本讲义出自Matthias Langer、Dr. Zhen He与Dr. Zhen He在Hadoop Summit Tokyo 2016上的演讲,主要介绍了深度学习的基本概念和相关知识,分享了Spark与深度学习的关联,并介绍了La Trobe大学的深度学习系统。



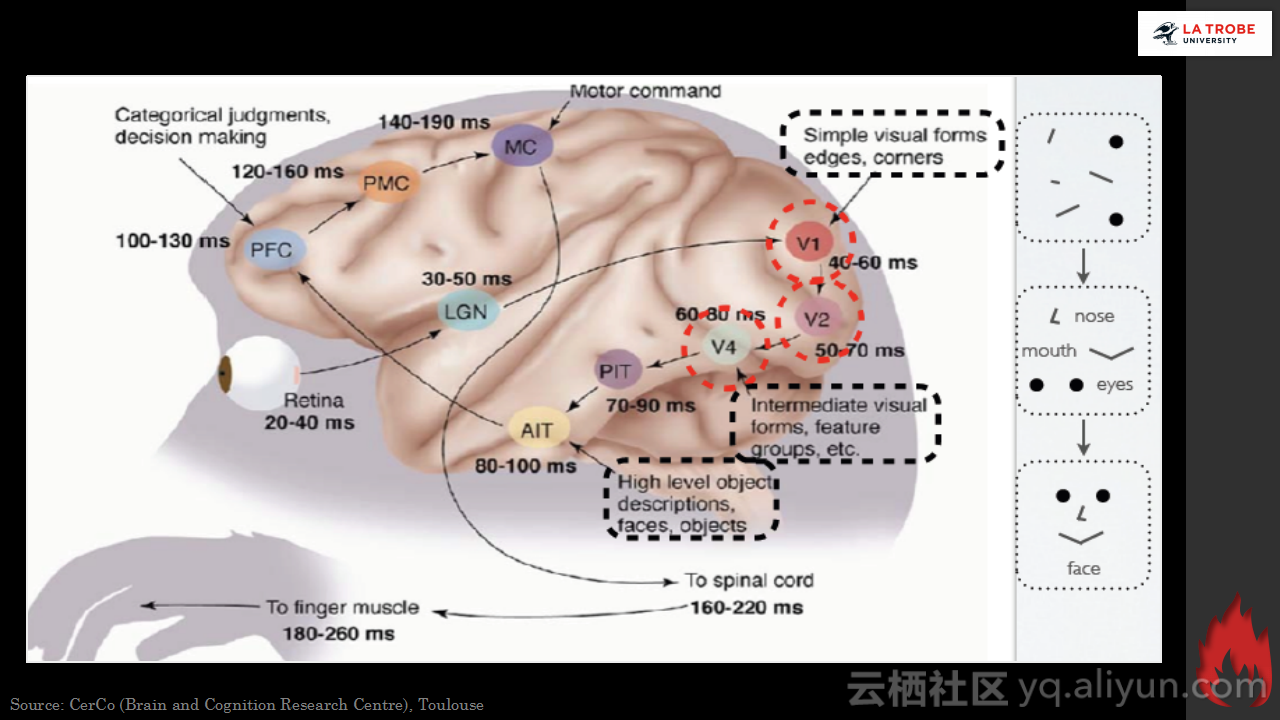

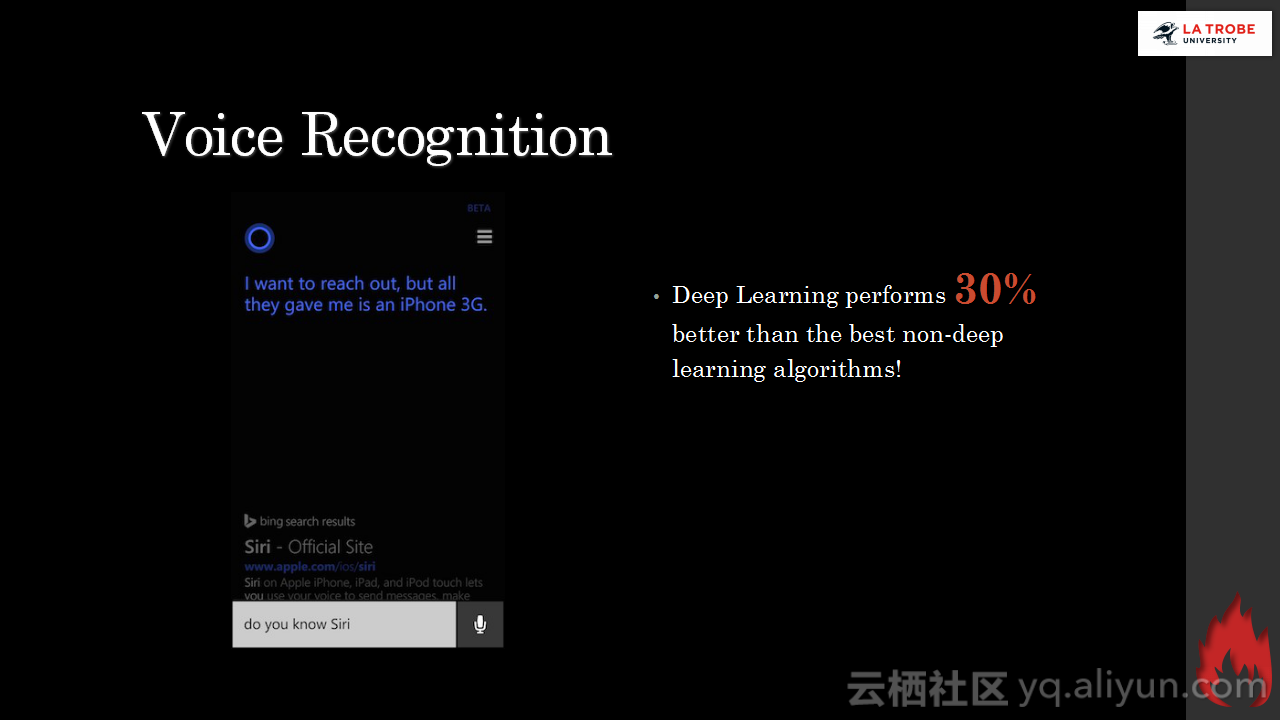






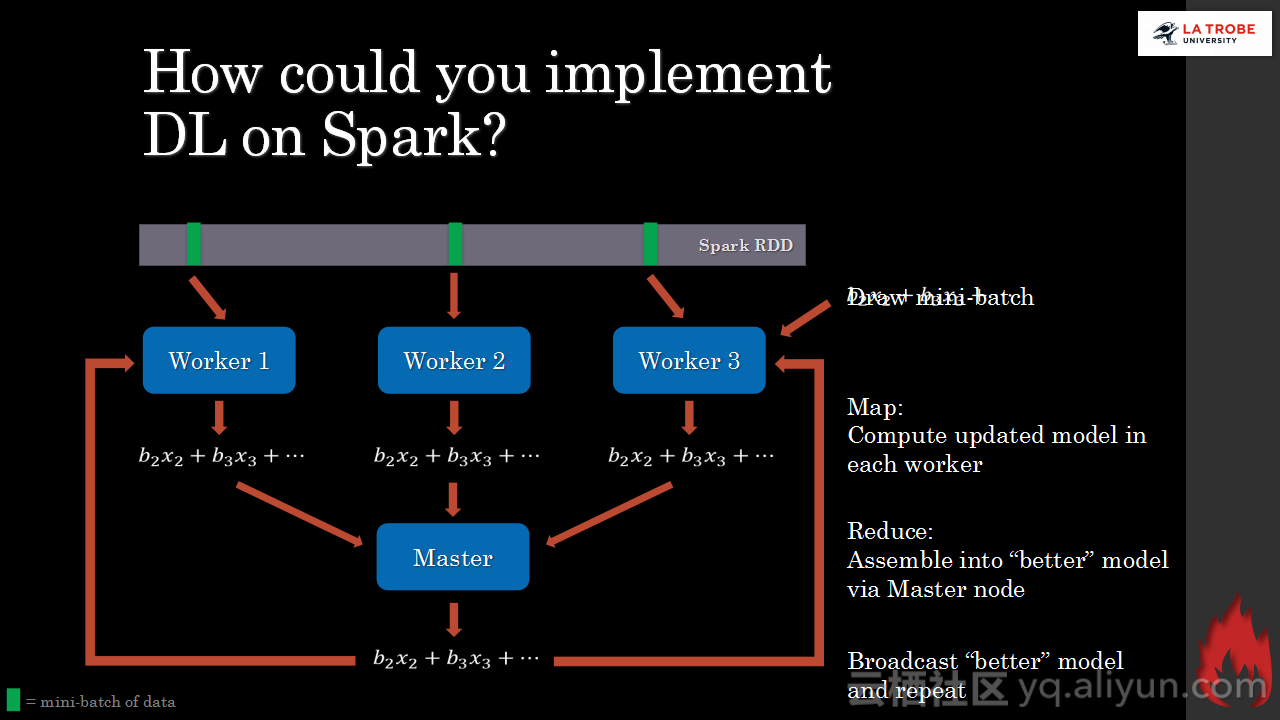
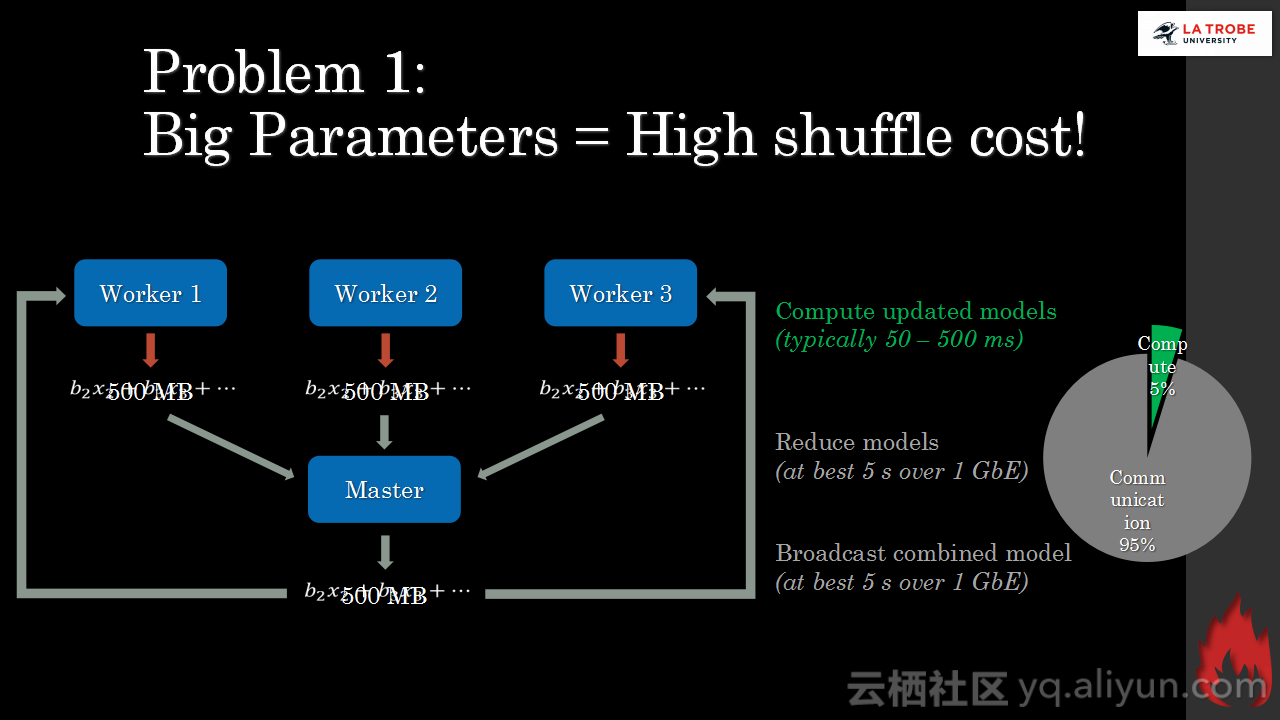
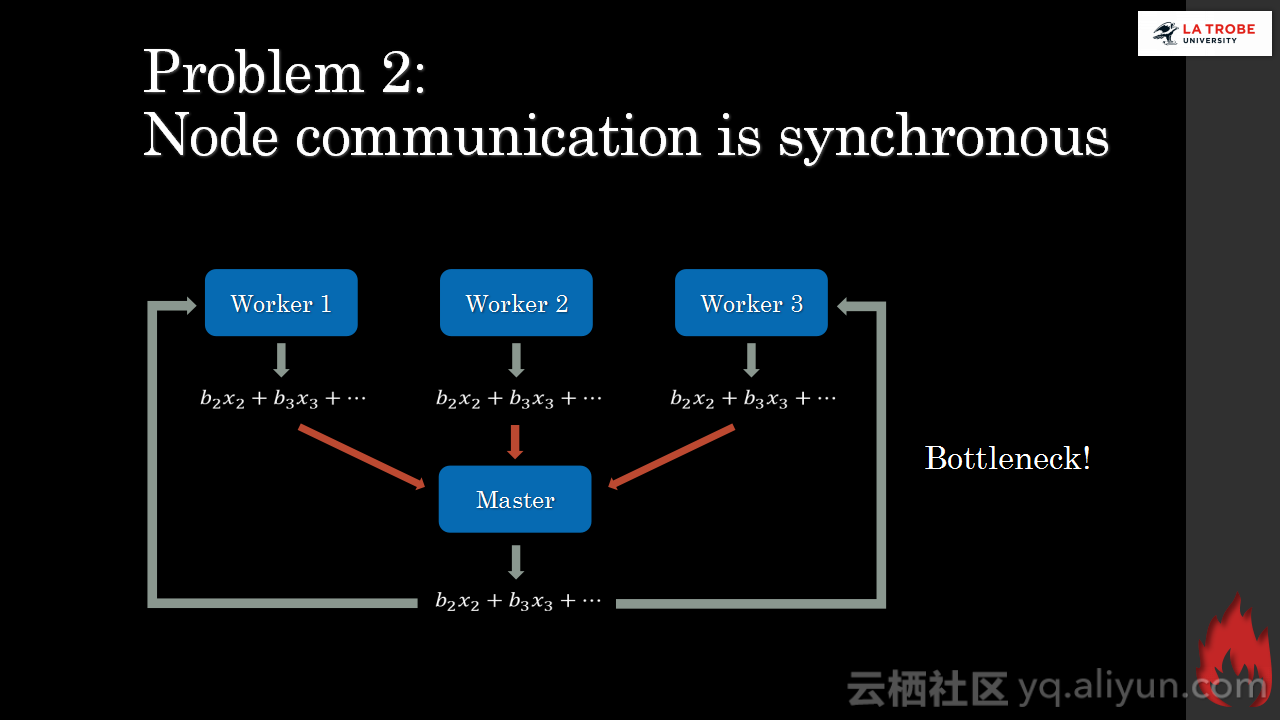
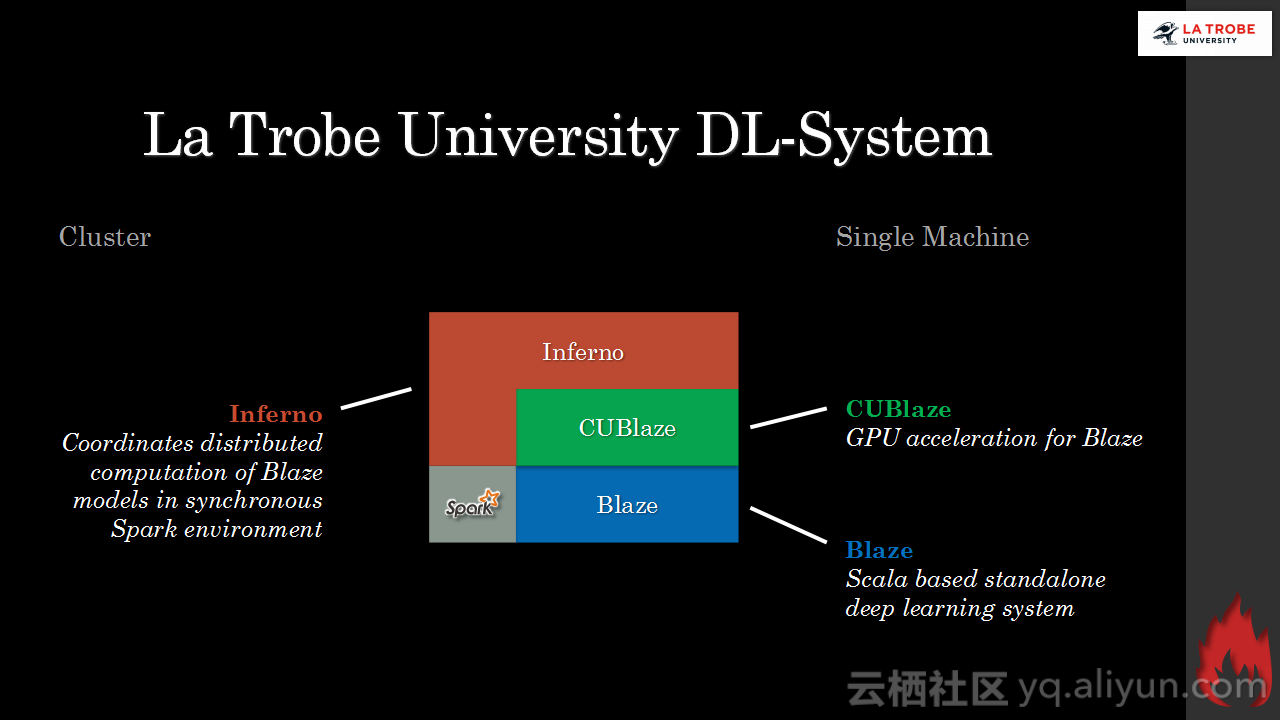
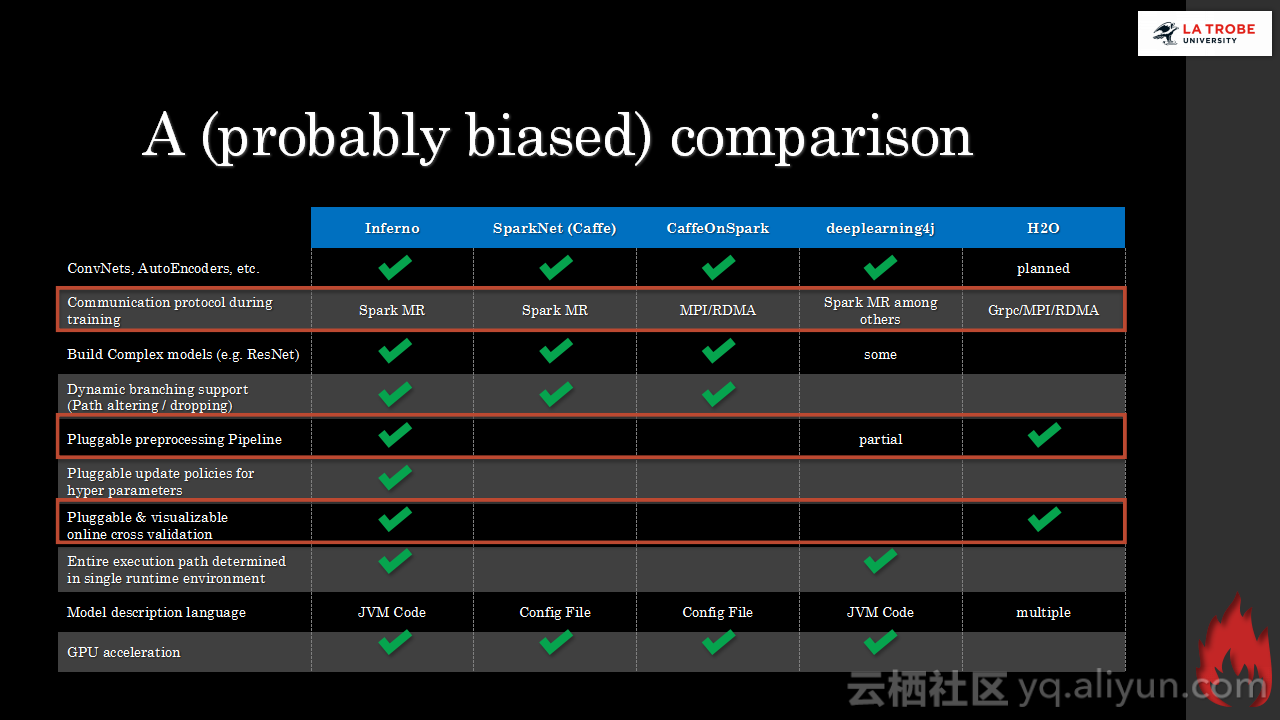


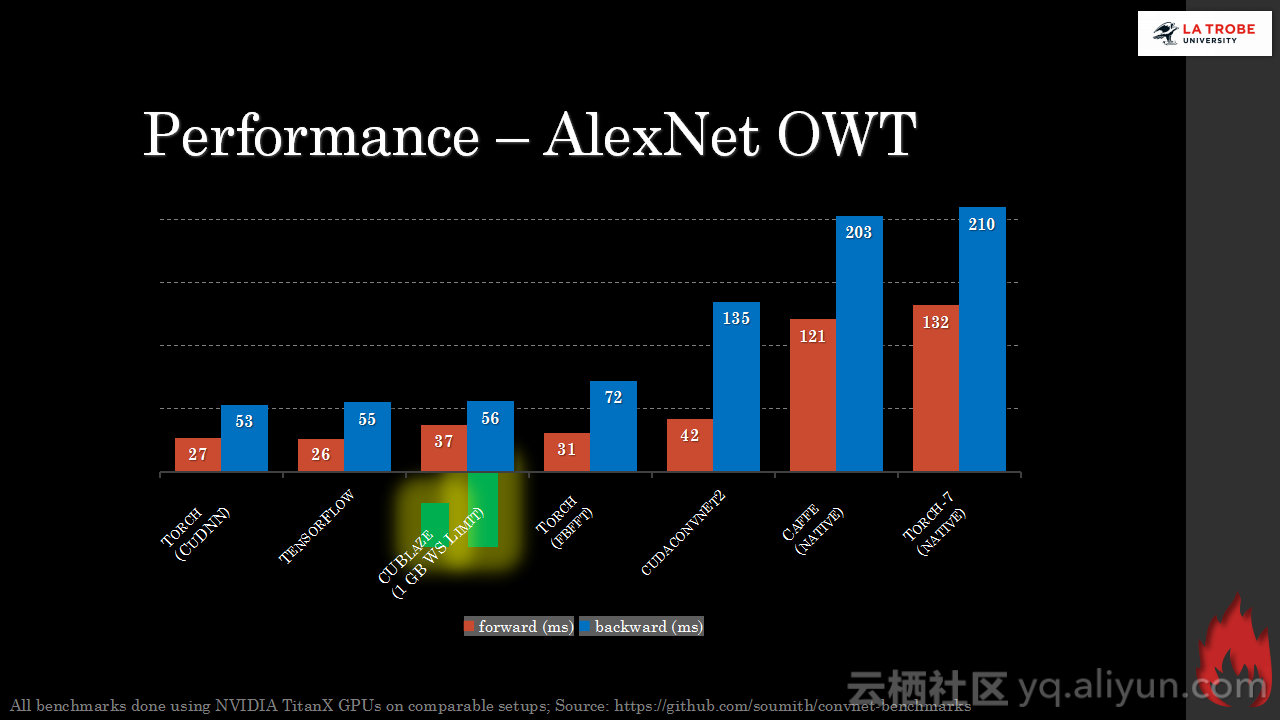
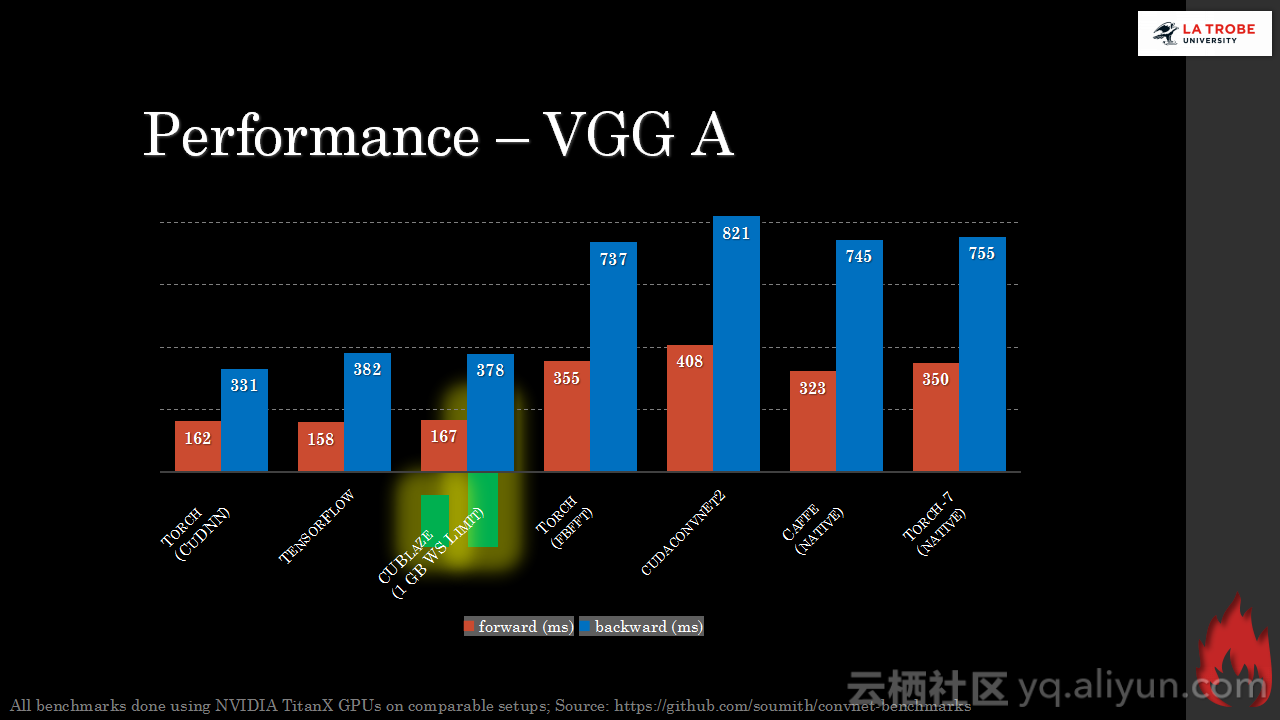
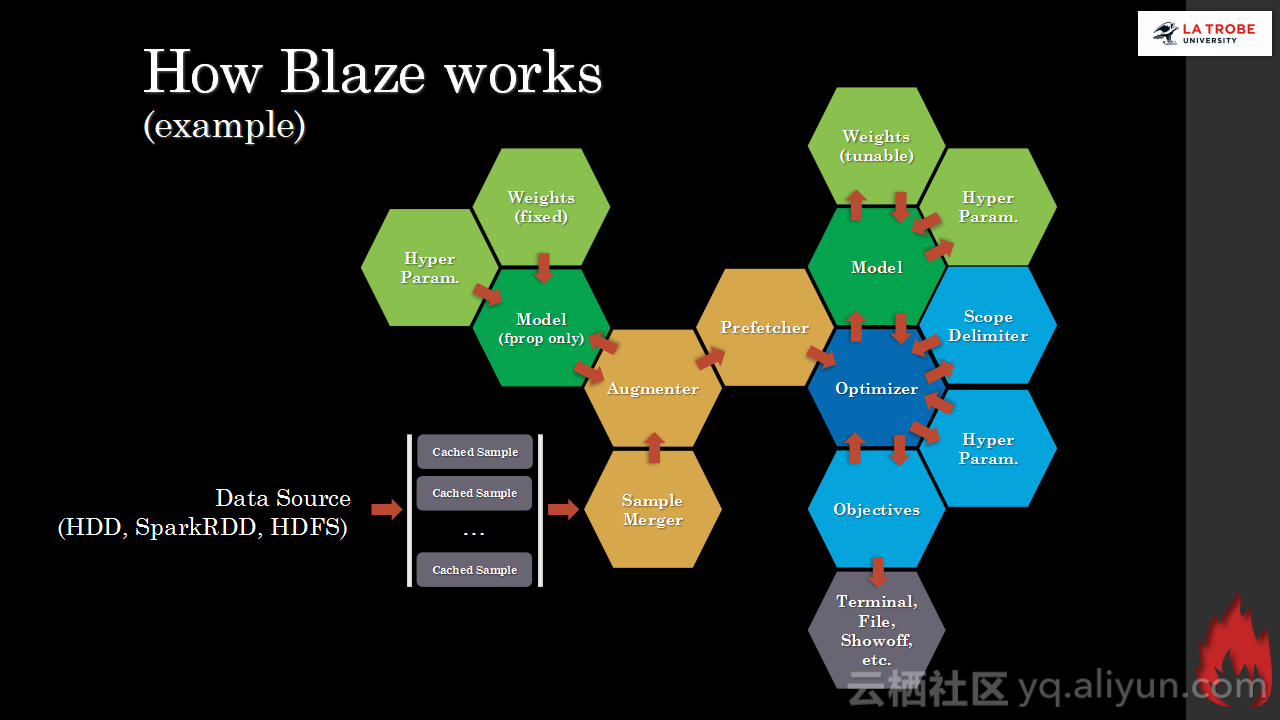
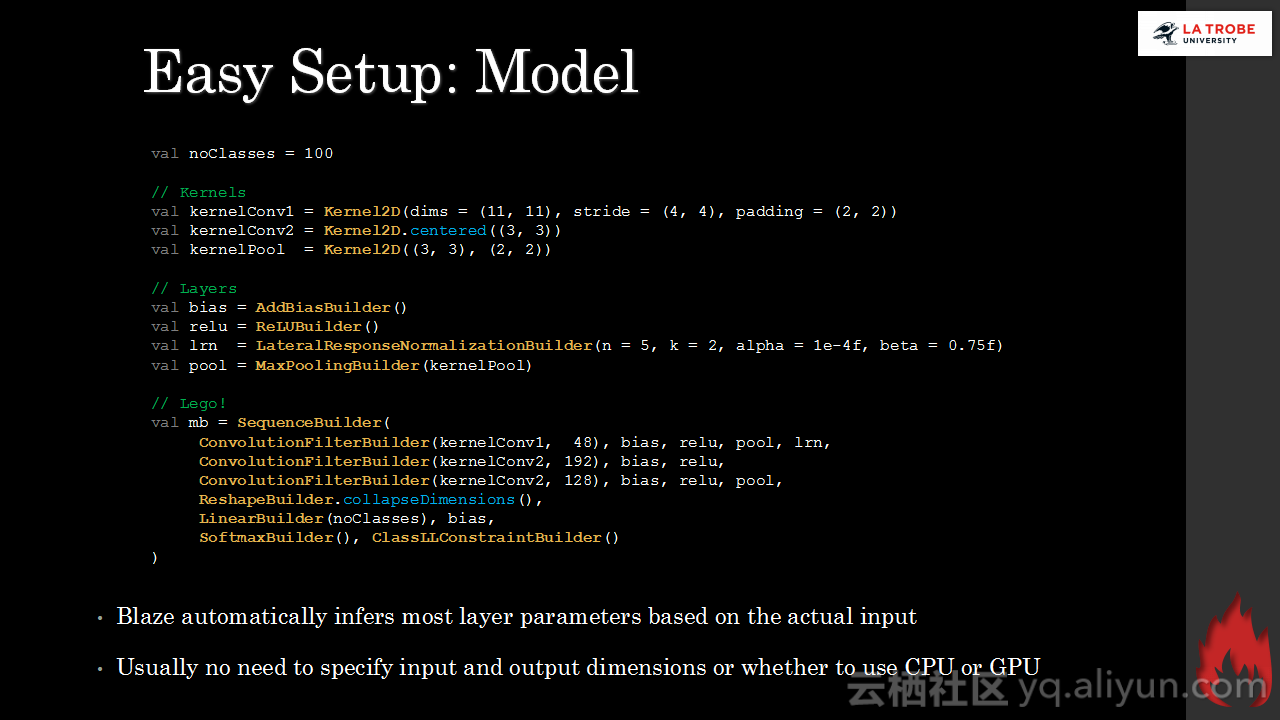
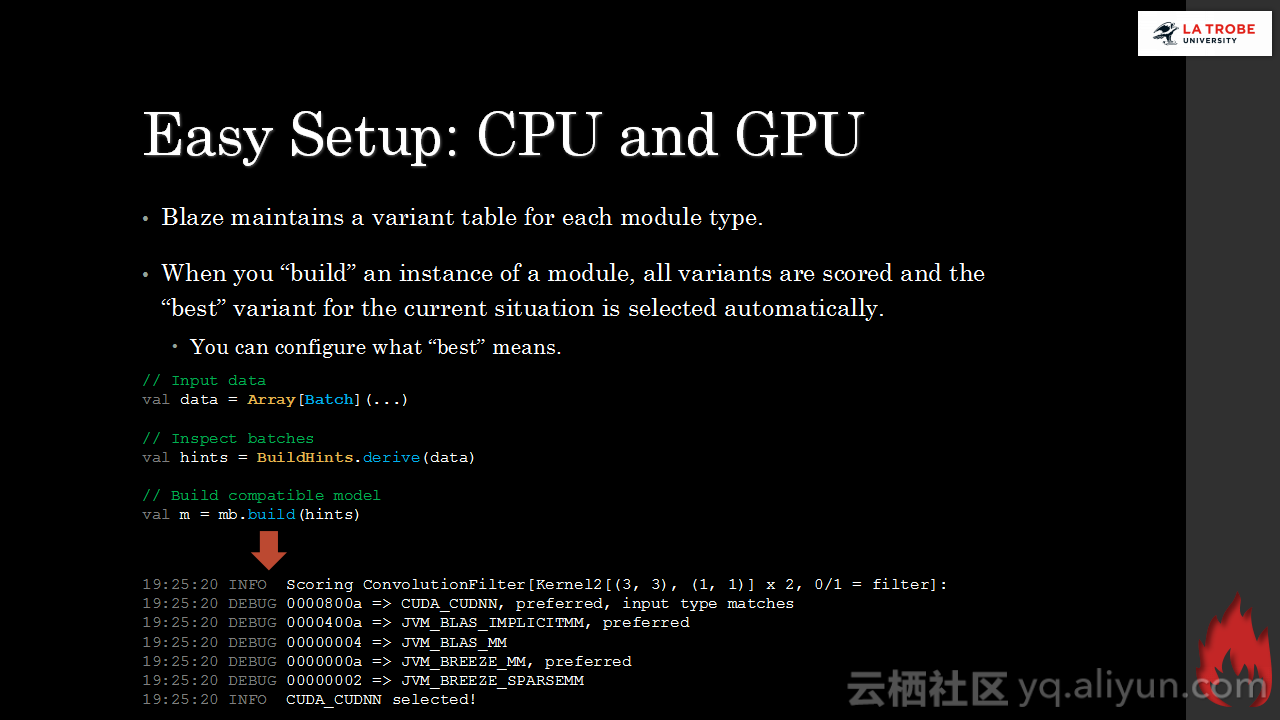


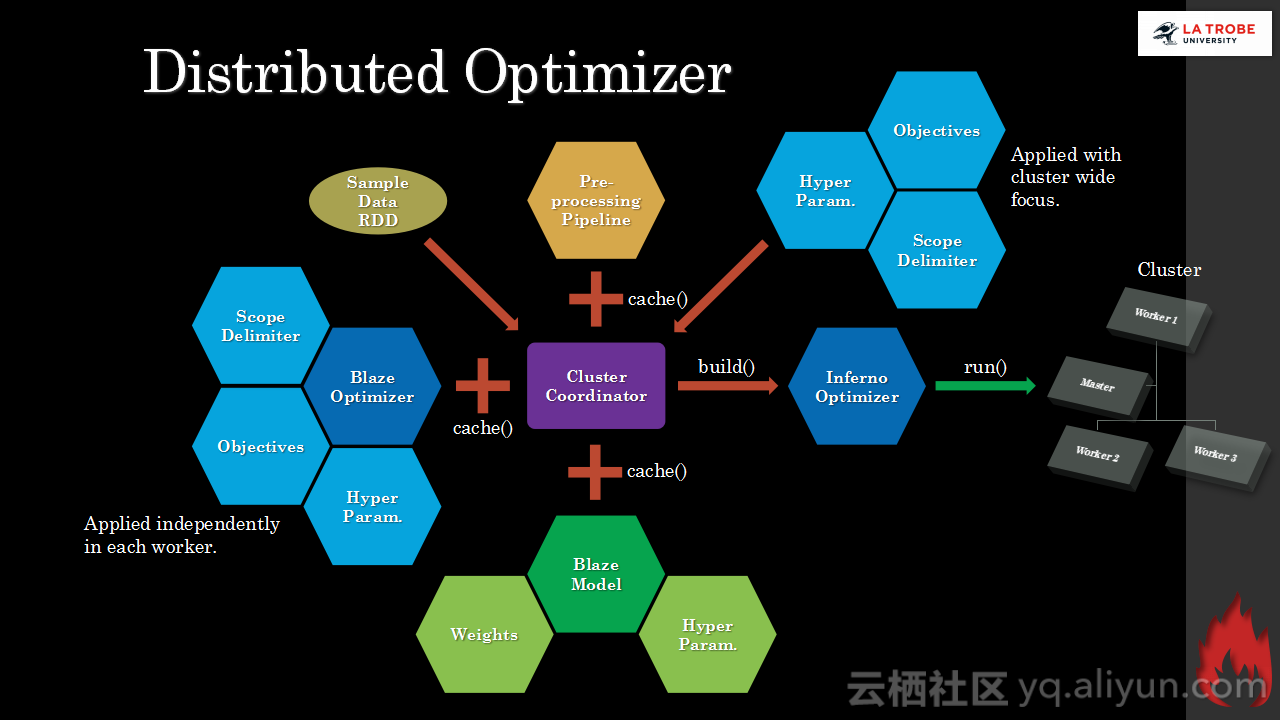
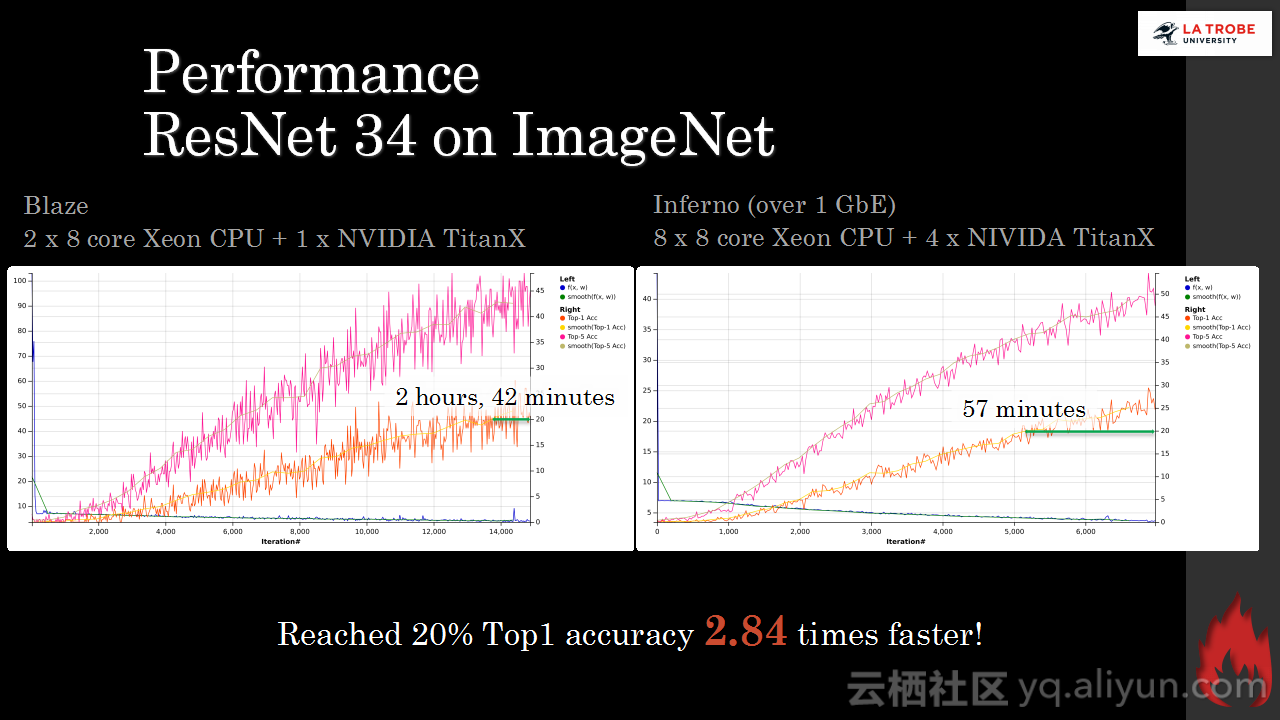
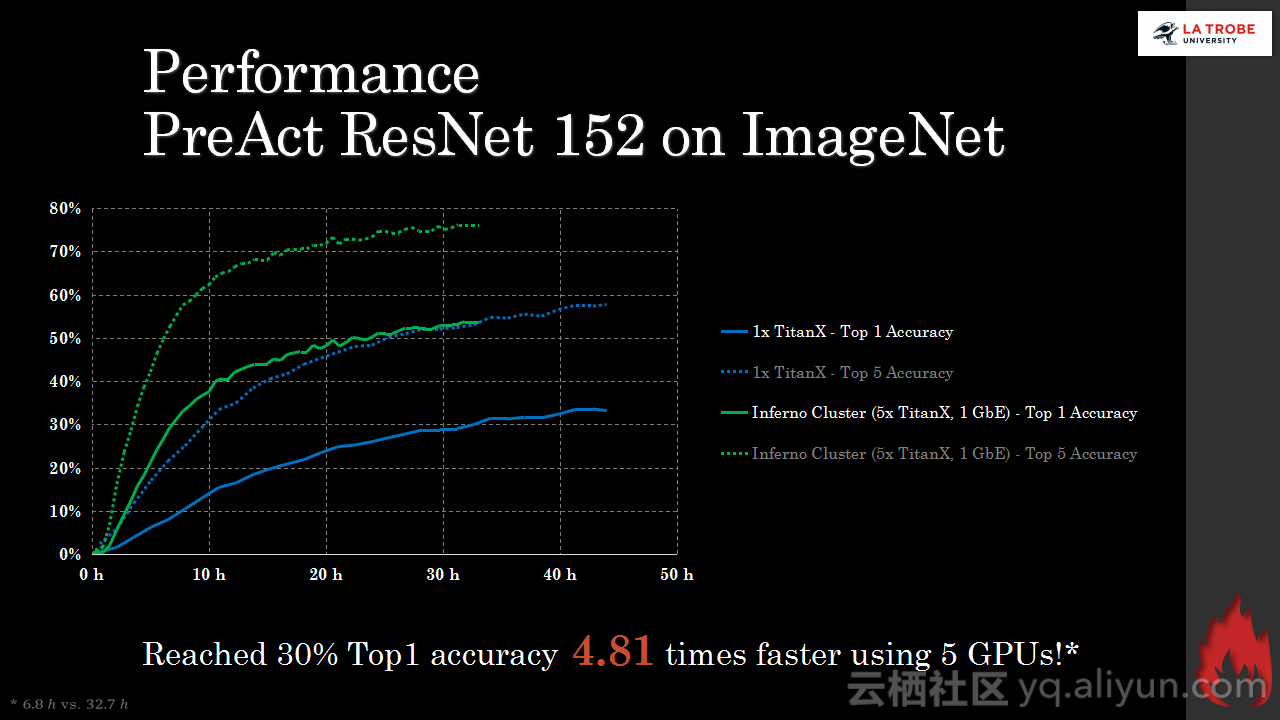



本讲义出自Matthias Langer、Dr. Zhen He与Dr. Zhen He在Hadoop Summit Tokyo 2016上的演讲,主要介绍了深度学习的基本概念和相关知识,分享了Spark与深度学习的关联,并介绍了La Trobe大学的深度学习系统。
