热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
基于Java的学生学籍管理系统的设计与实现(源码+lw+部署文档+讲解等)
基于Java的新媒体视域下的中国古诗词展演的设计与实现(源码+lw+部署文档+讲解等)
开发语言漫谈-Swift
基于Java的儿童教育网站的设计与实现(源码+lw+部署文档+讲解等)
阿里云服务器搭建部署JavaWeb环境
蛇形填数(蓝桥杯)
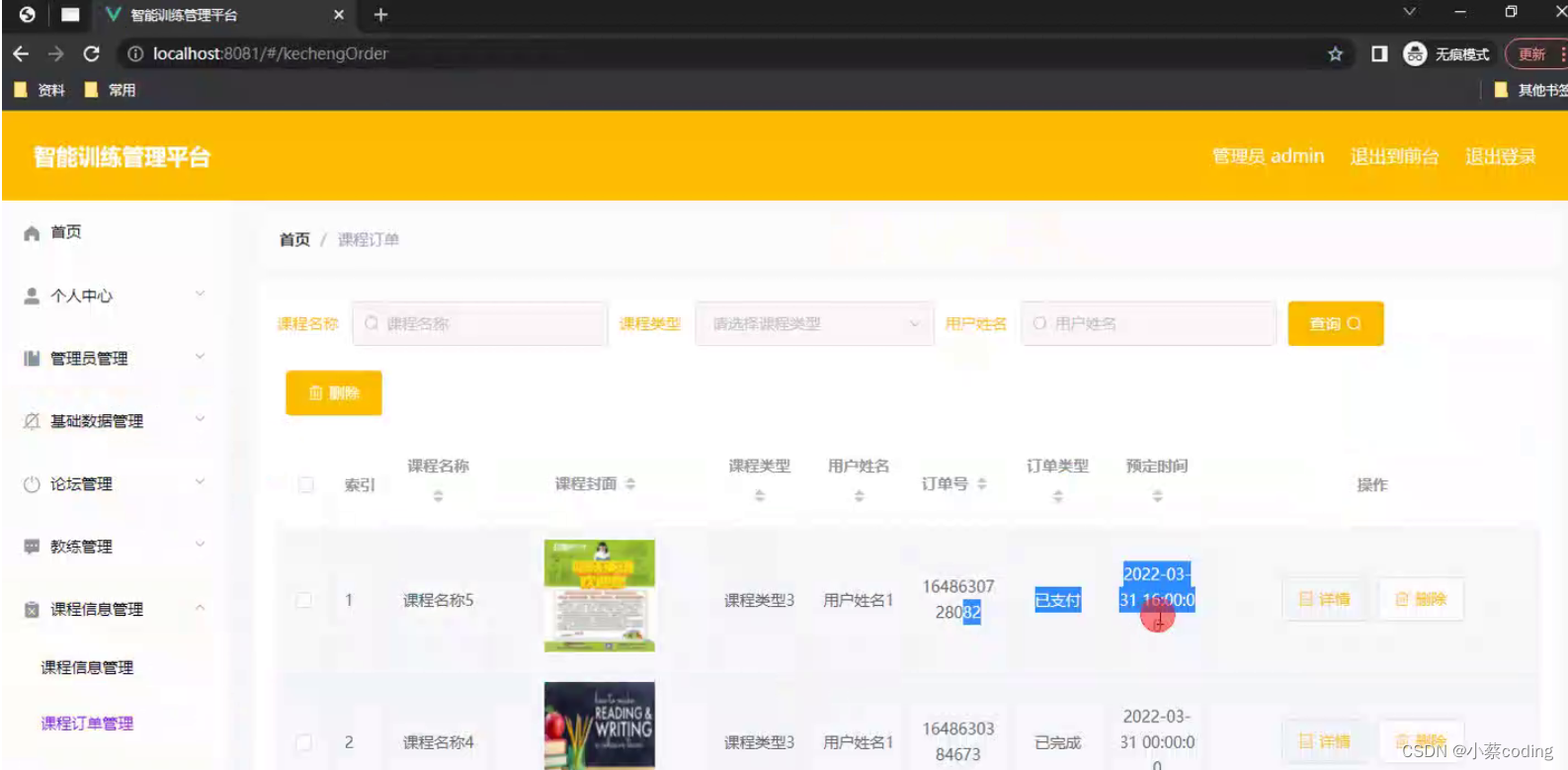
基于Java的智能训练管理平台的设计与实现(源码+lw+部署文档+讲解等)
特别数的和(蓝桥杯)
星系炸弹(蓝桥杯)
成绩统计(蓝桥杯)
微生物增殖(蓝桥杯)
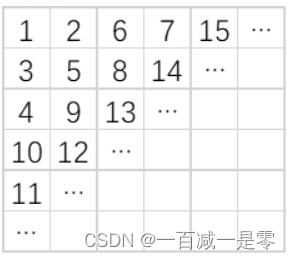
方阵转置(蓝桥杯)
负载均衡(理解/解析)
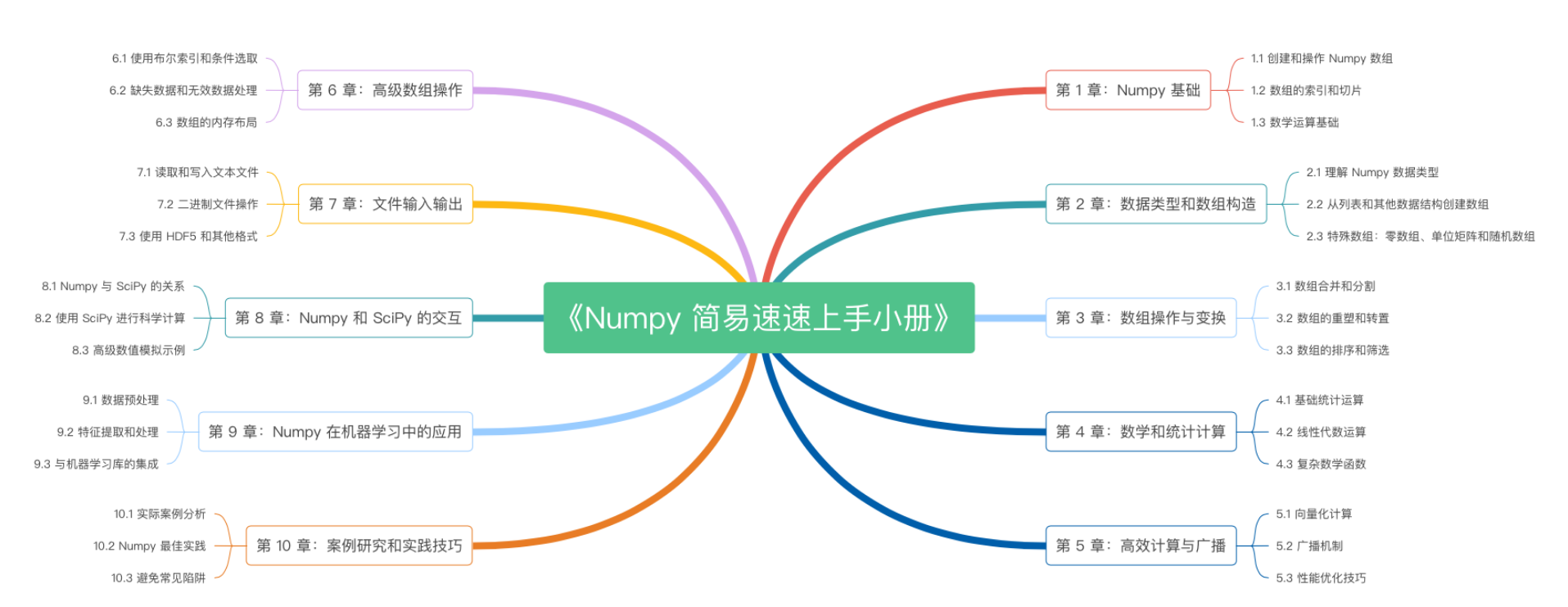
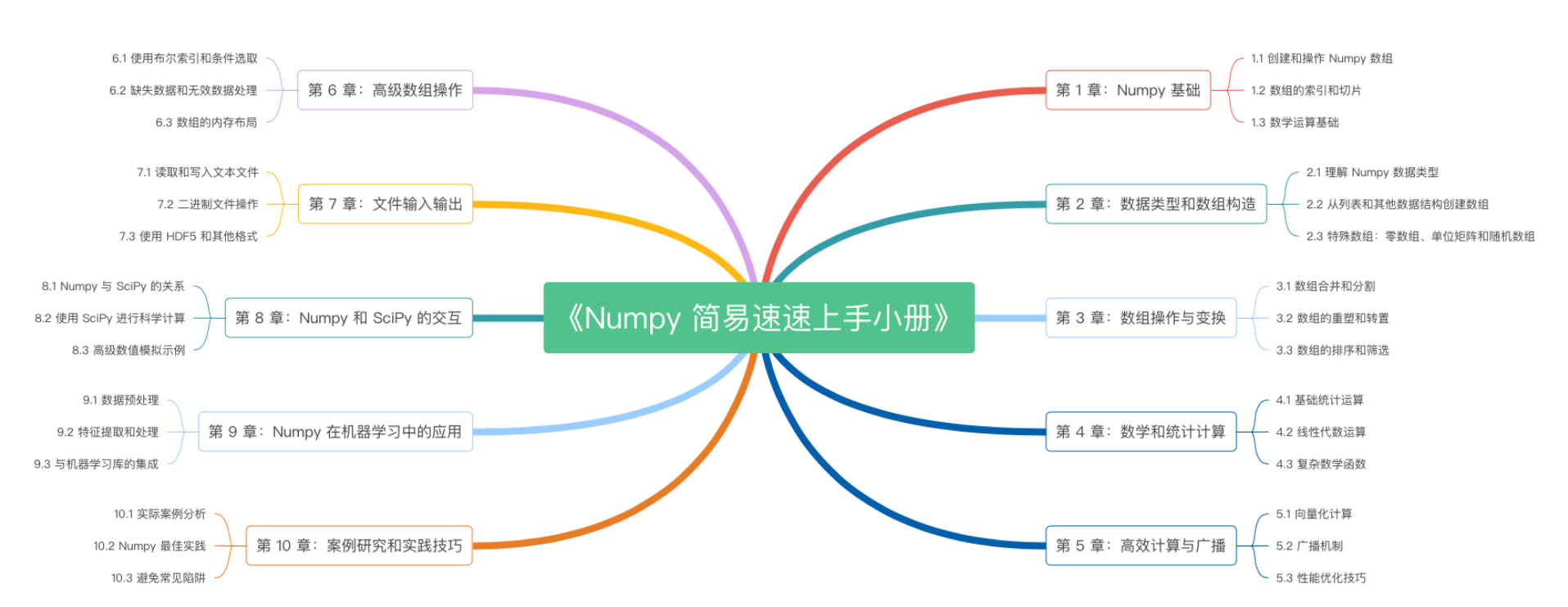
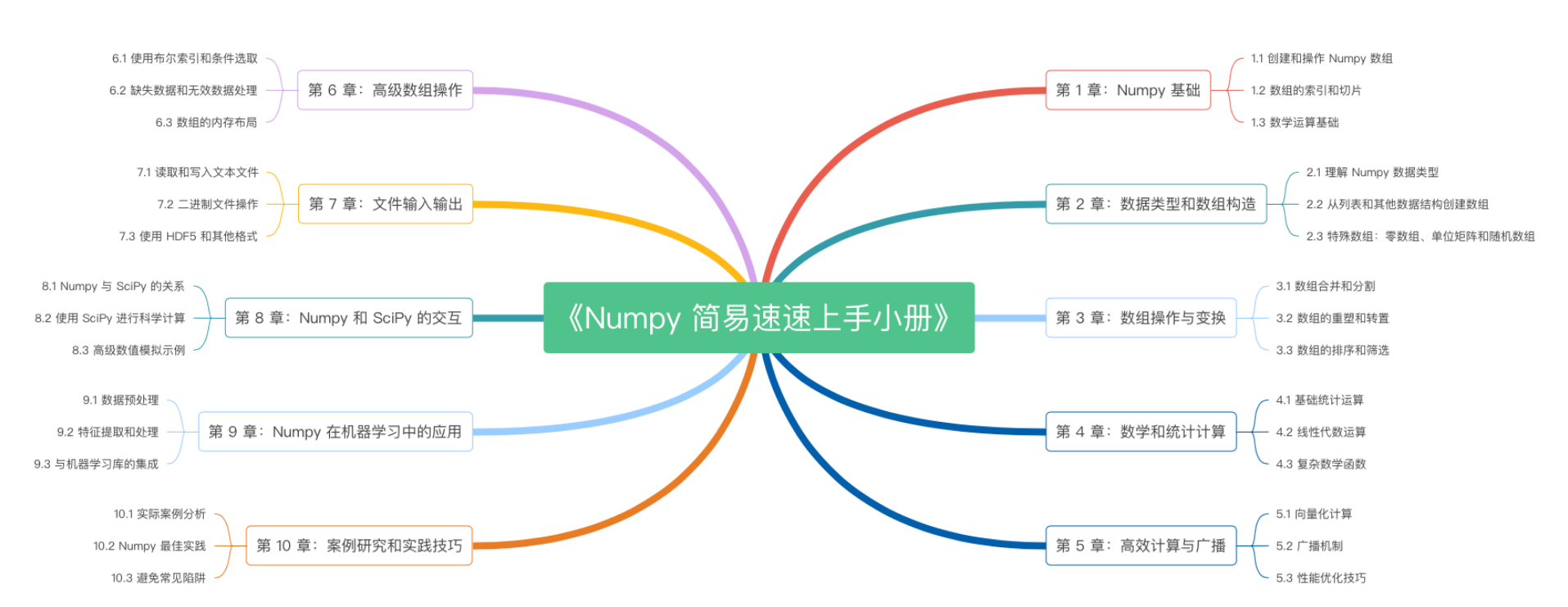
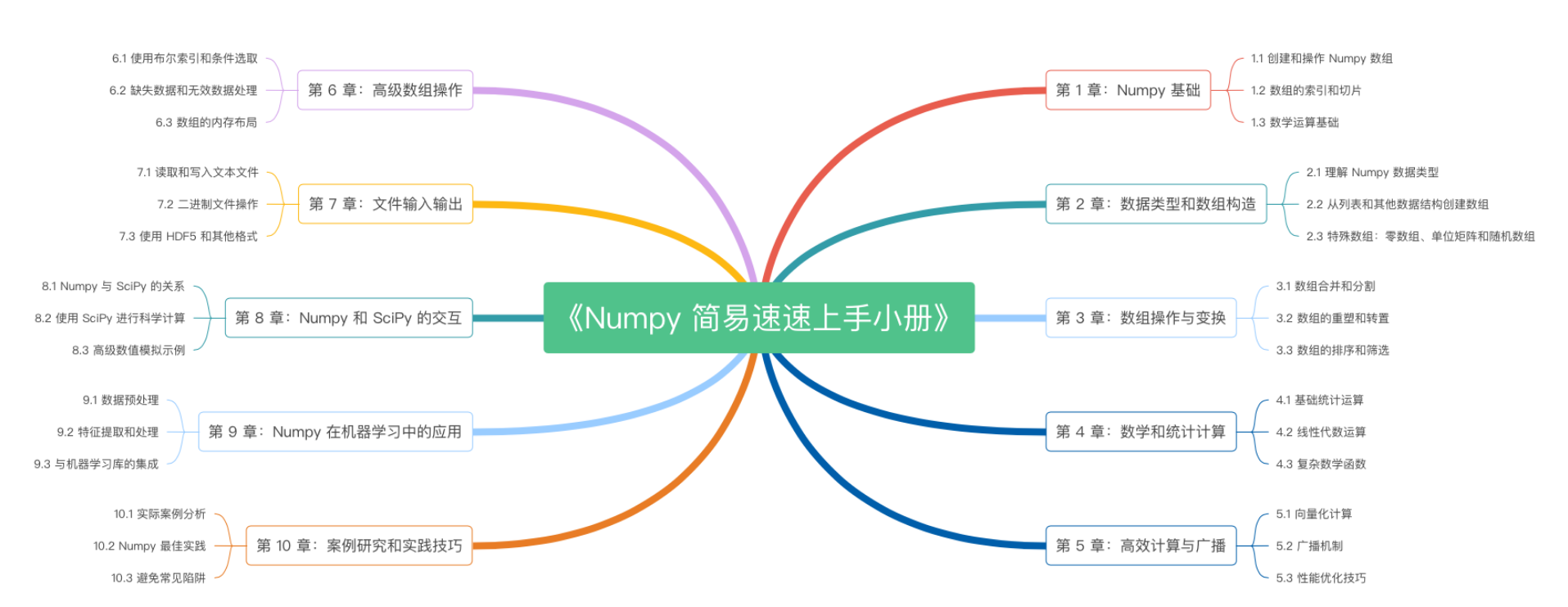
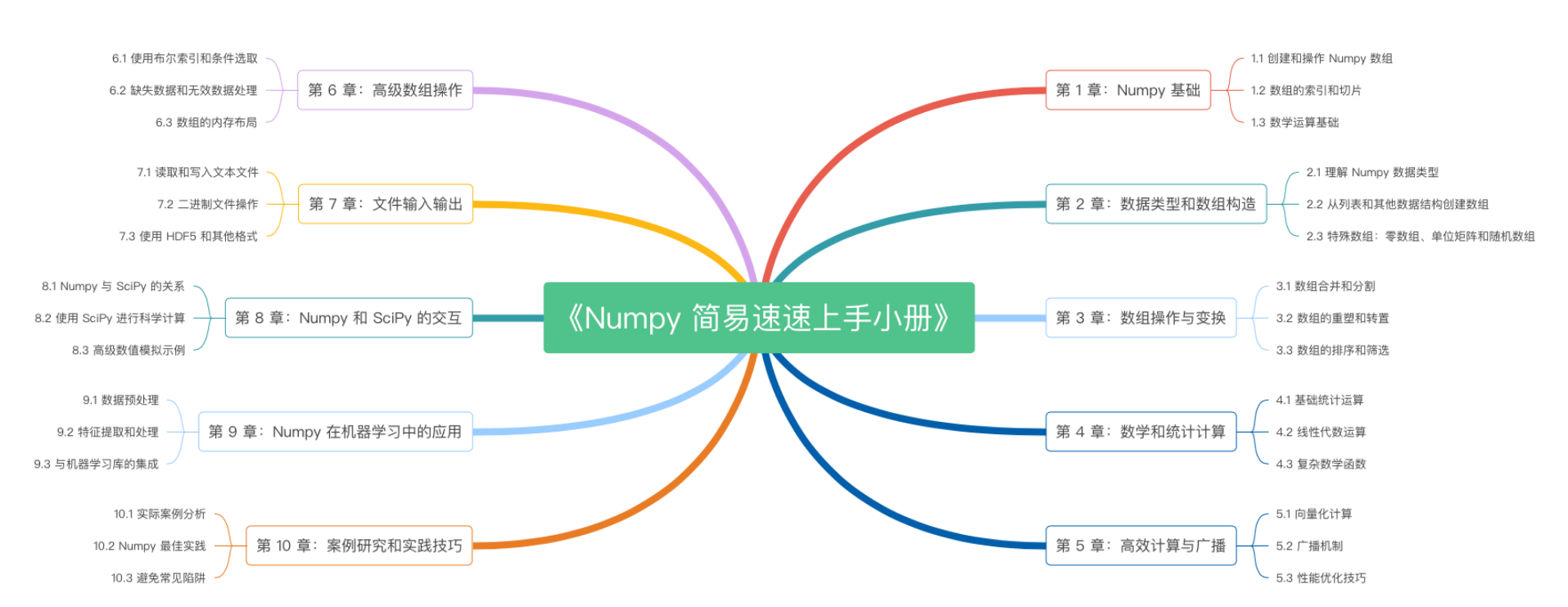
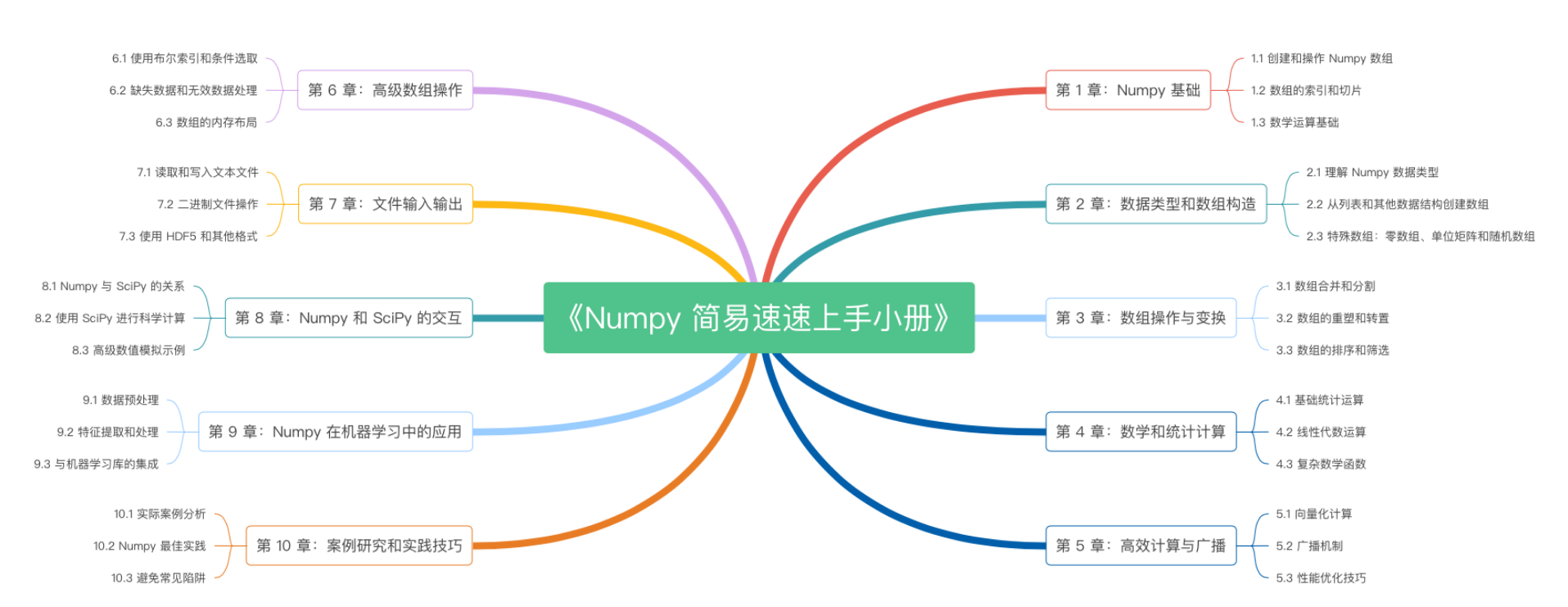
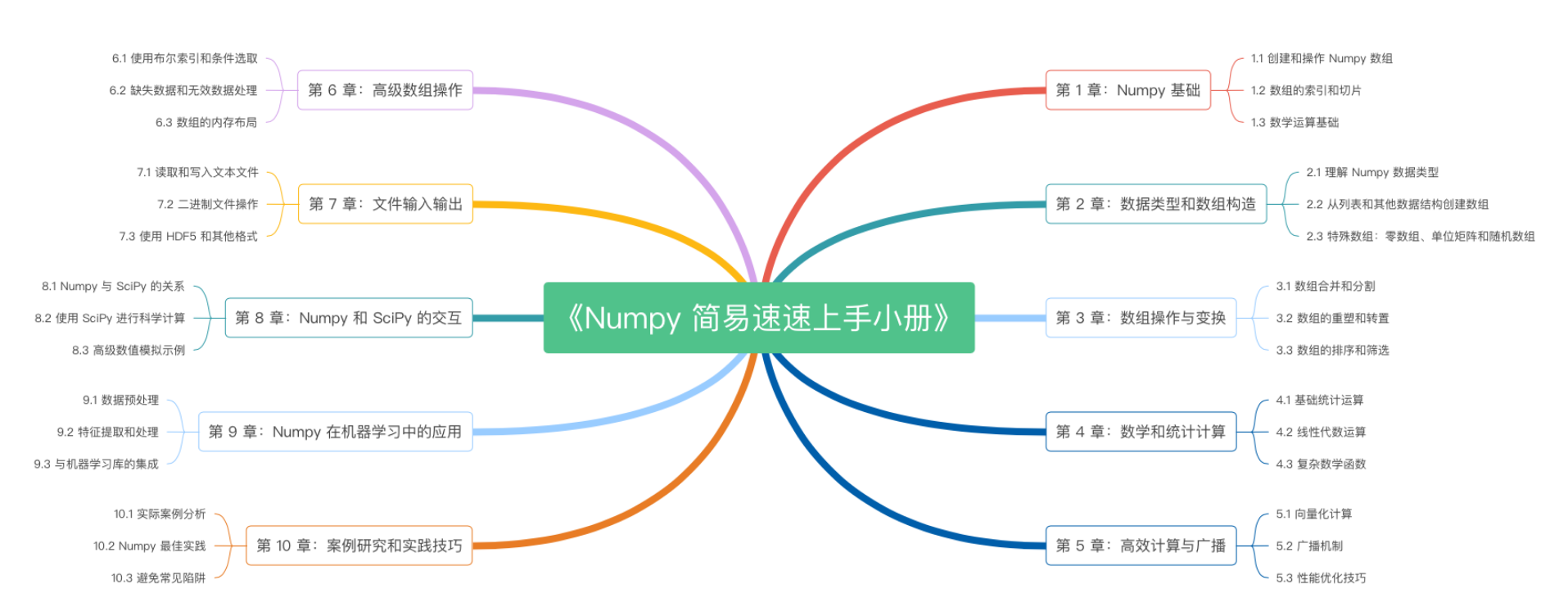
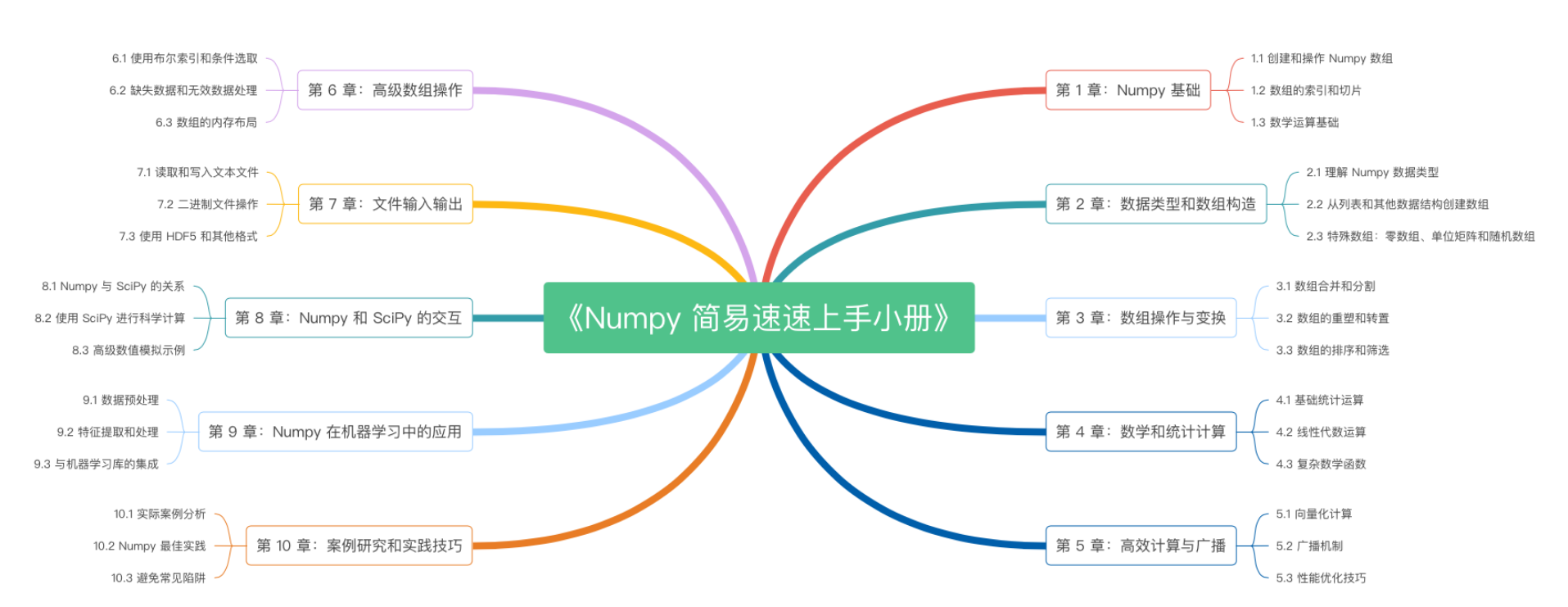
《Numpy 简易速速上手小册》第10章:Numpy案例研究和实践技巧(2024 最新版)
保护隐私与增强网络安全之网络代理技术
《Numpy 简易速速上手小册》第9章:Numpy 在机器学习中的应用(2024 最新版)
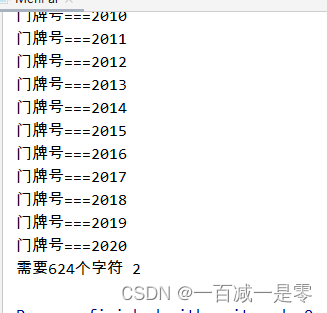
门牌制作(蓝桥杯)
《Numpy 简易速速上手小册》第8章:Numpy 和 SciPy 的交互(2024 最新版)
大衍数列(蓝桥杯)
分类算法(数据挖掘)
《Numpy 简易速速上手小册》第7章:Numpy 文件输入输出(2024 最新版)
通过动态IP解决网络数据采集问题
切面条(蓝桥杯)
《Numpy 简易速速上手小册》第6章:Numpy 高级数组操作(2024 最新版)
《Numpy 简易速速上手小册》第5章:Numpy高效计算与广播(2024 最新版)
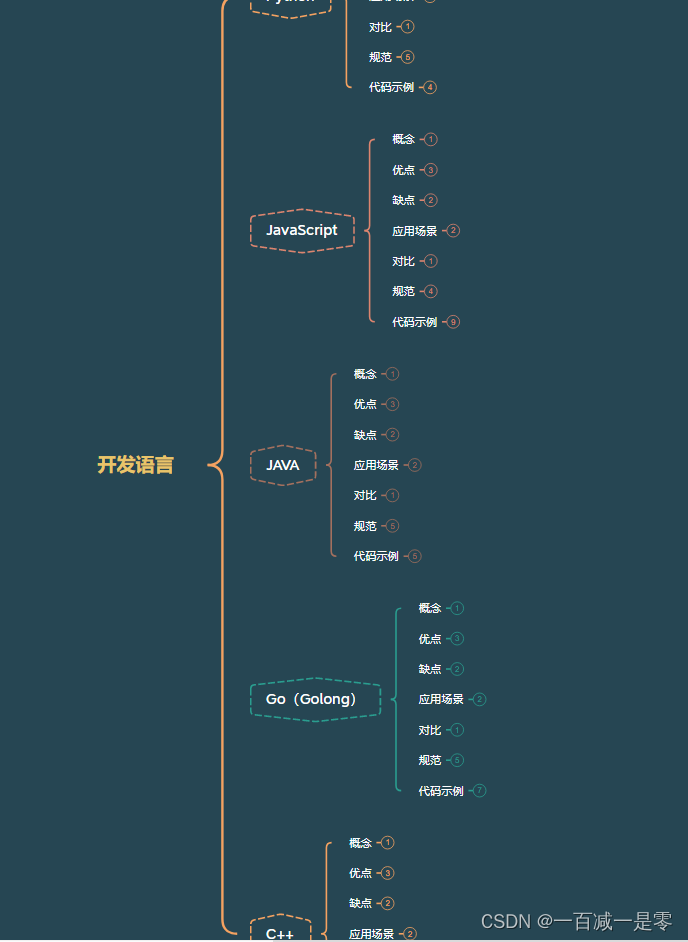
开发语言详解(python、java、Go(Golong)。。。。)
《Numpy 简易速速上手小册》第4章:Numpy 数学和统计计算(2024 最新版)
多线程收集/验证IP从而搭建有效IP代理池
python基础知识(一)
《Numpy 简易速速上手小册》第3章:Numpy 数组操作与变换(2024 最新版)
搭建分布式应用准备工作(从零到一)
《Numpy 简易速速上手小册》第2章:Numpy 数据类型和数组构造(2024 最新版)
《Numpy 简易速速上手小册》第1章:Numpy 基础(2024 最新版)
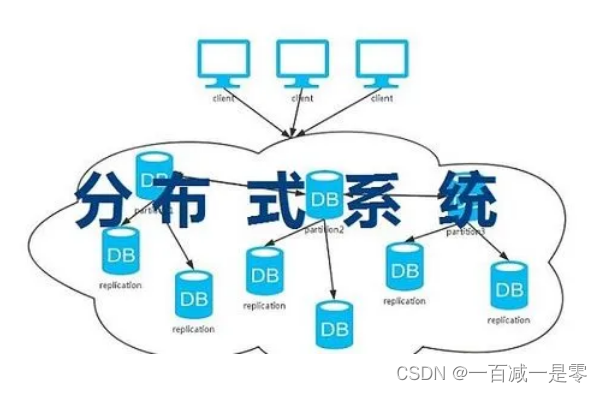
分布式(计算机算法)
springboot的异步类的介绍
开发语言漫谈-Object C
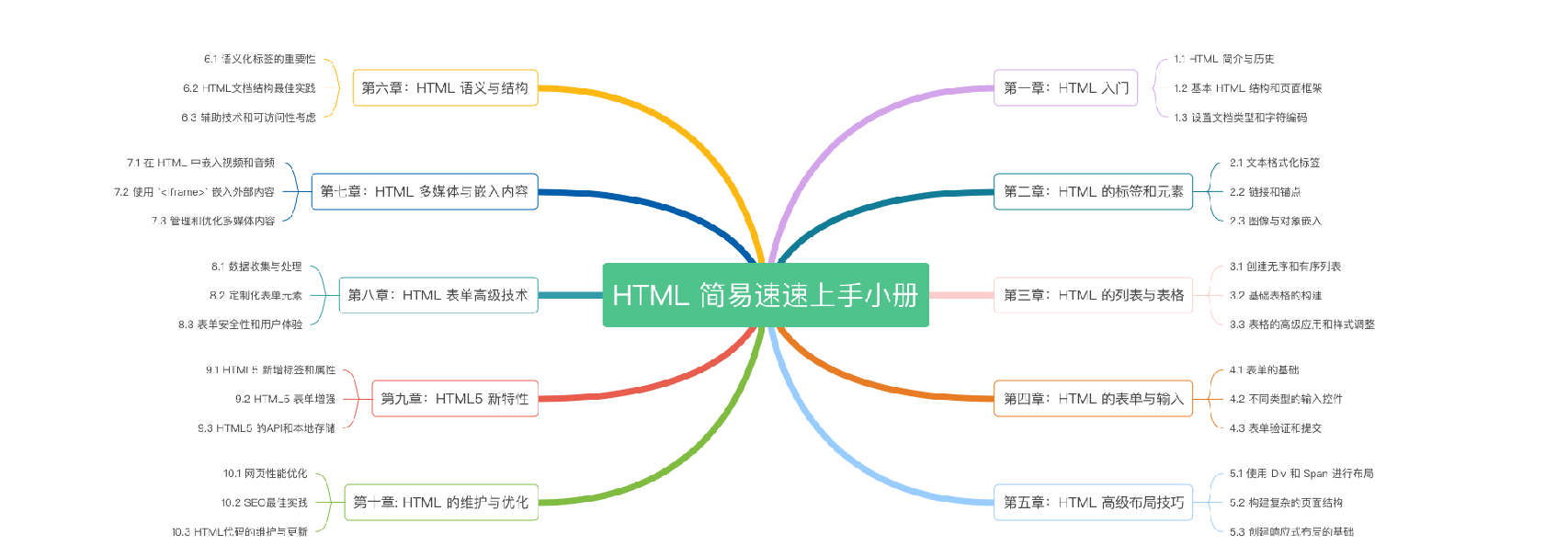
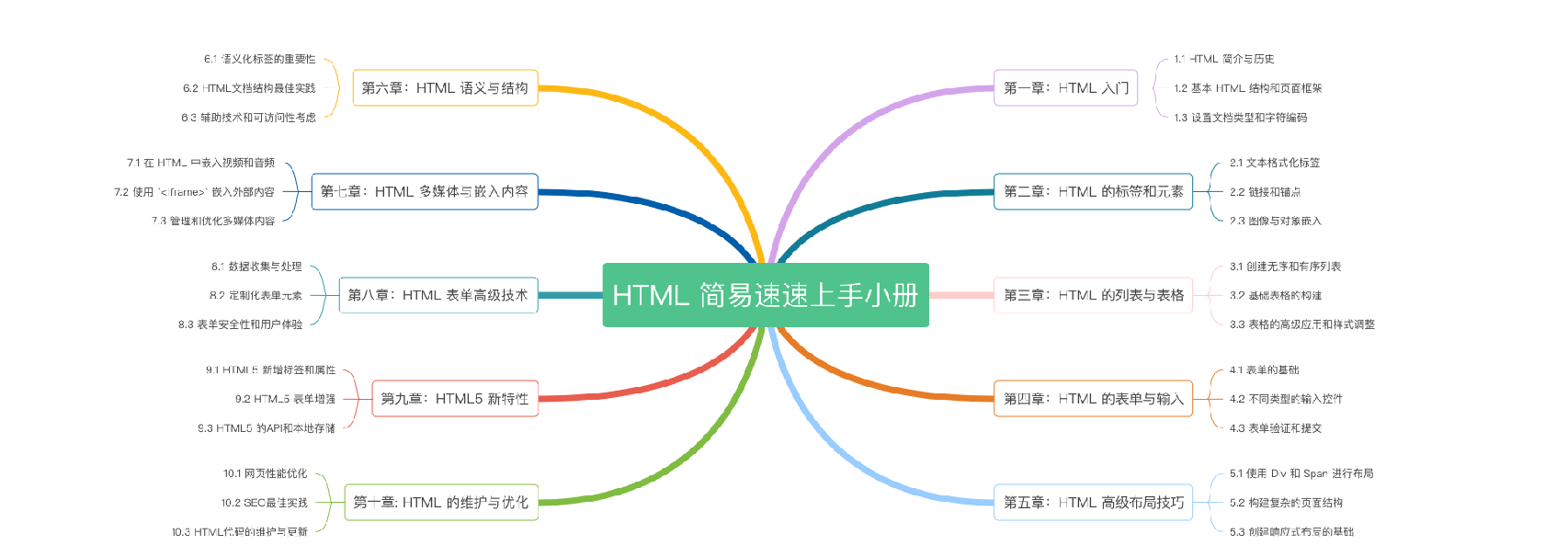
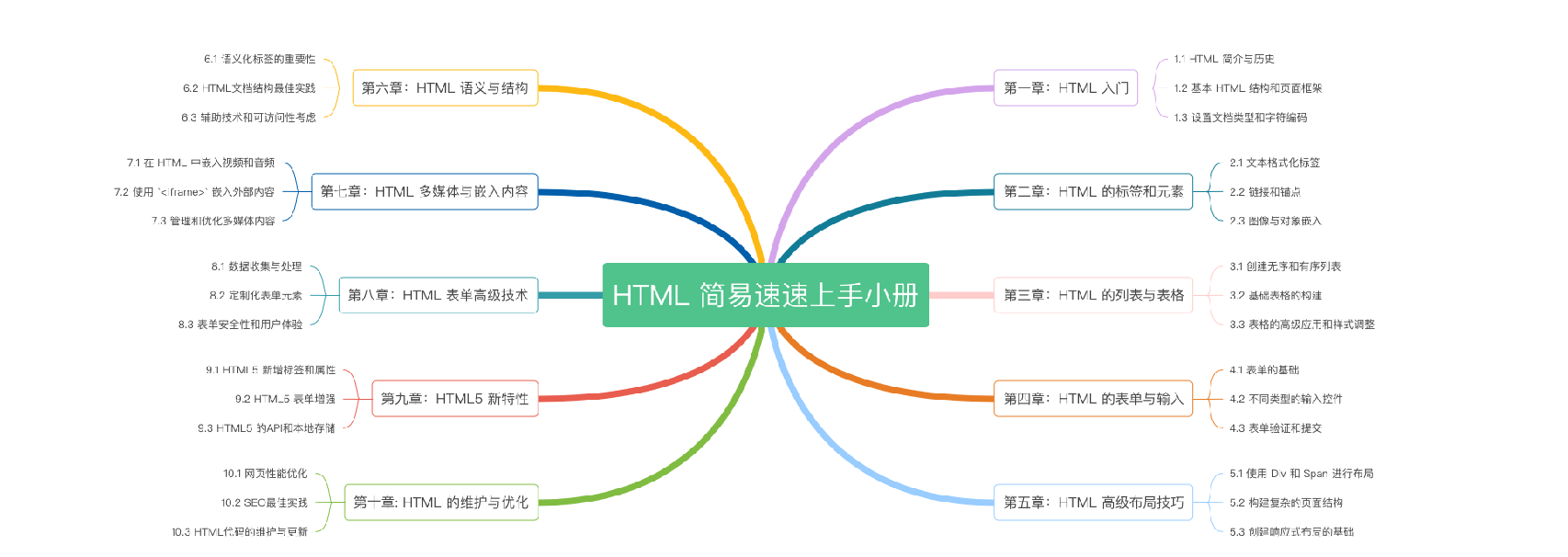
《HTML 简易速速上手小册》第10章:HTML 的维护与优化(2024 最新版)
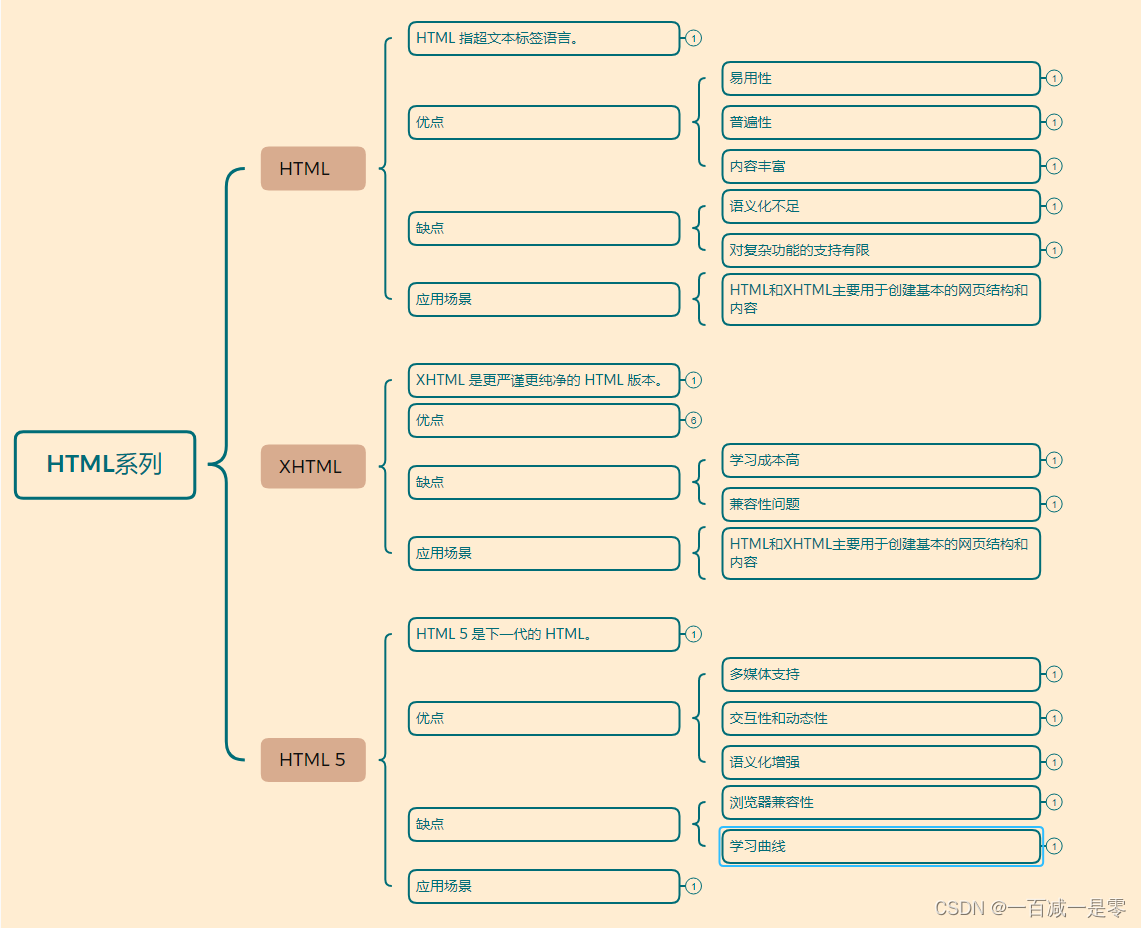
HTML、XHTML和HTML5系列对比
《HTML 简易速速上手小册》第9章:HTML5 新特性(2024 最新版)
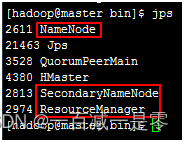
Hadoop集群搭建
《HTML 简易速速上手小册》第8章:HTML 表单高级技术(2024 最新版)
Hadoop集群节点添加
clickhouse权限控制
《HTML 简易速速上手小册》第7章:HTML 多媒体与嵌入内容(2024 最新版)
RocketMQ实践问题收集
《HTML 简易速速上手小册》第6章:HTML 语义与结构(2024 最新版)
RocketMq消费者/生产者配置
《HTML 简易速速上手小册》第5章:HTML 高级布局技巧(2024 最新版)