本讲义出自Alex Lv与Amber Vaidya在Hadoop Summit Tokyo 2016上的演讲,主要分享了构建于Spark和Hadoop上的开源数据质量平台Griffin,Griffin可以用于处理批量数据、实时数据和非结构化的数据,并且构建了统一的过程来检测无效或者不准确等DQ问题,讲义中介绍了eBayGriffin的技术架构、以及用例等。




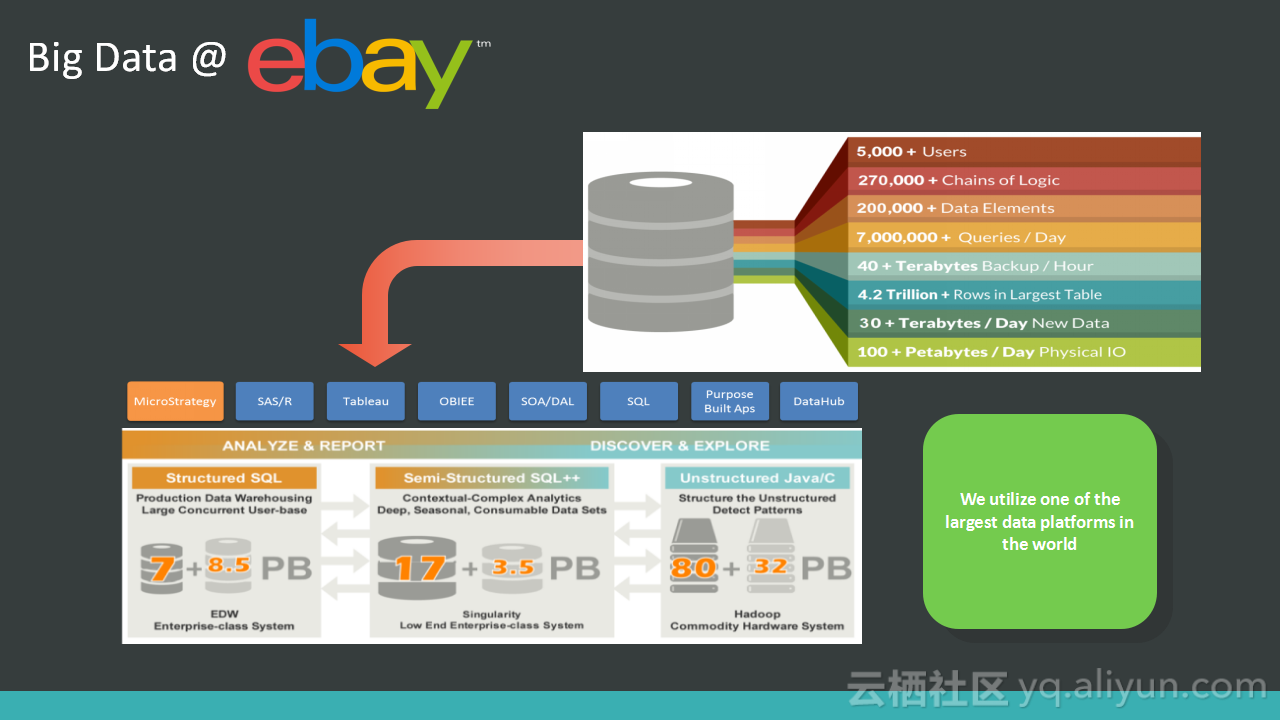



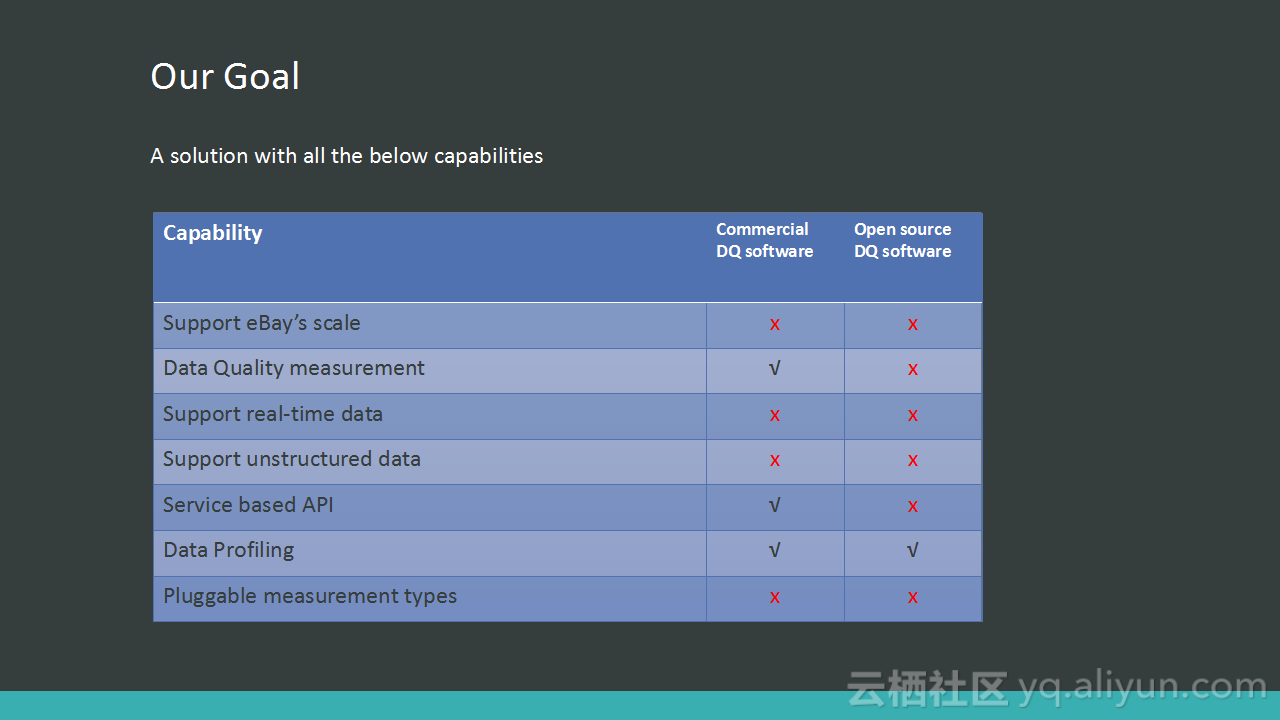


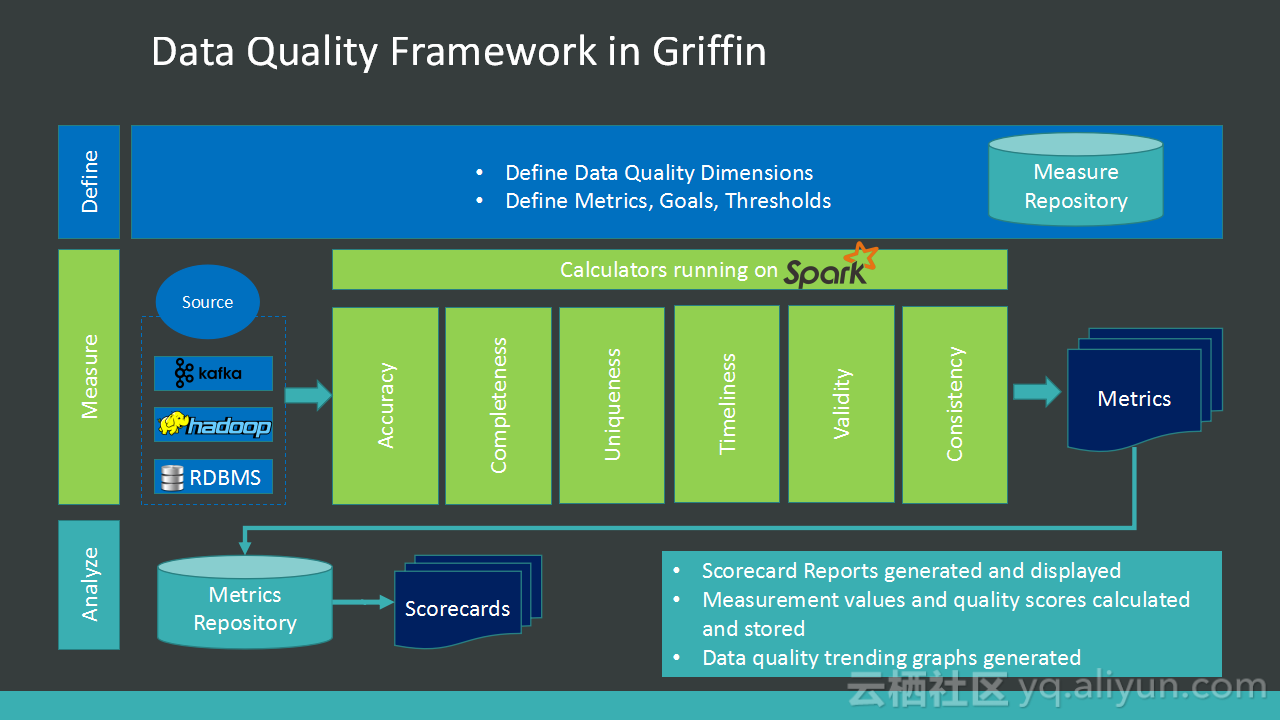

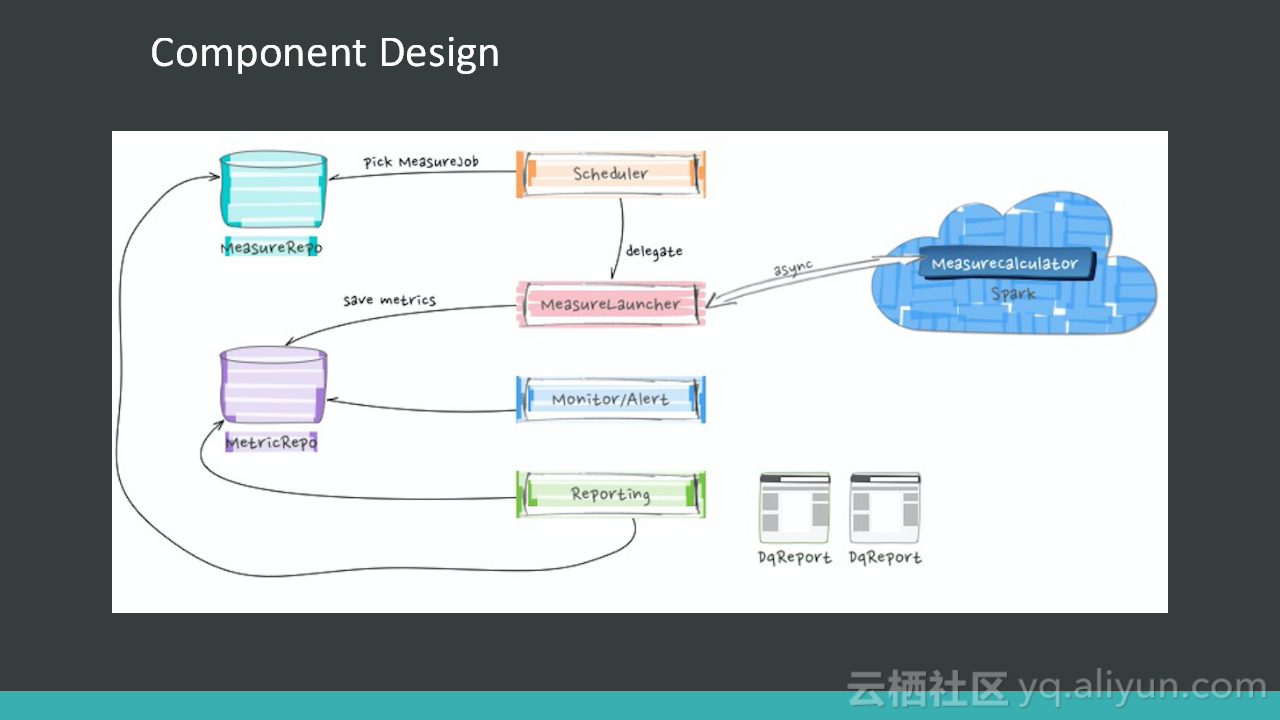
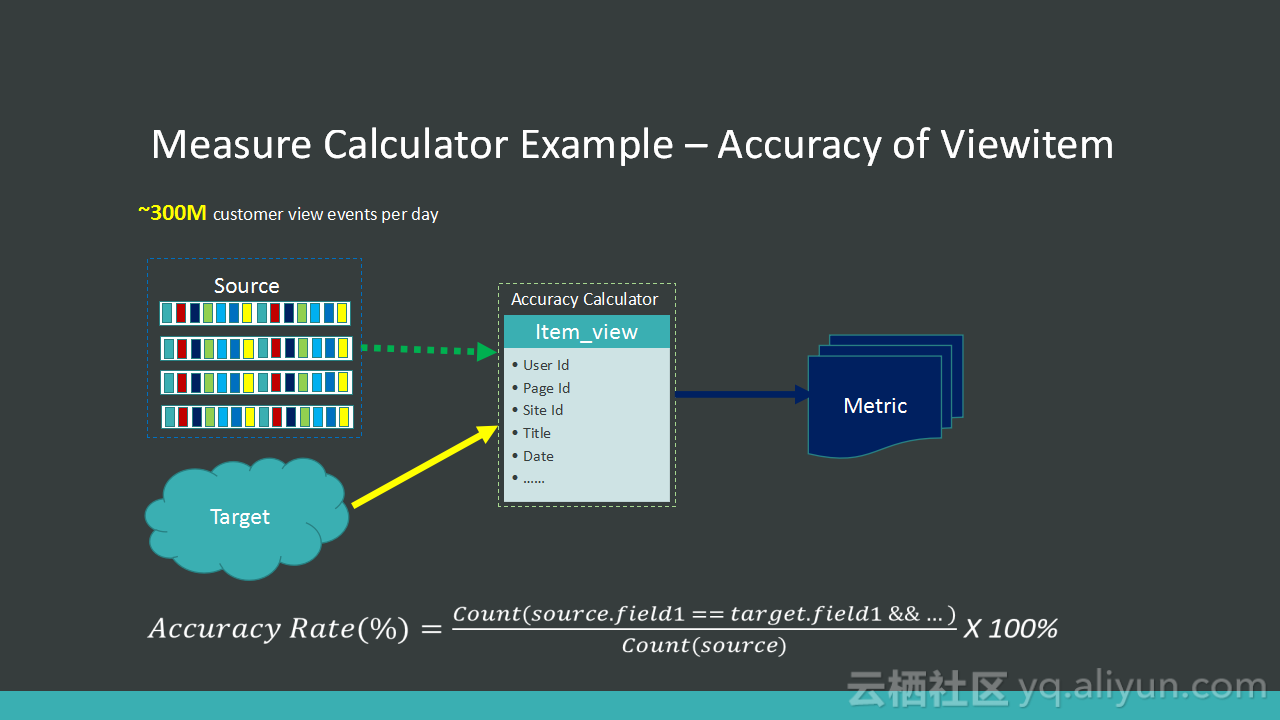




本讲义出自Alex Lv与Amber Vaidya在Hadoop Summit Tokyo 2016上的演讲,主要分享了构建于Spark和Hadoop上的开源数据质量平台Griffin,Griffin可以用于处理批量数据、实时数据和非结构化的数据,并且构建了统一的过程来检测无效或者不准确等DQ问题,讲义中介绍了eBayGriffin的技术架构、以及用例等。
