本讲义出自Rafael Coss在Hadoop Summit Tokyo 2016上的演讲,主要介绍了领英的数据赋能之旅,从产品研发的整个生命周期出发分享了数据驱动对于领英的意义,并分享了领英在面对大数据处理分析时遇到的挑战以及解决方案和所使用到工具。

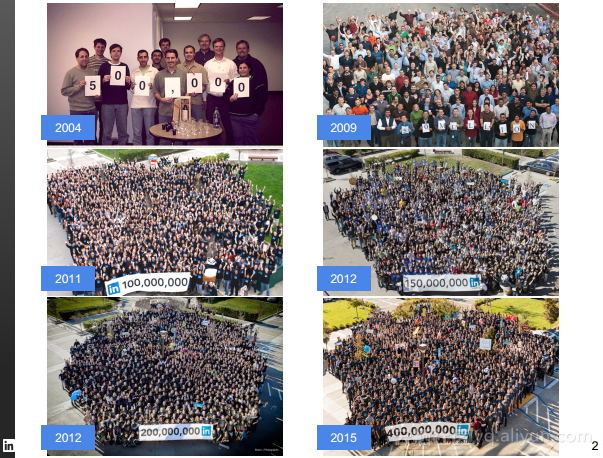
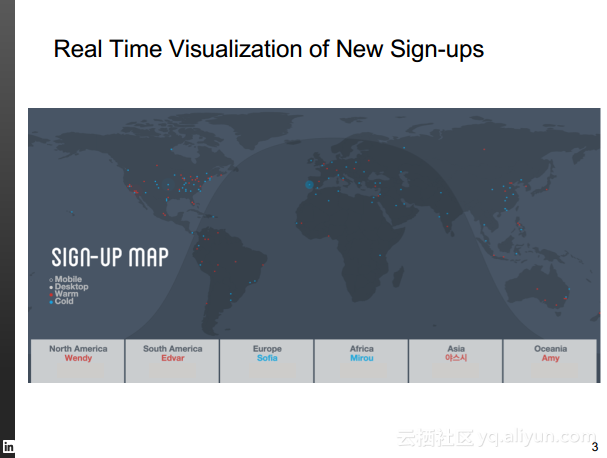
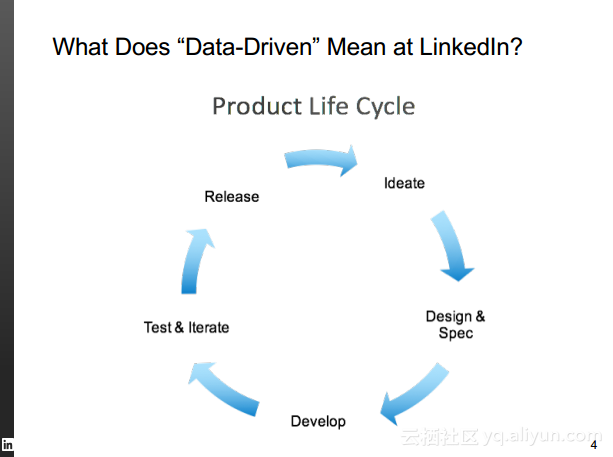
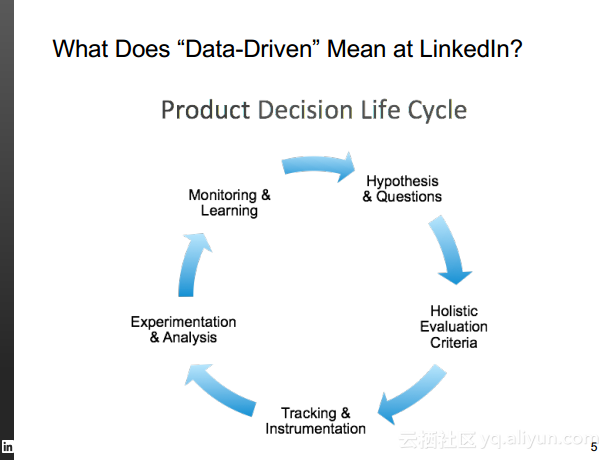
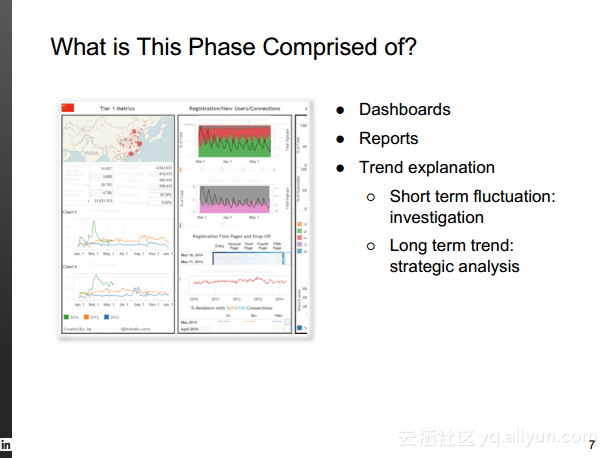

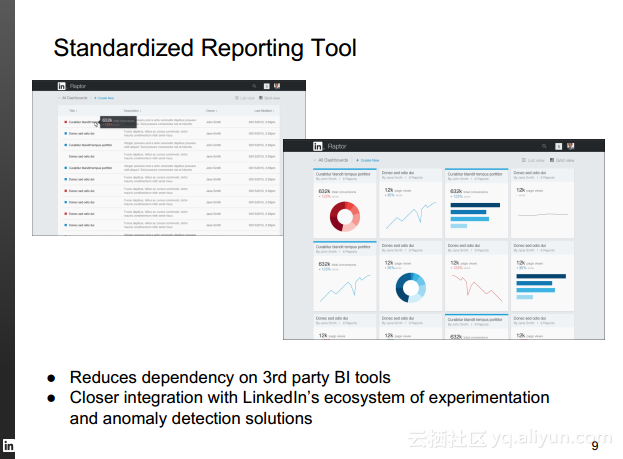
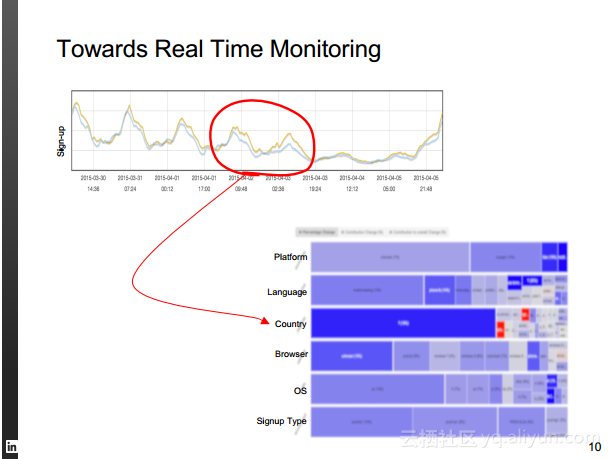


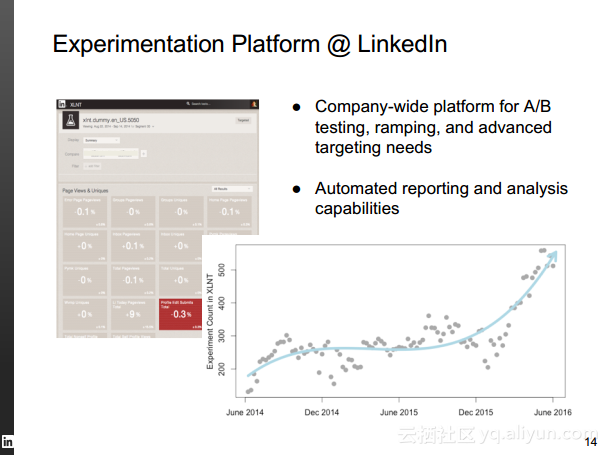

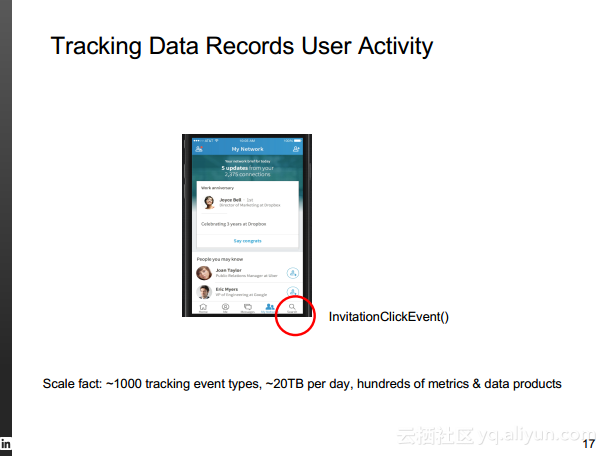
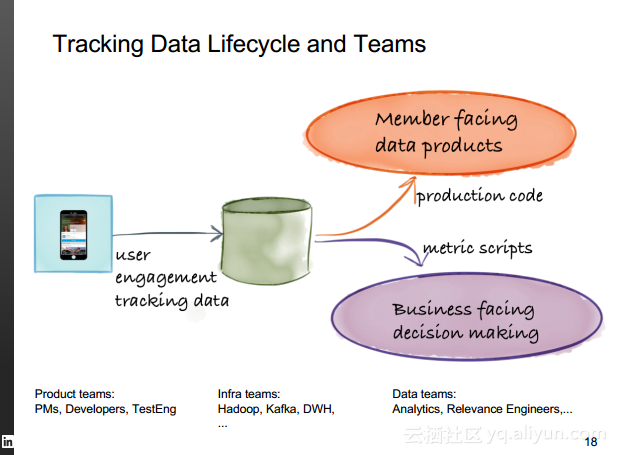
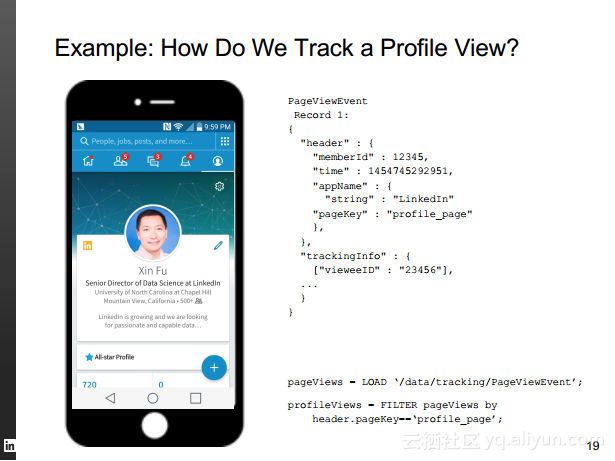
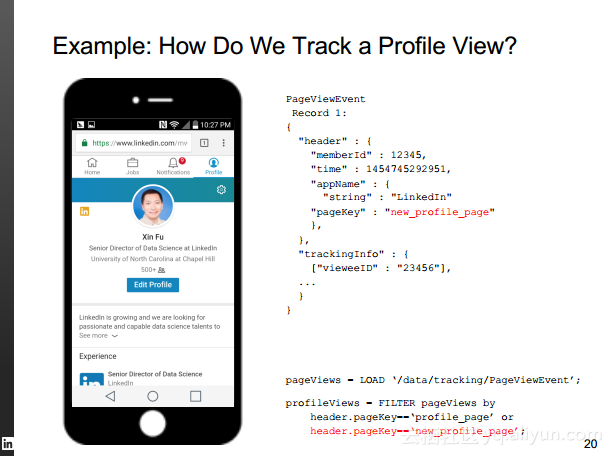

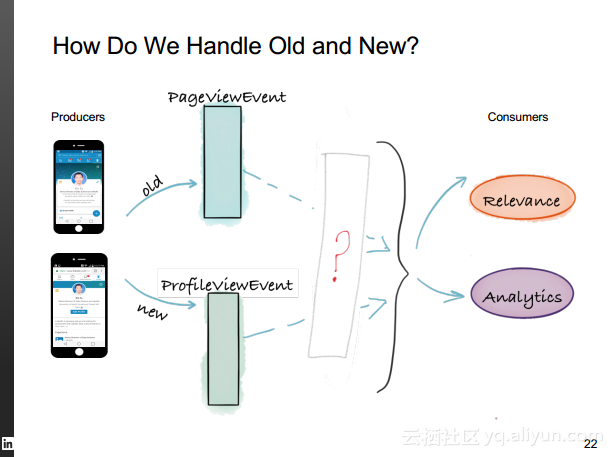

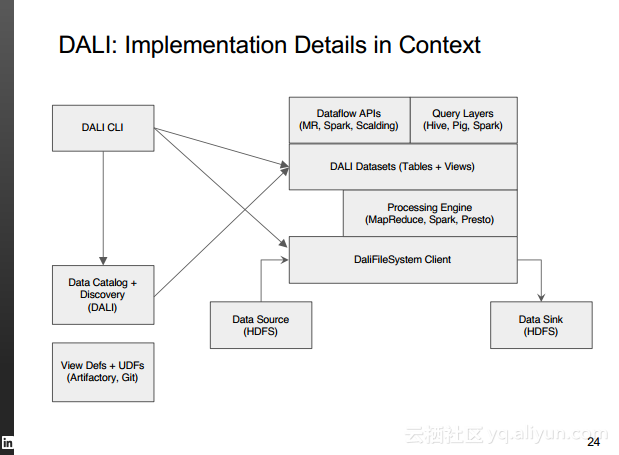
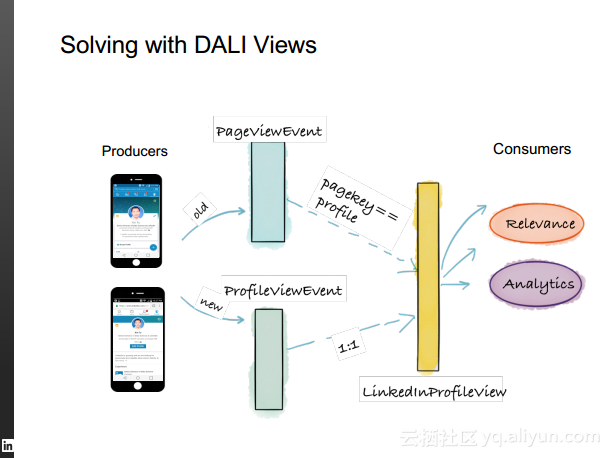

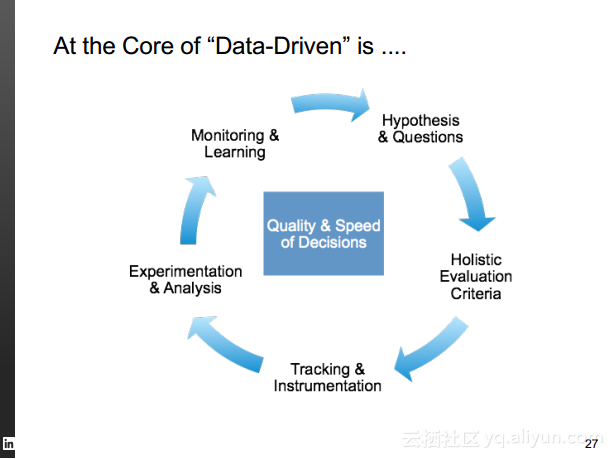





本讲义出自Rafael Coss在Hadoop Summit Tokyo 2016上的演讲,主要介绍了领英的数据赋能之旅,从产品研发的整个生命周期出发分享了数据驱动对于领英的意义,并分享了领英在面对大数据处理分析时遇到的挑战以及解决方案和所使用到工具。
