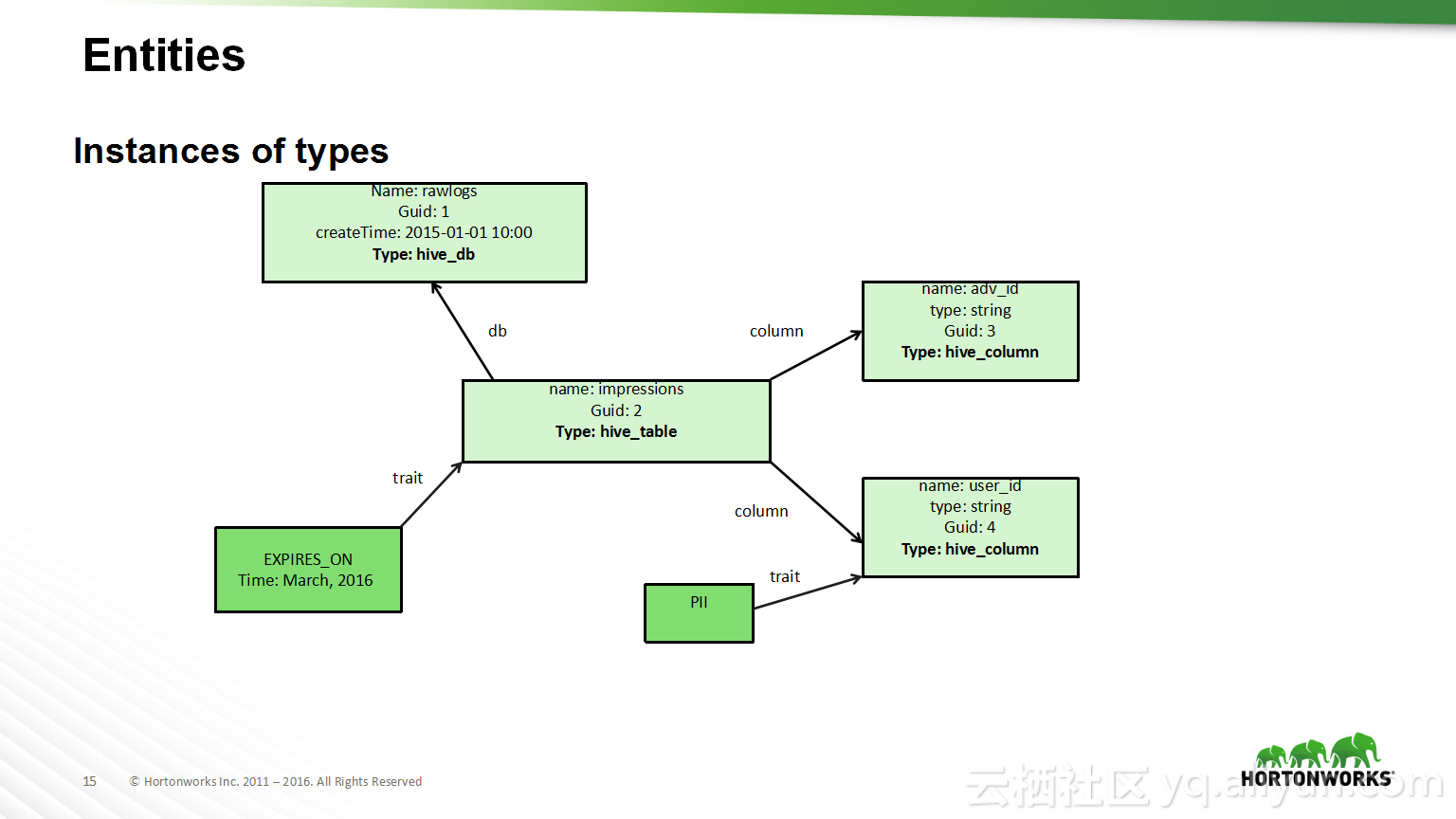

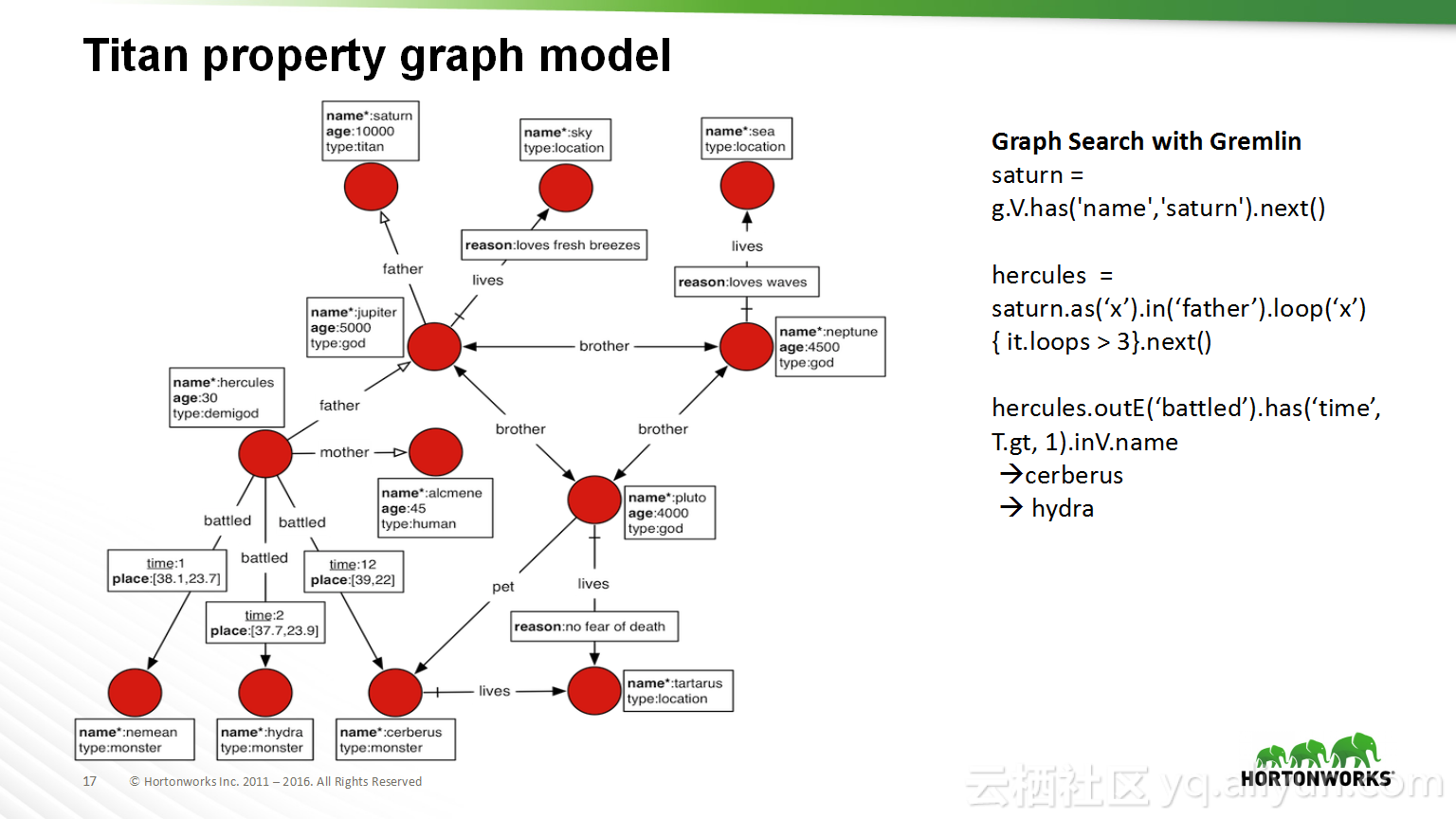
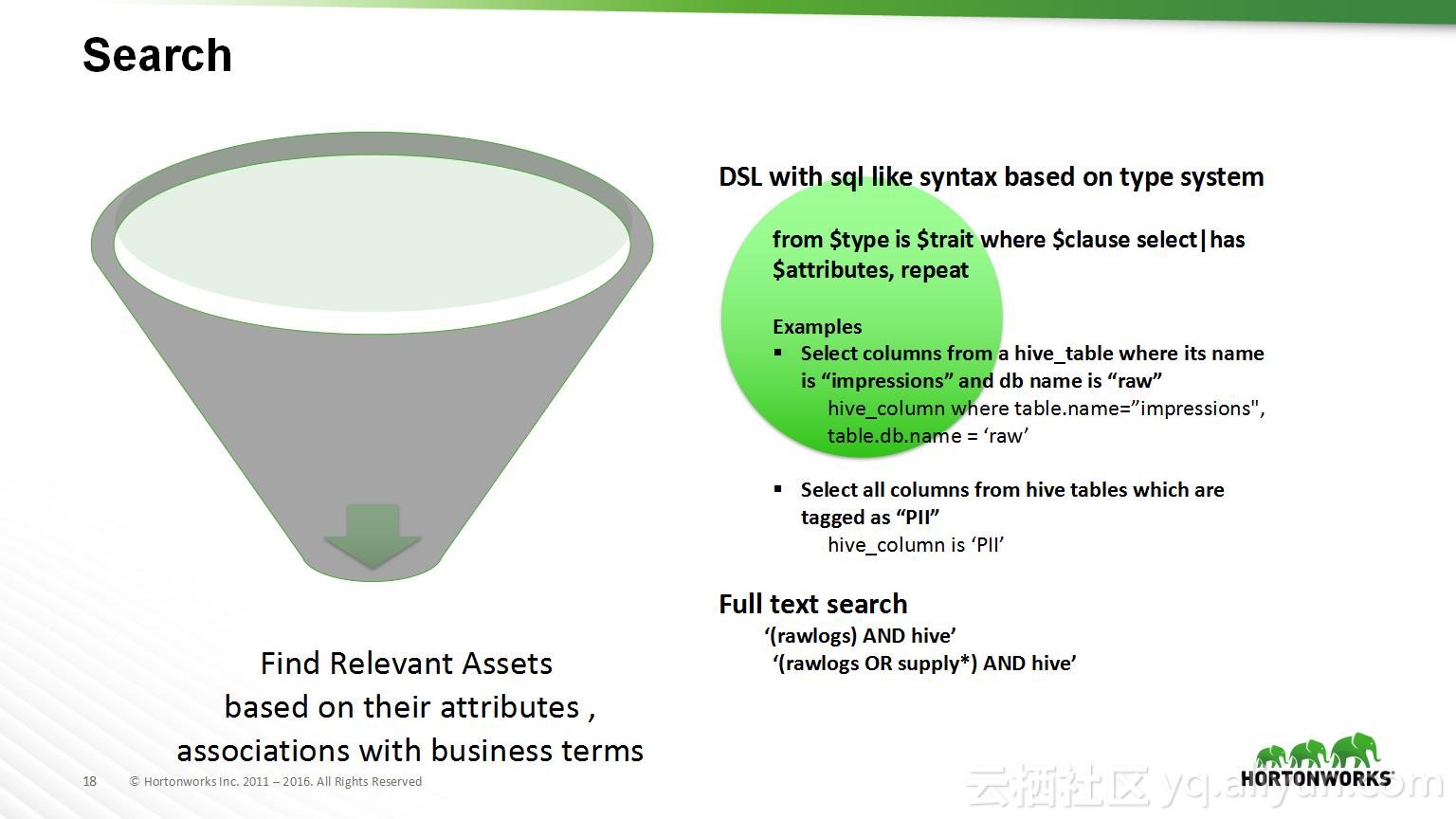

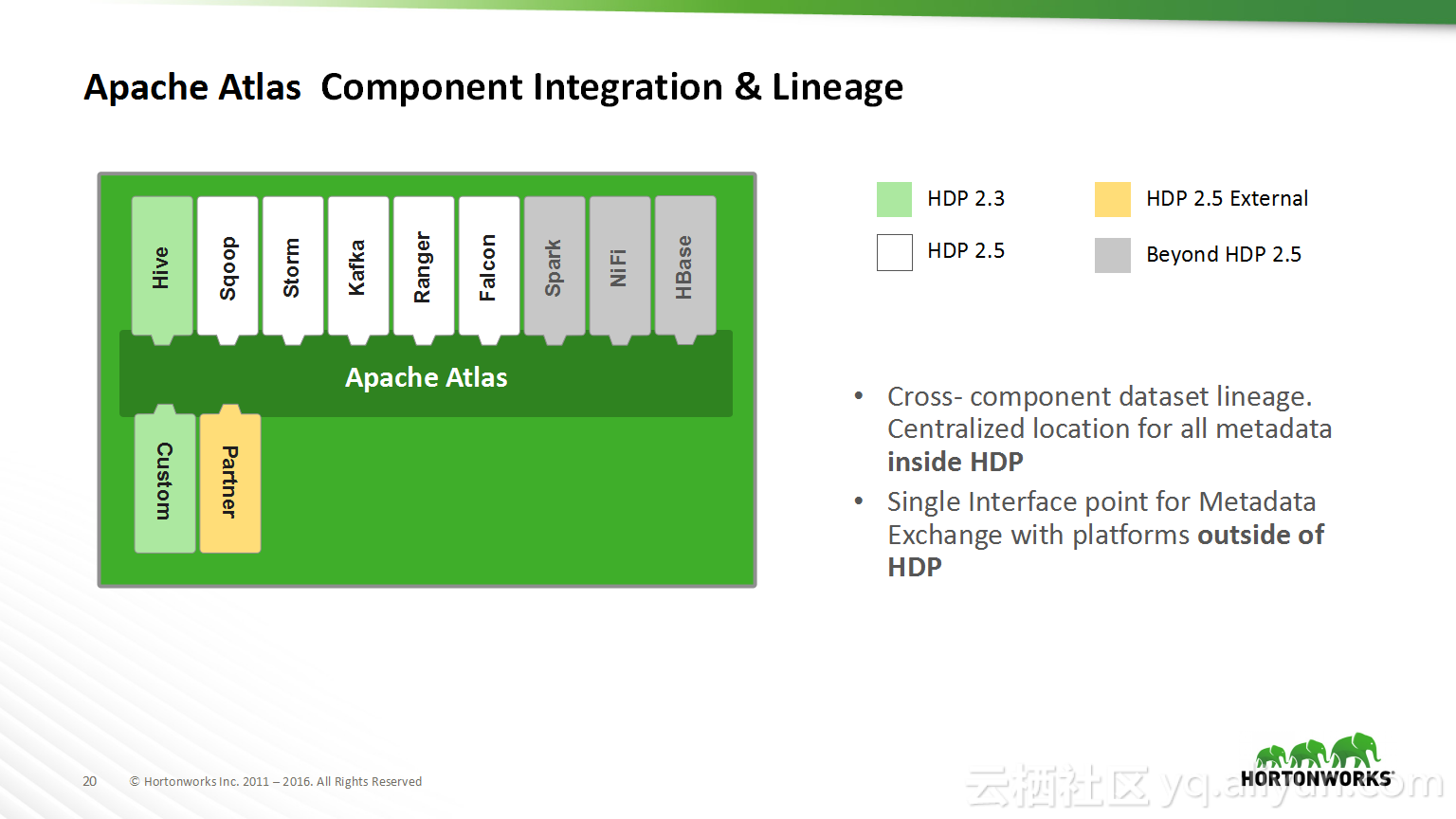


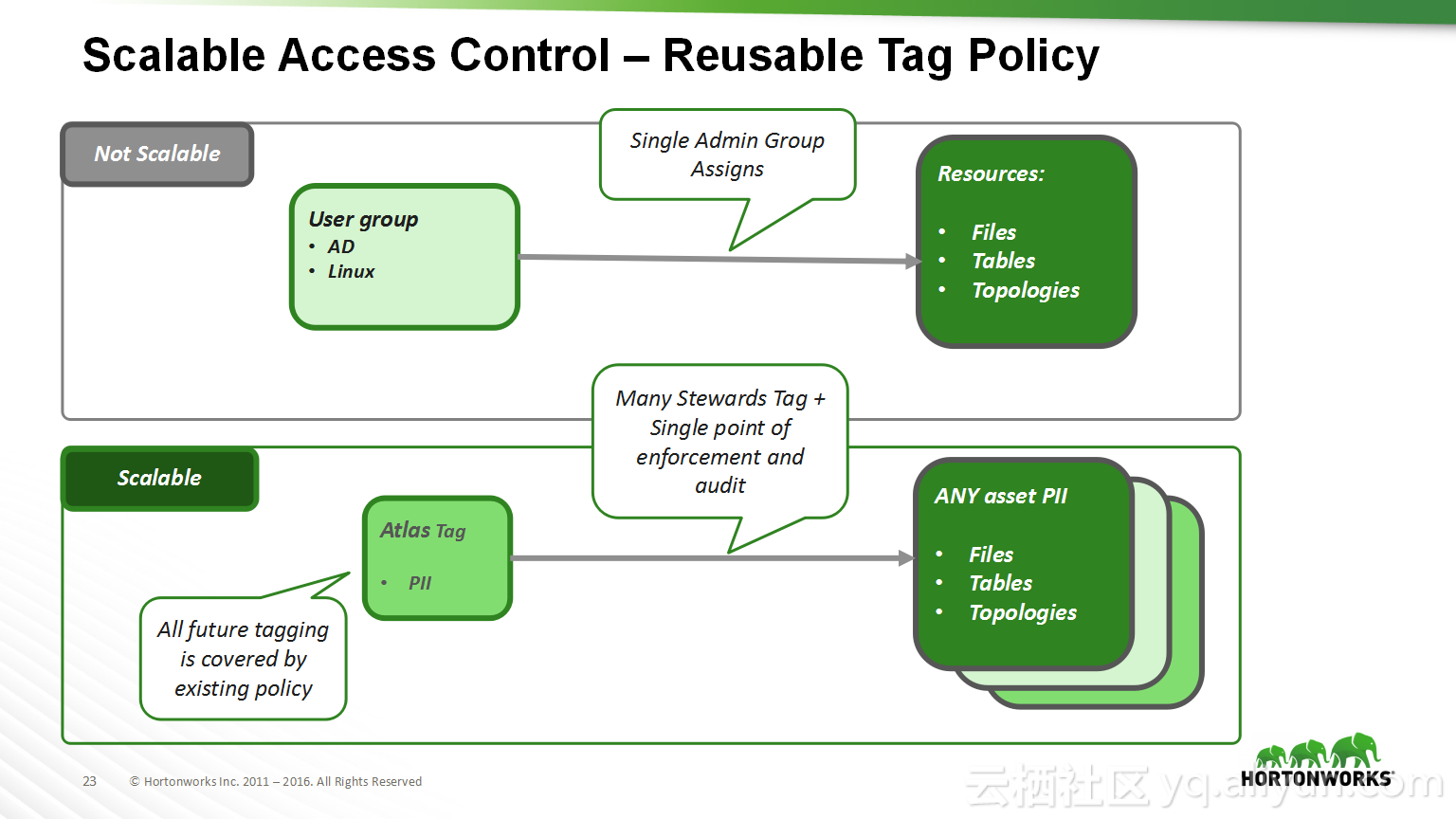





本讲义出自Shwetha Shivalingamurthy与Suma Shivaprasad在Hadoop Summit Tokyo 2016上的演讲,主要分享了企业数据分类和治理的案例并且深入地讲解了大数据治理的相关内容,并介绍了Atlas的概览和架构设计以及其特性和发展路线。
